2 Building blocks
- Using the interactive shell
- Working with variables
- Organizing your code
- Understanding the type system
- Working with operators
- Understanding the runtime
It’s time to start learning about Elixir. This chapter presents the basic building blocks of the language, such as modules, functions, and the type system. This will be a somewhat lengthy, not particularly exciting, tour of language features, but the material presented here is important because it prepares the stage for exploring more interesting, higher-level topics.
Before starting, make sure you’ve installed Elixir version 1.15 and Erlang version 26. There are several ways to install Elixir, and it’s best to follow the instructions from the official Elixir site at https://elixir-lang.org/install.xhtml.
With that out of the way, let’s start our tour of Elixir. The first thing you should know about is the interactive shell.
2.1 The interactive shell
The simplest way to experiment and learn about a language’s features is through the interactive shell. You can start the Elixir interactive shell from the command line by running the iex command:
$ iex Erlang/OTP 26 [erts-14.0] [source] [64-bit] [smp:20:20] [ds:20:20:10] Interactive Elixir (1.15.0) - press Ctrl+C to exit (type h() ENTER for help) iex(1)>
Running iex starts an instance of BEAM and then an interactive Elixir shell inside it. Runtime information is printed, such as the Erlang and Elixir version numbers, and then the prompt is provided, so you can enter Elixir expressions:
iex(1)> 1 + 2 ❶ 3 ❷
After you type an expression, it’s interpreted and executed. Its return value is then printed to the screen.
Note Everything in Elixir is an expression that has a return value. This includes not only function calls but also constructs like if and case.
Tip You’ll use iex extensively throughout the book, especially in the initial chapters. The expression result often won’t be particularly relevant, and it will be omitted to reduce noise. Regardless, keep in mind that each expression returns a result, and when you enter an expression in the shell, its result will be presented.
You can type practically anything that constitutes valid Elixir code, including relatively complicated multiline expressions:
iex(2)> 2 * ( ❶ 3 + 1 ❶ ) / 4 ❷ 2.0
❶ The expression isn’t finished.
❷ The expression is finished, so it’s evaluated.
Notice how the shell doesn’t evaluate the expression until you finish it on the last line. In Elixir, you need no special characters, such as semicolons, to indicate the end of an expression. Instead, a line break indicates the end of an expression, if the expression is complete. Otherwise, the parser waits for additional input until the expression becomes complete. If you get stuck (e.g., if you miss a closing parenthesis), you can abort the entire expression with #iex:break written on a separate line:
iex(3)> 1 + (2 ...(3)> #iex:break ** (TokenMissingError) iex:1: incomplete expression iex(3)>
The quickest way to leave the shell is to press Ctrl-C twice. Doing so brutally kills the OS process and all background jobs that are executing. Because the shell is mostly used for experimenting and shouldn’t be used to run real production systems, it’s usually fine to terminate it this way. But if you want a more polite way of stopping the system, you can invoke System.stop.
Note There are several ways to start Elixir and the Erlang runtime as well as to run your Elixir programs. You’ll learn a bit about all of them by the end of this chapter. In the first part of this book, you’ll mostly work with the iex shell because it’s a simple and efficient way of experimenting with the language.
You can do many things with the shell, but most often, you’ll use it to enter expressions and inspect their results. You can research for yourself what else can be done in the shell. Basic help can be obtained with the h command:
iex(3)> h
Entering this in the shell will output an entire screen of iex-related instructions. You can also look for the documentation of the IEx module, which is responsible for the shell’s workings:
iex(4)> h IEx
You can find the same help in the online documentation at https://hexdocs.pm/iex.
Now that you have a basic tool with which to experiment, you are ready to research the features of the language. You’ll start with variables.
2.2 Working with variables
Elixir is a dynamic programming language, which means you don’t explicitly declare a variable or its type. Instead, the variable type is determined by whatever data it contains at the moment. In Elixir terms, assignment is called binding. When you initialize a variable with a value, the variable is bound to that value:
iex(1)> monthly_salary = 10000 ❶ 10000 ❷
❷ The result of the last expression
Each expression in Elixir has a result. In the case of the = operator, the result is whatever is on the right side of the operator. After the expression is evaluated, the shell prints this result to the screen.
Now, you can reference the variable:
iex(2)> monthly_salary ❶ 10000 ❷
❶ The expression that returns the value of the variable
The variable can, of course, be used in complex expressions:
iex(3)> monthly_salary * 12 120000
In Elixir, a variable name always starts with a lowercase alphabetic character or an underscore. After that, any combination of alphanumeric characters and underscores is allowed. The prevalent convention is to use only lowercase ASCII letters, digits, and underscores:
valid_variable_name also_valid_1 validButNotRecommended NotValid
Variable names can also end with the question mark (?) or exclamation mark (!) characters:
valid_name? also_ok!
Variables can be rebound to a different value:
iex(1)> monthly_salary = 10000 ❶ 10000 iex(2)> monthly_salary ❷ 10000 iex(3)> monthly_salary = 11000 ❸ 11000 iex(4)> monthly_salary ❹ 11000
❹ Verifies the effect of rebinding
Rebinding doesn’t mutate the existing memory location. It reserves new memory and reassigns the symbolic name to the new location.
Note You should always keep in mind that data is immutable. Once a memory location is occupied with data, it can’t be modified until it’s released. But variables can be rebound, which makes them point to a different memory location. Thus, variables are mutable, but the data they point to is immutable.
Elixir is a garbage-collected language, which means you don’t have to manually release memory. When a variable goes out of scope, the corresponding memory is eligible for garbage collection and will be released sometime in the future, when the garbage collector cleans up the memory.
2.3 Organizing your code
Being a functional language, Elixir relies heavily on functions. Due to the immutable nature of the data, a typical Elixir program consists of many small functions. You’ll witness this in chapters 3 and 4, as you start using some typical functional idioms. Multiple functions can be further organized into modules.
2.3.1 Modules
A module is a collection of functions, somewhat like a namespace. Every Elixir function must be defined inside a module.
Elixir comes with a standard library that provides many useful modules. For example, the IO module can be used to complete various I/O operations. The puts function from the IO module can be used to print a message to the screen:
iex(1)> IO.puts("Hello World!") ❶
Hello World! ❷
:ok ❸
❶ Calls the puts function of the IO module
❷ The IO.puts function prints to the screen.
As you can see in the example, to call a function of a module you use the syntax ModuleName.function_name(args).
To define your own module, you use the defmodule expression. Inside the module, you define functions using the def expression. Listing 2.1 demonstrates the definition of a module.
Listing 2.1 Defining a module (geometry.ex)
defmodule Geometry do ❶ def rectangle_area(a, b) do ❷ a * b ❷ end ❷ end ❸
There are two ways you can use this module. First, you can copy and paste this definition directly into iex—as mentioned, almost anything can be typed into the shell. A second way is to tell iex to interpret the file while starting:
$ iex geometry.ex
Using either method yields the same effect. The code is compiled, and the resulting module is loaded into the runtime and can be used from the shell session. Let’s try it:
$ iex geometry.ex iex(1)> Geometry.rectangle_area(6, 7) ❶ 42 ❷
That was simple! You created a Geometry module, loaded it into a shell session, and used it to compute the area of a rectangle.
Note As you may have noticed, the filename has the .ex extension. This is a common convention for Elixir source files.
In the source code, a module must be defined in a single file. A single file may contain several module definitions:
defmodule Module1 do ... end defmodule Module2 do ... end
A module name must follow certain rules. It starts with an uppercase letter and is usually written in camel case style. A module name can consist of alphanumeric characters, underscores, and the dot (.) character. Dots are often used to organize modules hierarchically:
defmodule Geometry.Rectangle do ... end defmodule Geometry.Circle do ... end
You can also nest module definitions:
defmodule Geometry do
defmodule Rectangle do
...
end
...
end
The inner module can be referenced with Geometry.Rectangle.
Note that there is nothing special about the dot character. It’s just one of the allowed characters in a module name. The compiled version doesn’t record any hierarchical relations between the modules.
This is typically used to organize the modules in some meaningful hierarchy that is easier to navigate when reading the code. Additionally, this informal scoping can eliminate possible name clashes. For example, consider two libraries, one implementing a JSON encoder and another implementing an XML encoder. If both libraries defined the module called Encoder, you couldn’t use them both in the same project. However, if the modules are called Json.Encoder and Xml.Encoder, then the name clash is avoided. For this reason, it’s customary to add some common prefix to all module names in a project. Usually, the application or library name is used for this purpose.
2.3.2 Functions
A function must always be a part of a module. Function names follow the same conventions as variables: they start with a lowercase letter or underscore character and are followed by a combination of alphanumerics and underscores.
As with variables, function names can end with the ? and ! characters. The ? character is often used to indicate a function that returns either true or false. Placing the ! character at the end of the name indicates a function that may raise a runtime error. Both of these are conventions, rather than rules, but it’s best to follow them and respect the community style.
Functions can be defined using the def macro:
defmodule Geometry do def rectangle_area(a, b) do ❶ ... ❷ end end
The definition starts with the def expression and is followed by the function name, argument list, and body enclosed in a do...end block. Because you’re dealing with a dynamic language, there are no type specifications for arguments.
Note Notice that defmodule and def aren’t referred to as keywords. That’s because they’re not! Instead, these are examples of Elixir macros. You don’t need to worry about how this works yet; it’s explained a bit later in this chapter. If it helps, you can think of def and defmodule as keywords, but be aware this isn’t exactly true.
If a function has no arguments, you can omit the parentheses:
defmodule Program do
def run do
...
end
end
What about the return value? Recall that in Elixir, everything that has a return value is an expression. The return value of a function is the return value of its last expression. There’s no explicit return in Elixir.
Note Given that there’s no explicit return, you might wonder how complex functions work. This will be covered in detail in chapter 3, where you’ll learn about branching and conditional logic. The general rule is to keep functions short and simple, which makes it easy to compute the result and return it from the last expression.
You saw an example of returning a value in listing 2.1, but let’s repeat it here:
defmodule Geometry do
def rectangle_area(a, b) do
a * b ❶
end
end
❶ Calculates the area and returns the result
You can now verify this. Start the shell again, and then try the rectangle_area function:
$ iex geometry.ex iex(1)> Geometry.rectangle_area(3, 2) ❶ 6 ❷
If a function body consists of a single expression, you can use a condensed form and define it in a single line:
defmodule Geometry do def rectangle_area(a, b), do: a * b end
To call a function defined in another module, use the module name followed by the function name:
iex(1)> Geometry.rectangle_area(3, 2) 6
Of course, you can always store the function result to a variable:
iex(2)> area = Geometry.rectangle_area(3, 2) ❶ 6 iex(3)> area ❷ 6
❶ Calls the function and stores its result
❷ Verifies the variable content
Parentheses are optional in Elixir, so you can omit them:
iex(4)> Geometry.rectangle_area 3, 2 6
Personally, I find that omitting parentheses makes the code ambiguous, so my advice is to always include them when calling a function.
If a function being called resides in the same module, you can omit the module prefix:
defmodule Geometry do
def rectangle_area(a, b) do
a * b
end
def square_area(a) do
rectangle_area(a, a) ❶
end
end
❶ Calls to a function in the same module
Given that Elixir is a functional language, you’ll often need to combine functions, passing the result of one function as the argument to the next one. Elixir comes with a built-in operator, |>, called the pipe operator, that does exactly this:
iex(5)> -5 |> abs() |> Integer.to_string() |> IO.puts() 5
This code is transformed at compile time into the following:
iex(6)> IO.puts(Integer.to_string(abs(-5))) 5
More generally, the pipe operator places the result of the previous call as the first argument of the next call. So the following code
prev(arg1, arg2) |> next(arg3, arg4)
is translated at compile time to this:
next(prev(arg1, arg2), arg3, arg4)
Arguably, the pipeline version is more readable because the sequence of execution is read from left to right. The pipe operator looks especially elegant in source files, where you can lay out the pipeline over multiple lines:
-5 ❶ |> abs() ❷ |> Integer.to_string() ❸ |> IO.puts() ❹
2.3.3 Function arity
Arity describes the number of arguments a function receives. A function is uniquely identified by its containing module, name, and arity. Take a look at the following function:
defmodule Rectangle do
def area(a, b) do ❶
...
end
end
The function Rectangle.area receives two arguments, so it’s said to be a function of arity 2. In the Elixir world, this function is often called Rectangle.area/2, where /2 denotes the function’s arity.
Why is this important? Because two functions with the same name but different arities are two different functions, as the following example demonstrates.
Listing 2.2 Functions with the same name but different arities (arity_demo.ex)
defmodule Rectangle do def area(a), do: area(a, a) ❶ def area(a, b), do: a * b ❷ end
Load this module into the shell, and try the following:
iex(1)> Rectangle.area(5) 25 iex(2)> Rectangle.area(5,6) 30
As you can see, these two functions act completely differently. The name might be overloaded, but the arities differ, so we talk about them as two distinct functions, each with its own implementation.
It usually makes no sense for different functions with the same name to have completely different implementations. More commonly, a lower-arity function delegates to a higher-arity function, providing some default arguments. This is what happens in listing 2.2, where Rectangle.area/1 delegates to Rectangle.area/2 .
Let’s look at another example.
Listing 2.3 Same-name functions, different arities, and default params (arity_calc.ex)
defmodule Calculator do def add(a), do: add(a, 0) ❶ def add(a, b), do: a + b ❷ end
❶ Calculator.add/1 delegates to Calculator.add/2.
❷ Calculator.add/2 contains the implementation.
Again, a lower-arity function is implemented in terms of a higher-arity one. This pattern is so frequent that Elixir allows you to specify defaults for arguments by using the \\ operator followed by the argument’s default value:
defmodule Calculator do
def add(a, b \\ 0), do: a + b ❶
end
❶ Defining a default value for argument b
This definition generates two functions exactly as in listing 2.3.
You can set the defaults for any combination of arguments:
defmodule MyModule do
def fun(a, b \\ 1, c, d \\ 2) do ❶
a + b + c + d
end
end
❶ Setting defaults for multiple arguments
Always keep in mind that default values generate multiple functions of the same name with different arities. The previous code generates three functions, MyModule.fun/2, MyModule.fun/3, and MyModule.fun/4, with the following implementations:
def fun(a, c), do: fun(a, 1, c, 2) def fun(a, b, c), do: fun(a, b, c, 2) def fun(a, b, c, d), do: a + b + c + d
Because arity distinguishes multiple functions of the same name, it’s not possible to have a function accept a variable number of arguments. There’s no counterpart of C’s ... or JavaScript’s arguments.
2.3.4 Function visibility
When you define a function using the def macro, the function is made public—it can be called by anyone else. In Elixir terminology, it’s said that the function is exported. You can also use the defp macro to make the function private. A private function can be used only inside the module it’s defined in. The following example demonstrates this.
Listing 2.4 A module with a public and a private function (private_fun.ex)
defmodule TestPrivate do def double(a) do ❶ sum(a, a) ❷ end defp sum(a, b) do ❸ a + b end end
The module TestPrivate defines two functions. The function double is exported and can be called from outside. Internally, it relies on the private function sum to do its work.
Let’s try this in the shell. Load the module, and do the following:
iex(1)> TestPrivate.double(3) 6 iex(2)> TestPrivate.sum(3, 4) ** (UndefinedFunctionError) function TestPrivate.sum/2 ...
As you can see, the private function can’t be invoked outside the module.
2.3.5 Imports and aliases
Calling functions from another module can sometimes be cumbersome because you need to reference the module name. If your module often calls functions from another module, you can import that other module into your own. Importing a module allows you to call its public functions without prefixing them with the module name:
defmodule MyModule do import IO ❶ def my_function do puts "Calling imported function." ❷ end end
❷ You can use puts instead of IO.puts.
Of course, you can import multiple modules. In fact, the standard library’s Kernel module is automatically imported into every module. Kernel contains functions that are often used, so automatic importing makes them easier to access.
Note You can see what functions are available in the Kernel module by looking in the online documentation at https://hexdocs.pm/elixir/Kernel.xhtml.
Another expression, alias, makes it possible to reference a module under a different name:
defmodule MyModule do alias IO, as: MyIO ❶ def my_function do MyIO.puts("Calling imported function.") ❷ end end
❷ Calls a function using the alias
Aliases can be useful if a module has a long name. For example, if your application is heavily divided into a deeper module hierarchy, it can be cumbersome to reference modules via fully qualified names. Aliases can help with this. For example, let’s say you have a Geometry.Rectangle module. You can alias it in your client module and use a shorter name:
defmodule MyModule do alias Geometry.Rectangle, as: Rectangle ❶ def my_function do Rectangle.area(...) ❷ end end
❶ Sets up an alias to a module
❷ Calls a module function using the alias
In the preceding example, the alias of Geometry.Rectangle is the last part in its name. This is the most common use of alias, so Elixir allows you to skip the as option in this case:
defmodule MyModule do alias Geometry.Rectangle ❶ def my_function do Rectangle.area(...) ❷ end end
❶ Sets up an alias to a module
❷ Calls a module function using the alias
Aliases can help you reduce some noise, especially if you call functions from a long-named module many times.
2.3.6 Module attributes
The purpose of module attributes is twofold: they can be used as compile-time constants, and you can register any attribute, which can then be queried at run time. Let’s look at an example.
The following module provides basic functions for working with circles:
iex(1)> defmodule Circle do
@pi 3.14159 ❶
def area(r), do: r*r*@pi ❷
def circumference(r), do: 2*r*@pi
end
iex(2)> Circle.area(1)
3.14159
iex(3)> Circle.circumference(1)
6.28318
Notice how you define a module directly in the shell. This is permitted and makes it possible to experiment without storing any files on disk.
The important thing about the @pi constant is that it exists only during the compilation of the module, when the references to it are inlined.
Moreover, an attribute can be registered, which means it will be stored in the generated binary and can be accessed at run time. Elixir registers some module attributes by default. For example, the attributes @moduledoc and @doc can be used to provide documentation for modules and functions:
defmodule Circle do @moduledoc "Implements basic circle functions" @pi 3.14159 @doc "Computes the area of a circle" def area(r), do: r*r*@pi @doc "Computes the circumference of a circle" def circumference(r), do: 2*r*@pi end
To try this, however, you need to generate a compiled file. Here’s a quick way to do it. Save this code to the circle.ex file somewhere, and then run elixirc circle.ex. This will generate the file Elixir.Circle.beam. Next, start the iex shell from the same folder. You can now retrieve the attribute at run time:
iex(1)> Code.fetch_docs(Circle)
{:docs_v1, 2, :elixir, "text/markdown",
%{"en" => "Implements basic circle functions"}, %{},
[
{{:function, :area, 1}, 5, ["area(r)"],
%{"en" => "Computes the area of a circle"}, %{}},
{{:function, :circumference, 1}, 8, ["circumference(r)"],
%{"en" => "Computes the circumference of a circle"}, %{}}
]}
Notably, other tools from the Elixir ecosystem know how to work with these attributes. For example, you can use the help feature of iex to see the module’s documentation:
iex(2)> h Circle ❶ Circle Implements basic circle functions iex(3)> h Circle.area ❷ def area(r) Computes the area of a circle
Furthermore, you can use the ex_doc tool (see https://hexdocs.pm/ex_doc) to generate HTML documentation for your project. This is the way Elixir documentation is produced, and if you plan to build more complex projects, especially something that will be used by many different clients, you should consider using @moduledoc and @doc.
The underlying point is that registered attributes can be used to attach meta information to a module, which can then be used by other Elixir (and even Erlang) tools. There are many other preregistered attributes, and you can also register your own custom attributes. Take a look at the documentation for the Module module (https://hexdocs.pm/elixir/Module.xhtml) for more details.
Type specifications (often called typespecs) are another important feature based on attributes. These allow you to provide type information for your functions, which can later be analyzed with a static analysis tool called dialyzer (https://www.erlang.org/doc/man/dialyzer.xhtml).
Here’s how we can extend the Circle module to include typespecs:
defmodule Circle do @pi 3.14159 @spec area(number) :: number ❶ def area(r), do: r*r*@pi @spec circumference(number) :: number ❷ def circumference(r), do: 2*r*@pi end
❶ Type specification for area/1
❷ Type specification for circumference/1
Here, you use the @spec attribute to indicate that both functions accept and return a number.
Typespecs provide a way to compensate for the lack of a static type system. This can be useful in conjunction with the dialyzer tool to perform static analysis of your programs. Furthermore, typespecs allow you to better document your functions. Remember that Elixir is a dynamic language, so function inputs and outputs can’t be easily deduced by looking at the function’s signature. Typespecs can help significantly with this, and I can attest that it’s much easier to understand someone else’s code when typespecs are provided.
For example, look at the typespec for the Elixir function List.insert_at/3:
@spec insert_at(list, integer, any) :: list
Even without looking at the code or reading the docs, you can reasonably guess that this function inserts a term of any type (third argument) to a list (first argument) at a given position (second argument) and returns a new list.
You won’t be using typespecs in this book, mostly to keep the code as short as possible. But if you plan to build more complex systems, my advice is to seriously consider using typespecs. You can find a detailed reference in the official docs at https://hexdocs.pm/elixir/typespecs.xhtml.
2.3.7 Comments
Comments in Elixir start with the # character, which indicates that the rest of the line is a comment:
# This is a comment a = 3.14 # so is this
Block comments aren’t supported. If you need to comment multiple lines, prefix each one with the # character.
At this point, we’re done with the basics of functions and modules. You’re now aware of the primary code-organization techniques. With that out of our way, it’s time to look at the Elixir type system.
2.4 Understanding the type system
At its core, Elixir uses the Erlang type system. Consequently, integration with Erlang libraries is usually simple. The type system itself is reasonably simple, but if you’re coming from a classical object-oriented language, you’ll find it significantly different from what you’re used to. This section covers basic Elixir types and discusses some implications of immutability. To begin, let’s look at numbers.
2.4.1 Numbers
Numbers can be integers or floats, and they work mostly as you’d expect:
iex(1)> 3 ❶ 3 iex(2)> 0xFF ❷ 255 iex(3)> 3.14 ❸ 3.14 iex(4)> 1.0e-2 ❹ 0.01
Standard arithmetic operators are supported:
iex(5)> 1 + 2 * 3 7
The division operator / works differently than you might expect. It always returns a float value:
iex(6)> 4/2 2.0 iex(7)> 3/2 1.5
To perform integer division or calculate the remainder, you can use auto-imported Kernel functions:
iex(8)> div(5,2) 2 iex(9)> rem(5,2) 1
To add syntactic sugar, you can use the underscore character as a visual delimiter:
iex(10)> 1_000_000 1000000
There’s no upper limit on an integer’s size, and you can use arbitrarily large numbers:
iex(11)> 999999999999999999999999999999999999999999999999999999999999 999999999999999999999999999999999999999999999999999999999999
If you’re worried about memory size, it’s best to consult the official Erlang memory guide at http://mng.bz/QREv. An integer takes up as much space as needed to accommodate the number, whereas a float occupies either 32 or 64 bits, depending on the build architecture of the virtual machine. Floats are internally represented in IEEE 754-1985 (binary precision) format.
2.4.2 Atoms
Atoms are literally named constants. They’re similar to symbols in Ruby or enumerations in C/C++. Atom constants start with a colon character followed by a combination of alphanumerics and/or underscore characters:
:an_atom :another_atom
It’s possible to use spaces in the atom name with the following syntax:
:"an atom with spaces"
An atom consists of two parts: the text and the value. The atom text is whatever you put after the colon character. At run time, this text is kept in the atom table. The value is the data that goes into the variable, and it’s merely a reference to the atom table.
This is exactly why atoms are best used for named constants. They’re efficient in both memory and performance. When you say
variable = :some_atom
the variable doesn’t contain the entire text—only a reference to the atom table. Therefore, memory consumption is low, the comparisons are fast, and the code is still readable.
There’s another syntax for atom constants. You can omit the beginning colon and start with an uppercase character:
AnAtom
This is called an alias, and at compile time, it’s transformed into :"Elixir.AnAtom". We can easily check this in the shell:
iex(1)> AnAtom == :"Elixir.AnAtom" true
When you use an alias, the compiler implicitly adds the Elixir. prefix to its text and generates the atom. But if an alias already contains the Elixir. prefix, it’s not added. Consequently, the following also works:
iex(2)> AnAtom == Elixir.AnAtom true
You may recall from earlier that you can also use aliases to give alternate names to modules:
iex(3)> alias IO, as: MyIO
iex(4)> MyIO.puts("Hello!")
Hello!
It’s no accident that the term alias is used for both things. When you write alias IO, as: MyIO, you instruct the compiler to transform MyIO into IO. Resolving this further, the final result emitted in the generated binary is :Elixir.IO. Therefore, with an alias set up, the following also holds:
iex(5)> MyIO == Elixir.IO true
All of this may seem strange, but it has an important underlying purpose. Aliases support the proper resolution of modules. This will be discussed at the end of the chapter when we revisit modules and look at how they’re loaded at run time.
It may come as a surprise that Elixir doesn’t have a dedicated Boolean type. Instead, the atoms :true and :false are used. As syntactic sugar, Elixir allows you to reference these atoms without the starting colon character:
iex(1)> :true == true true iex(2)> :false == false true
The term Boolean is still used in Elixir to denote an atom that has a value of either :true or :false. The standard logical operators work with Boolean atoms:
iex(1)> true and false false iex(2)> false or true true iex(3)> not false true iex(4)> not :an_atom_other_than_true_or_false ** (ArgumentError) argument error
Always keep in mind that a Boolean is just an atom that has a value of true or false.
Another special atom is :nil, which works somewhat similarly to null from other languages. You can reference nil without a colon:
iex(1)> nil == :nil true
The atom nil plays a role in Elixir’s additional support for truthiness, which works similarly to the way it’s used in mainstream languages, such as C/C++ and Ruby. The atoms nil and false are treated as falsy values, whereas everything else is treated as a truthy value.
This property can be used with Elixir’s short-circuit operators ||, &&, and !. The operator || returns the first expression that isn’t falsy:
iex(1)> nil || false || 5 || true 5
Because both nil and false are falsy expressions, the number 5 is returned. Notice that subsequent expressions won’t be evaluated at all. If all expressions evaluate to a falsy value, the result of the last expression is returned.
The operator && returns the second expression but only if the first expression is truthy. Otherwise, it returns the first expression without evaluating the second one:
iex(1)> true && 5 5 iex(2)> false && 5 false iex(3)> nil && 5 nil
Short-circuiting can be used for elegant operation chaining. For example, if you need to fetch a value from cache, a local disk, or a remote database, you can do something like this:
read_cached() || read_from_disk() || read_from_database()
Similarly, you can use the operator && to ensure certain conditions are met:
database_value = connection && read_data(connection)
In both examples, short-circuit operators make it possible to write concise code without resorting to complicated nested conditional expressions.
2.4.3 Tuples
Tuples are something like untyped structures, or records, and they’re most often used to group a fixed number of elements together. The following snippet defines a tuple consisting of a person’s name and age:
iex(1)> person = {"Bob", 25}
{"Bob", 25}
To extract an element from the tuple, you can use the Kernel.elem/2 function, which accepts a tuple and the zero-based index of the element. Recall that the Kernel module is auto-imported, so you can call elem instead of Kernel.elem:
iex(2)> age = elem(person, 1) 25
To modify an element of the tuple, you can use the Kernel.put_elem/3 function, which accepts a tuple, a zero-based index, and the new value of the field in the given position:
iex(3)> put_elem(person, 1, 26)
{"Bob", 26}
The function put_elem doesn’t modify the tuple. It returns the new version, keeping the old one intact. Recall that data in Elixir is immutable, so you can’t do an in-memory modification of a value. You can verify that the previous call to put_elem didn’t change the person variable:
iex(4)> person
{"Bob", 25}
So how can you use the put_elem function, then? You need to store its result to another variable:
iex(5)> older_person = put_elem(person, 1, 26)
{"Bob", 26}
iex(6)> older_person
{"Bob", 26}
Recall that variables can be rebound, so you can also do the following:
iex(7)> person = put_elem(person, 1, 26)
{"Bob", 26}
By doing this, you’ve effectively rebound the person variable to the new memory location. The old location isn’t referenced by any other variable, so it’s eligible for garbage collection.
Note You may wonder if this approach is memory efficient. In most cases, there will be little data copying, and the two variables will share as much memory as possible. This will be explained later in this section, when we discuss immutability.
Tuples are most appropriate for grouping a small, fixed number of elements together. When you need a dynamically sized collection, you can use lists.
2.4.4 Lists
In Erlang, lists are used to manage dynamic, variable-sized collections of data. The syntax deceptively resembles arrays from other languages:
iex(1)> prime_numbers = [2, 3, 5, 7] [2, 3, 5, 7]
Lists may look like arrays, but they work like singly linked lists. To do something with the list, you must traverse it. Therefore, most of the operations on lists have an O(n) complexity, including the Kernel.length/1 function, which iterates through the entire list to calculate its length:
iex(2)> length(prime_numbers) 4
To get an element of a list, you can use the Enum.at/2 function:
iex(3)> Enum.at(prime_numbers, 3) 7
Enum.at is again an O(n) operation: it iterates from the beginning of the list to the desired element. Lists are never a good fit when direct access is called for. For those purposes, tuples, maps, or a higher-level data structure is appropriate.
You can check whether a list contains a particular element with the help of the in operator:
iex(4)> 5 in prime_numbers true iex(5)> 4 in prime_numbers false
To manipulate lists, you can use functions from the List module. For example, List.replace_at/3 modifies the element at a certain position:
iex(6)> List.replace_at(prime_numbers, 0, 11) [11, 3, 5, 7]
As was the case with tuples, the modifier doesn’t mutate the variable but returns the modified version of it, which you need to store to another variable:
iex(7)> new_primes = List.replace_at(prime_numbers, 0, 11) [11, 3, 5, 7]
Or you can rebind to the same one:
iex(8)> prime_numbers = List.replace_at(prime_numbers, 0, 11) [11, 3, 5, 7]
You can insert a new element at the specified position with the List.insert_at/3 function:
iex(9)> List.insert_at(prime_numbers, 3, 13) ❶
[11, 3, 5, 13, 7]
❶ Inserts a new element at the fourth position
To append to the end, you can use a negative value for the insert position:
iex(10)> List.insert_at(prime_numbers, -1, 13) ❶
[11, 3, 5, 7, 13]
❶ The value of -1 indicates that the element should be appended to the end of the list.
Like most list operations, modifying an arbitrary element has a complexity of O(n). In particular, appending to the end is expensive because it always takes n steps, with n being the length of the list.
In addition, the dedicated operator ++ is available. It concatenates two lists:
iex(11)> [1, 2, 3] ++ [4, 5] [1, 2, 3, 4, 5]
Again, the complexity is O(n), with n being the length of the left list (the one you’re appending to). In general, you should avoid adding elements to the end of a list. Lists are most efficient when new elements are pushed to the top or popped from it. To understand why, let’s look at the recursive nature of lists.
An alternative way of looking at lists is to think of them as recursive structures. A list can be represented by a pair (head, tail), where head is the first element of the list and tail “points” to the (head, tail) pair of the remaining elements, as illustrated in figure 2.1.
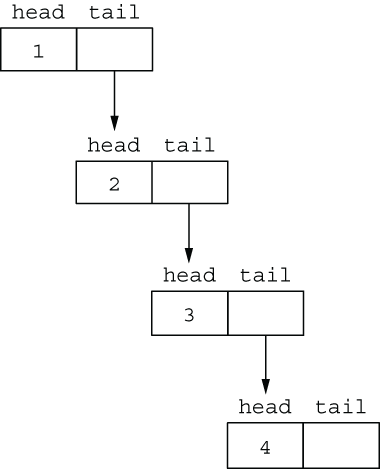
Figure 2.1 Recursive structure of the list [1, 2, 3, 4]
If you’re familiar with Lisp, then you know this concept as cons cells. In Elixir, there’s a special syntax to support recursive list definition:
a_list = [head | tail]
head can be any type of data, whereas tail is itself a list. If tail is an empty list, it indicates the end of the entire list.
iex(1)> [1 | []] [1] iex(2)> [1 | [2 | []]] [1, 2] iex(3)> [1 | [2]] [1, 2] iex(4)> [1 | [2, 3, 4]] [1, 2, 3, 4]
This is just another syntactical way of defining lists, but it illustrates what a list is. It’s a pair with two values: a head and a tail, with the tail being itself a list.
The following snippet is a canonical recursive definition of a list:
iex(1)> [1 | [2 | [3 | [4 | []]]]] [1, 2, 3, 4]
Of course, nobody wants to write expressions like this one. But it’s important that you’re always aware that, internally, lists are recursive structures of (head, tail) pairs.
To get the head of the list, you can use the hd function. The tail can be obtained by calling the tl function:
iex(1)> hd([1, 2, 3, 4]) 1 iex(2)> tl([1, 2, 3, 4]) [2, 3, 4]
Both operations are O(1) because they amount to reading one or the other value from the (head, tail) pair.
Note For the sake of completeness, it should be mentioned that the tail doesn’t need to be a list. It can be any type. When the tail isn’t a list, it’s said that the list is improper, and most of the standard list manipulations won’t work. Improper lists have some special uses, but we won’t deal with them in this book.
Once you know the recursive nature of the list, it’s simple and efficient to push a new element to the top of the list:
iex(1)> a_list = [5, :value, true] [5, :value, true] iex(2)> new_list = [:new_element | a_list] [:new_element, 5, :value, true]
Construction of the new_list is an O(1) operation, and no memory copying occurs—the tail of the new_list is the a_list. To understand how this works, let’s discuss the internal details of immutability a bit.
2.4.5 Immutability
As has been mentioned before, Elixir data can’t be mutated. Every function returns the new, modified version of the input data. You must take the new version into another variable or rebind it to the same symbolic name. In any case, the result resides in another memory location. The modification of the input will result in some data copying, but generally, most of the memory will be shared between the old and new versions. Let’s take a closer look at how this works.
Let’s start with tuples. A modified tuple is always a complete, shallow copy of the old version. Consider the following code (see figure 2.2):
a_tuple = {a, b, c}
new_tuple = put_elem(a_tuple, 1, b2)
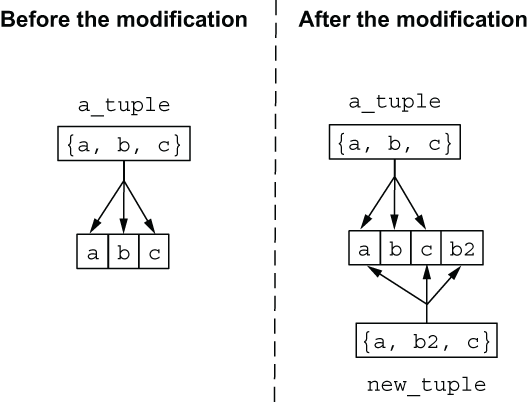
Figure 2.2 Modifying a tuple creates a shallow copy of it.
The variable new_tuple will contain a shallow copy of a_tuple, differing only in the second element.
Both tuples reference variables a and c, and whatever is in those variables is shared (and not duplicated) between both tuples. new_tuple is a shallow copy of the original a_tuple.
What happens if you rebind a variable? In this case, after rebinding, the variable a_tuple references another memory location. The old location of a_tuple isn’t accessible and is available for garbage collection. The same holds for the variable b referenced by the old version of the tuple, as illustrated in figure 2.3.
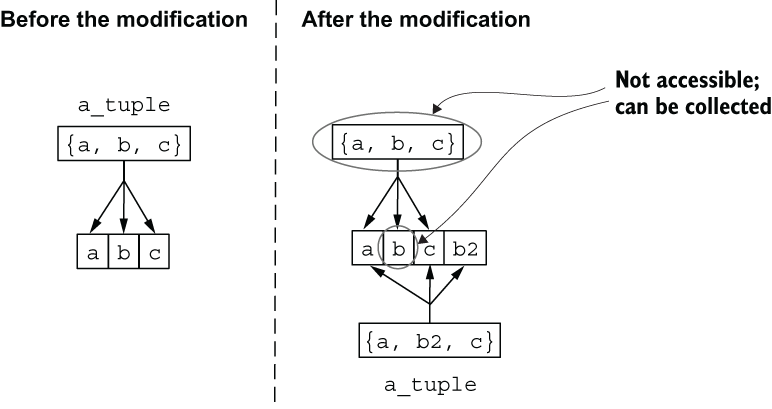
Figure 2.3 Rebinding a tuple makes the old data garbage collectible.
Keep in mind that tuples are always copied, but the copying is shallow. Lists, however, have different properties.
When you modify the nth element of a list, the new version will contain shallow copies of the first n - 1 elements followed by the modified element. After that, the tails are completely shared, as illustrated in figure 2.4.
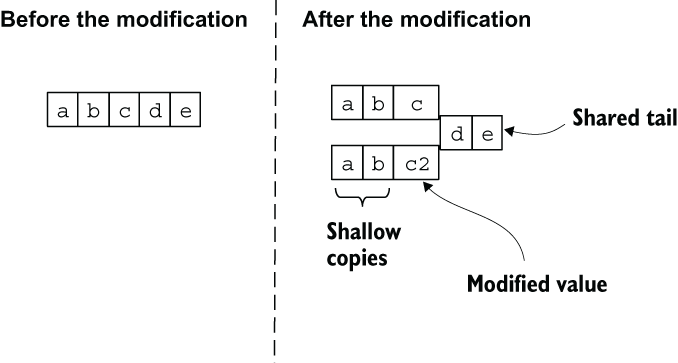
Figure 2.4 Modifying a list
This is precisely why adding elements to the end of a list is expensive. To append a new element at the tail, you must iterate and (shallow) copy the entire list. In contrast, pushing an element to the top of a list doesn’t copy anything, which makes it the least expensive operation, as illustrated in figure 2.5.
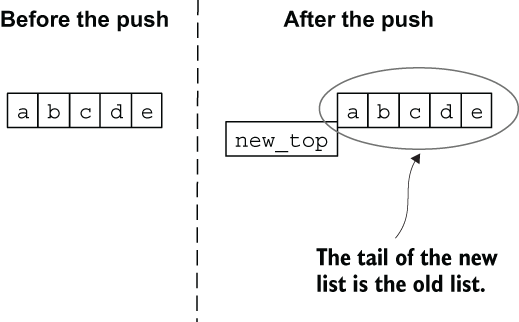
Figure 2.5 Pushing a new element to the top of the list
In this case, the new list’s tail is the previous list. This is often used in Elixir programs when iteratively building lists. In such cases, it’s best to push consecutive elements to the top, and then, after the list is constructed, reverse the entire list in a single pass.
Immutability may seem strange, and you may wonder about its purpose. There are two important benefits of immutability: side-effect-free functions and data consistency.
Given that data can’t be mutated, you can treat most functions as side-effect-free transformations. They take an input and return a result. More complicated programs are written by combining simpler transformations:
def complex_transformation(data) do data |> transformation_1(...) |> transformation_2(...) ... |> transformation_n(...) end
This code relies on the previously mentioned pipe operator that chains two functions together, feeding the result of the previous call as the first argument of the next call.
Side-effect-free functions are easier to analyze, understand, and test. They have well-defined inputs and outputs. When you call a function, you can be sure no variable will be implicitly changed. Whatever the function does, you must take its result and do something with it.
Note Elixir isn’t a pure functional language, so functions may still have side effects. For example, a function may write something to a file and issue a database or network call, which causes it to produce a side effect. But you can be certain that a function won’t modify the value of any variable.
The implicit consequence of immutable data is the ability to hold all versions of a data structure in the program. This, in turn, makes it possible to perform atomic in-memory operations. Let’s say you have a function that performs a series of transformations:
def complex_transformation(original_data) do original_data |> transformation_1(...) |> transformation_2(...) ... end
This code starts with the original data and passes it through a series of transformations, each one returning the new, modified version of the input. If something goes wrong, the complex_transformation function can return original_data, which will effectively roll back all of the transformations performed in the function. This is possible because none of the transformations modify the memory occupied by original_data.
This concludes our look at basic immutability theory. It may still be unclear how to properly use immutable data in more complex programs. This topic will be revisited in chapter 4, where we’ll deal with higher-level data structures.
2.4.6 Maps
A map is a key-value store, where keys and values can be any term. Maps have dual usage in Elixir. They’re used to power dynamically sized key-value structures, but they’re also used to manage simple records—a couple of well-defined named fields bundled together. Let’s take a look at these cases separately.
An empty map can be created with the %{} expression:
iex(1)> empty_map = %{}
A map with some values can be created with the following syntax:
iex(2)> squares = %{1 => 1, 2 => 4, 3 => 9}
You can also prepopulate a map with the Map.new/1 function. The function takes an enumerable where each element is a tuple of size 2 (a pair):
iex(3)> squares = Map.new([{1, 1}, {2, 4}, {3, 9}])
%{1 => 1, 2 => 4, 3 => 9}
To fetch a value at the given key, you can use the following approach:
iex(4)> squares[2] 4 iex(5)> squares[4] nil
In the second expression, you get nil because no value is associated with the given key.
A similar result can be obtained with Map.get/3. On the surface, this function behaves like []. However, Map.get/3 allows you to specify the default value, which is returned if the key isn’t found. If this default isn’t provided, nil will be returned:
iex(6)> Map.get(squares, 2) 4 iex(7)> Map.get(squares, 4) nil iex(8)> Map.get(squares, 4, :not_found) :not_found
Notice that in the last expression, you don’t precisely know whether there’s no value under the given key or the value is :not_found. If you want to precisely distinguish between these cases, you can use Map.fetch/2:
iex(9)> Map.fetch(squares, 2)
{:ok, 4}
iex(10)> Map.fetch(squares, 4)
:error
As you can see, in the successful case, you’ll get a value in the shape of {:ok, value}. This format makes it possible to precisely detect the case when the key isn’t present.
Sometimes you want to proceed only if the key is in the map and raise an exception otherwise. This can be done with the Map.fetch!/2 function:
iex(11)> Map.fetch!(squares, 2)
4
iex(12)> Map.fetch!(squares, 4)
** (KeyError) key 4 not found in: %{1 => 1, 2 => 4, 3 => 9}
(stdlib) :maps.get(4, %{1 => 1, 2 => 4, 3 => 9})
To store a new element to the map, you can use Map.put/3:
iex(13)> squares = Map.put(squares, 4, 16)
%{1 => 1, 2 => 4, 3 => 9, 4 => 16}
iex(14)> squares[4]
16
There are many other helpful functions in the Map module, such as Map.update/4 or Map.delete/2. You can look into the official module documentation at https://hexdocs.pm/elixir/Map.xhtml. Additionally, a map is also enumerable, which means all the functions from the Enum module can work with maps.
Maps are the go-to type for managing key-value data structures of an arbitrary size. However, they’re also frequently used in Elixir to combine a couple of fields into a single structure. This use case somewhat overlaps that of tuples, but it provides the advantage of allowing you to access fields by name.
Let’s look at an example. In the following snippet, you’ll create a map that represents a single person:
iex(1)> bob = %{:name => "Bob", :age => 25, :works_at => "Initech"}
If keys are atoms, you can write this so that it’s slightly shorter:
iex(2)> bob = %{name: "Bob", age: 25, works_at: "Initech"}
To retrieve a field, you can use the [] operator:
iex(3)> bob[:works_at] "Initech" iex(4)> bob[:non_existent_field] nil
Atom keys again receive special syntax treatment. The following snippet fetches a value stored under the :age key:
iex(5)> bob.age 25
With this syntax, you’ll get an error if you try to fetch a nonexistent field:
iex(6)> bob.non_existent_field ** (KeyError) key :non_existent_field not found
To change a field value, you can use the following syntax:
iex(7)> next_years_bob = %{bob | age: 26}
%{age: 26, name: "Bob", works_at: "Initech"}
This syntax can be used to change multiple attributes as well:
iex(8)> %{bob | age: 26, works_at: "Initrode"}
%{age: 26, name: "Bob", works_at: "Initrode"}
However, you can only modify values that already exist in the map. This makes the update syntax a perfect choice for powering maps that represent structures. If you mistype the field name, you’ll get an immediate runtime error:
iex(9)> %{bob | works_in: "Initech"}
** (KeyError) key :works_in not found
Using maps to hold structured data is a frequent pattern in Elixir. The common pattern is to provide all the fields while creating the map, using atoms as keys. If the value for some field isn’t available, you can set it to nil. Such a map, then, always has all the fields. You can modify the map with the update expression and fetch a desired field with the a_map.some_field expression.
Of course, such data is still a map, so you can also use the functions from the Map module, such as Map.put/3 or Map.fetch/2. However, these functions are usually suitable for cases in which maps are used to manage a dynamic key-value structure.
2.4.7 Binaries and bitstrings
A binary is a chunk of bytes. You can create binaries by enclosing the byte sequence between << and >> operators. The following snippet creates a three-byte binary:
iex(1)> <<1, 2, 3>> <<1, 2, 3>>
Each number represents the value of the corresponding byte. If you provide a byte value greater than 255, it’s truncated to the byte size:
iex(2)> <<256>> <<0>> iex(3)> <<257>> <<1>> iex(4)> <<512>> <<0>>
You can specify the size of each value and, thus, tell the compiler how many bits to use for that particular value:
iex(5)> <<257::16>> <<1, 1>>
This expression places the number 257 into 16 bits of consecutive memory space. The output indicates that you use 2 bytes, both with a value of 1. This is due to the binary representation of 257, which, in 16-bit form, is written 00000001 00000001.
The size specifier is in bits and need not be a multiplier of 8. The following snippet creates a binary by combining two 4-bit values:
iex(6)> <<1::4, 15::4>> <<31>>
The resulting value has 1 byte and is represented in the output using the normalized form 31 (0001 1111).
If the total size of all the values isn’t a multiple of 8, the binary is called a bitstring—a sequence of bits:
iex(7)> <<1::1, 0::1, 1::1>> <<5::size(3)>>
You can also concatenate two binaries or bitstrings with the operator <>:
iex(8)> <<1, 2>> <> <<3, 4>> <<1, 2, 3, 4>>
There’s much more that can be done with binaries, but for the moment, we’ll put them aside. The most important thing you need to know about binaries is that they’re consecutive sequences of bytes. Binaries play an important role in support for strings.
2.4.8 Strings
It may come as a surprise, but Elixir doesn’t have a dedicated string type. Instead, strings are represented using either a binary or a list type.
The most common way to use strings is to specify them with the familiar double-quotes syntax:
iex(1)> "This is a string" "This is a string"
The result is printed as a string, but underneath, it’s a binary—nothing more than a consecutive sequence of bytes.
Elixir provides support for embedded string expressions. You can use #{} to place an Elixir expression in a string constant. The expression is immediately evaluated, and its string representation is placed at the corresponding location in the string:
iex(2)> "Embedded expression: #{3 + 0.14}"
"Embedded expression: 3.14"
Classical \ escaping works as you’re used to:
iex(3)> "\r \n \" \\"
And strings don’t need to finish on the same line:
iex(4)> "
This is
a multiline string
"
Elixir provides another syntax for declaring strings, or sigils. In this approach, you enclose the string inside ~s():
iex(5)> ~s(This is also a string) "This is also a string"
Sigils can be useful if you want to include quotes in a string:
iex(6)> ~s("Do... or do not. There is no try." -Master Yoda)
"\"Do... or do not. There is no try.\" -Master Yoda"
There’s also an uppercase version ~S that doesn’t handle interpolation or escape characters (\):
iex(7)> ~S(Not interpolated #{3 + 0.14})
"Not interpolated \#{3 + 0.14}"
iex(8)> ~S(Not escaped \n)
"Not escaped \\n"
Finally, there’s a special heredocs syntax, which supports better formatting for multiline strings. Heredocs strings start with a triple double-quote. The ending triple double-quote must be on its own line:
iex(9)> """
Heredoc must end on its own line """
"""
"Heredoc must end on its own line \"\"\"\n"
Because strings are binaries, you can concatenate them with the <> operator:
iex(10)> "String" <> " " <> "concatenation" "String concatenation"
Many helper functions are available for working with binary strings. Most of them reside in the String module (https://hexdocs.pm/elixir/String.xhtml).
A character list (also called a charlist) is a list in which each element is an integer code point of the corresponding character. For example, the letters ABC could be represented as the list [65, 66, 67]:
iex(1)> IO.puts([65, 66, 67]) ABC
You can also create the list with the ~c sigil:
iex(2)> IO.puts(~c"ABC") ABC
Another option is to use single quotes:
iex(3)> IO.puts('ABC')
ABC
Starting with Elixir 1.15, the recommended method is to use ~c. The Elixir formatter converts single quotes into a sigil equivalent. In addition, character lists are printed in the shell using the ~c syntax:
iex(4)> ~c"ABC" ~c"ABC" iex(5)> [65, 66, 67] ~c"ABC" iex(6)> 'ABC' ~c"ABC"
Character lists aren’t compatible with binary strings. Most of the operations from the String module won’t work with character lists. In general, you should prefer binary strings over character lists.
Occasionally, some functions work only with character lists. This mostly happens with pure Erlang libraries. In this case, you can convert a binary string to a character list version, using the String.to_charlist/1 function:
iex(7)> String.to_charlist("ABC")
~c"ABC"
To convert a character list to a binary string, you can use List.to_string/1:
iex(8)> List.to_string(~c"ABC") "ABC"
In general, you should prefer binary strings as much as possible, using character lists only when some third-party library (most often written in pure Erlang) requires it.
2.4.9 First-class functions
In Elixir, a function is a first-class citizen, which means it can be assigned to a variable. Here, assigning a function to a variable doesn’t mean calling the function and storing its result to a variable. Instead, the function definition itself is assigned, and you can use the variable to call the function.
Let’s look at some examples. To create a function variable, you can use the fn expression:
iex(1)> square = fn x ->
x * x
end
The variable square now contains a function that computes the square of a number. Because the function isn’t bound to a global name, it’s also called an anonymous function or lambda.
Notice that the list of arguments isn’t enclosed in parentheses. Technically, you can use parentheses here, but the prevalent convention, also enforced by the Elixir formatter, is to omit parentheses. In contrast, a list of arguments to a named function should be enclosed in parentheses. At first glance, this looks inconsistent, but there’s a good reason for this convention, which will be explained in chapter 3.
You can call this function by specifying the variable name followed by a dot (.) and the arguments:
iex(2)> square.(5) 25
Note You may wonder why the dot operator is needed here. In this context, its purpose is to make the code more explicit. When you encounter a square.(5) expression in the source code, you know an anonymous function is being invoked. In contrast, the expression square(5) is invoking a named function defined somewhere else in the module. Without the dot operator, you’d need to parse the surrounding code to understand whether you’re calling a named or an anonymous function.
Because functions can be stored in a variable, they can be passed as arguments to other functions. This is often used to allow clients to parameterize generic logic. For example, the function Enum.each/2 implements the generic iteration—it can iterate over anything enumerable, such as lists. The function Enum.each/2 takes two arguments: an enumerable and a one-arity lambda (an anonymous function that accepts one argument). It iterates through the enumerable and calls the lambda for each element. The clients provide the lambda to specify what they want to do with each element.
The following snippet uses Enum.each to print each value of a list to the screen:
iex(3)> print_element = fn x -> IO.puts(x) end ❶ iex(4)> Enum.each( [1, 2, 3], print_element ❷ ) 1 ❸ 2 ❸ 3 ❸ :ok ❹
❷ Passes the lambda to Enum.each
❸ Output printed by the lambda
Of course, you don’t need a temp variable to pass the lambda to Enum.each:
iex(5)> Enum.each(
[1, 2, 3],
fn x -> IO.puts(x) end ❶
)
1
2
3
Notice how the lambda simply forwards all arguments to IO.puts, doing no other meaningful work. For such cases, Elixir makes it possible to directly reference the function and have a more compact lambda definition. Instead of writing fn x -> IO.puts(x) end, you can write &IO.puts/1.
The & operator, also known as the capture operator, takes the full function qualifier—a module name, a function name, and an arity—and turns that function into a lambda that can be assigned to a variable. You can use the capture operator to simplify the call to Enum.each:
iex(6)> Enum.each(
[1, 2, 3],
&IO.puts/1 ❶
)
❶ Passes the lambda that delegates to IO.puts
The capture operator can also be used to shorten the lambda definition, making it possible to omit explicit argument naming. For example, you can change this definition
iex(7)> lambda = fn x, y, z -> x * y + z end
iex(8)> lambda = &(&1 * &2 + &3)
This snippet creates a three-arity lambda. Each argument is referred to via the &n placeholder, which identifies the nth argument of the function. You can call this lambda like any other:
iex(9)> lambda.(2, 3, 4) 10
The return value 10 amounts to 2 × 3 + 4, as specified in the lambda definition.
A lambda can reference any variable from the outside scope:
iex(1)> outside_var = 5
5
iex(2)> my_lambda = fn ->
IO.puts(outside_var) ❶
end
iex(3)> my_lambda.()
5
❶ Lambda references a variable from the outside scope.
As long as you hold the reference to my_lambda, the variable outside_var is also accessible. This is also known as closure ; by holding a reference to a lambda, you indirectly hold a reference to all variables it uses, even if those variables are from the external scope.
A closure always captures a specific memory location. Rebinding a variable doesn’t affect the previously defined lambda that references the same symbolic name:
iex(1)> outside_var = 5 iex(2)> lambda = fn -> IO.puts(outside_var) end ❶ iex(3)> outside_var = 6 ❷ iex(4)> lambda.() ❸ 5
❶ Lambda captures the current location of outside_var.
❷ Rebinding doesn’t affect the closure.
❸ Proof the closure isn’t affected
The preceding code illustrates another important point. Normally, after you have rebound outside_var to the value 6, the original memory location would be eligible for garbage collection. But because the lambda function captures the original location (the one that holds the number 5) and you’re still referencing that lambda, the original location isn’t available for garbage collection.
2.4.10 Other built-in types
There are a couple of types I still haven’t presented. We won’t deal with them in depth, but they’re worth mentioning for the sake of completeness:
-
A reference is an almost unique piece of information in a BEAM instance. It’s generated by calling
Kernel.make_ref/0(ormake_ref). According to the Elixir documentation, a reference will reoccur after approximately 2^82 calls. But if you restart a BEAM instance, reference generation starts from the beginning, so its uniqueness is guaranteed only during the lifetime of the BEAM instance. -
A process identifier (PID) is used to identify an Erlang process. PIDs are important when cooperating between concurrent tasks, and you’ll learn about them in chapter 5 when we discuss Erlang processes.
-
The port identifier is important when using ports. It’s a mechanism used in Erlang to talk to the outside world. File I/O and communication with external programs are done through ports. Ports are outside the scope of this book.
With that, we’ve covered all the basic data types. As you can see, Elixir has a simple type system, consisting of only a handful of data types.
Of course, higher-level types are also available, which build on these basic types to provide additional functionality. Let’s look at some of the most important types that ship with Elixir.
2.4.11 Higher-level types
The aforementioned built-in types are inherited from the Erlang world. After all, Elixir code runs on BEAM, so its type system is heavily influenced by the Erlang foundations. But on top of these basic types, Elixir provides some higher-level abstractions. The ones most frequently used are Range, Keyword, MapSet, Date, Time, NaiveDateTime, and DateTime. Let’s examine each of them.
A range is an abstraction that allows you to represent a range of numbers. Elixir even provides special syntax for defining ranges:
iex(1)> range = 1..2
You can ask whether a number falls in the range by using the in operator:
iex(2)> 2 in range true iex(3)> -1 in range false
Ranges are enumerable, so functions from the Enum module know how to work with them. Earlier, you encountered Enum.each/2, which iterates through an enumerable. The following example uses this function with a range to print the first three natural numbers:
iex(4)> Enum.each(
1..3,
&IO.puts/1
)
1
2
3
Range isn’t a special type. Internally, it’s represented as a map that contains range boundaries. Therefore, a range memory footprint is small and constant, regardless of the number of elements it represents. A million-number range is still just a small map. For more information on ranges, see the documentation for the Range module (https://hexdocs.pm/elixir/Range.xhtml).
A keyword list is a special case of a list, where each element is a two-element tuple, and the first element of each tuple is an atom. The second element can be of any type. Let’s look at an example:
iex(1)> days = [{:monday, 1}, {:tuesday, 2}, {:wednesday, 3}]
Elixir supports a slightly shorter syntax for defining a keyword list:
iex(2)> days = [monday: 1, tuesday: 2, wednesday: 3]
Both expressions yield the same result: a list of pairs. Arguably, the second is a bit more elegant.
Keyword lists are often used for small-size key-value structures, where keys are atoms. Many useful functions are available in the Keyword module (https://hexdocs.pm/elixir/Keyword.xhtml). For example, you can use Keyword.get/2 to fetch the value for a key:
iex(3)> Keyword.get(days, :monday) 1 iex(4)> Keyword.get(days, :noday) nil
Just as with maps, you can use the operator [] to fetch a value:
iex(5)> days[:tuesday] 2
Don’t let that fool you, though. Because you’re dealing with a list, the complexity of a lookup operation is O(n).
Keyword lists are most often useful for allowing clients to pass an arbitrary number of optional arguments. For example, the result of the function IO.inspect, which prints a string representation of a term to the console, can be controlled by providing additional options through a keyword list:
iex(6)> IO.inspect([100, 200, 300]) ❶ [100, 200, 300] ❶ iex(7)> IO.inspect([100, 200, 300], [width: 3]) ❷ [100, ❷ 200, ❷ 300] ❷
In fact, this pattern is so frequent that Elixir allows you to omit the square brackets if the last argument is a keyword list:
iex(8)> IO.inspect([100, 200, 300], width: 3, limit: 1) [100, ...]
Notice that, in this example, you’re still sending two arguments to IO.inspect/2: a list of numbers and a two-element keyword list. But this snippet demonstrates how to simulate optional arguments. You can accept a keyword list as the last argument of your function and make that argument default to an empty list:
def my_fun(arg1, arg2, opts \\ []) do ... end
Your clients can then pass options via the last argument. Of course, it’s up to you to check the contents in the opts argument and perform some conditional logic depending on what the caller has sent you.
You may wonder if it’s better to use maps instead of keywords for optional arguments. A keyword list can contain multiple values for the same key. Additionally, you can control the ordering of keyword list elements—something that isn’t possible with maps. Finally, many functions in standard libraries of Elixir and Erlang take their options as keyword lists. It’s best to stick to the existing convention and accept optional parameters via keyword lists.
A MapSet is the implementation of a set—a store of unique values, where a value can be of any type. Let’s look at some examples:
iex(1)> days = MapSet.new([:monday, :tuesday, :wednesday]) ❶ MapSet.new([:monday, :tuesday, :wednesday]) iex(2)> MapSet.member?(days, :monday) ❷ true iex(3)> MapSet.member?(days, :noday) ❸ false iex(4)> days = MapSet.put(days, :thursday) ❹ MapSet.new([:monday, :tuesday, :wednesday, :thursday])
❷ Verifies the presence of the existing element
❸ Verifies the presence of a nonexisting element
❹ Puts a new element in the MapSet
As you can see, you can manipulate the set using the function from the MapSet module. For a detailed reference, refer to the official documentation at https://hexdocs.pm/elixir/MapSet.xhtml.
A MapSet is also an enumerable, so you can pass it to functions from the Enum module:
iex(5)> Enum.each(days, &IO.puts/1) monday thursday tuesday wednesday
As you can tell from the output, MapSet doesn’t preserve the ordering of the items.
Elixir has a few modules for working with date and time types: Date, Time, DateTime, and NaiveDateTime.
A date can be created with the ~D sigil. The following example creates a date that represents January 31, 2023:
iex(1)> date = ~D[2023-01-31] ~D[2023-01-31]
Once you’ve created the date, you can retrieve its individual fields:
iex(2)> date.year 2023 iex(3)> date.month 1
Similarly, you can represent a time with the ~T sigil, by providing hours, minutes, seconds, and microseconds:
iex(1)> time = ~T[11:59:12.00007] iex(2)> time.hour 11 iex(3)> time.minute 59
There are also some useful functions available in the modules Date (https://hexdocs.pm/elixir/Date.xhtml) and Time (https://hexdocs.pm/elixir/Time.xhtml).
In addition to these two types, you can work with DateTime’s using the NaiveDateTime and DateTime modules. The naive version can be created with the ~N sigil:
iex(1)> naive_datetime = ~N[2023-01-31 11:59:12.000007] iex(2)> naive_datetime.year 2023 iex(3)> naive_datetime.hour 11
The DateTime module can be used to work with datetimes and supports time zones. A UTC datetime instance can be created using the ~U sigil:
iex(1)> datetime = ~U[2023-01-31 11:59:12.000007Z] iex(2)> datetime.year 2023 iex(3)> datetime.hour 11 iex(4)> datetime.time_zone "Etc/UTC"
You can refer to the reference documentation, available at https://hexdocs.pm/elixir/NaiveDateTime.xhtml and https://hexdocs.pm/elixir/DateTime.xhtml, for more details on working with these types.
2.4.12 IO lists
An IO list is a special sort of list that’s useful for incrementally building output that will be forwarded to an I/O device, such as a network or a file. Each element of an IO list must be one of the following:
In other words, an IO list is a deeply nested structure in which leaf elements are plain bytes (or binaries, which are again a sequence of bytes). For example, here’s "Hello, world!" represented as a convoluted IO list:
iex(1)> iolist = [[[~c"He"], "llo,"], " worl", "d!"]
Notice how you can combine character lists and binary strings into a deeply nested list.
Many I/O functions can work directly and efficiently with such data. For example, you can print this structure to the screen:
iex(2)> IO.puts(iolist) Hello, world!
Under the hood, the structure is flattened, and you can see the human-readable output. You’ll get the same effect if you send an IO list to a file or a network socket.
IO lists are useful when you need to incrementally build a stream of bytes. Lists usually aren’t effective in this case because appending to a list is an O(n) operation. In contrast, appending to an IO list is O(1) because you can use nesting. Here’s a demonstration of this technique:
iex(3)> iolist = [] ❶ iolist = [iolist, "This"] ❷ iolist = [iolist, " is"] ❷ iolist = [iolist, " an"] ❷ iolist = [iolist, " IO list."] ❷ [[[[[], "This"], " is"], " an"], " IO list."] ❸
❷ Multiple appends to an IO list
Here, you append to an IO list by creating a new list with two elements: a previous version of the IO list and the suffix that’s appended. Each such operation is O(1), so this is performant. And, of course, you can send this data to an IO function:
iex(4)> IO.puts(iolist) This is an IO list.
This concludes our initial tour of the type system. We’ve covered most of the basics, and we’ll expand on them throughout the book, as the need arises. Next, it’s time to learn a bit about Elixir operators.
2.5 Operators
You’ve been using various operators throughout this chapter, and in this section, we’ll take a systematic look at the ones most commonly used in Elixir. Most of the operators are defined in the Kernel module, and you can refer to the module documentation for a detailed description.
Let’s start with arithmetic operators. These include the standard +, -, *, and / operators, and they work mostly as you’d expect, with the exception that the division operator always returns a float, as explained when we were dealing with numbers earlier in this chapter.
The comparison operators are more or less similar to what you’re used to. They’re listed in table 2.1.
Table 2.1 Comparison operators
|
Less than, greater than, less than or equal, greater than or equal |
The only thing we need to discuss here is the difference between strict and weak equality. This is relevant only when comparing integers to floats:
iex(1)> 1 == 1.0 ❶ true iex(2)> 1 === 1.0 ❷ false
Logical operators work on Boolean atoms. You saw them earlier in the discussion of atoms, but I’ll repeat them once more: and, or, and not.
Unlike logical operators, short-circuit operators work with the concept of truthiness: the atoms false and nil are treated as falsy, and everything else is treated as truthy. The && operator returns the first expression if it’s falsy; otherwise, it returns the second expression. The || operator returns the first expression if it’s truthy; otherwise, it returns the second expression. The unary operator ! returns false if the value is truthy; otherwise, it returns true.
The operators presented here aren’t the only ones available (e.g., you’ve also seen the pipe operator |>). But these are the most common ones, so it is worth mentioning them in one place. You can find the detailed information on operators at https://hexdocs.pm/elixir/operators.xhtml.
We’ve almost completed our initial tour of the language. One thing remains: Elixir macros.
2.6 Macros
Macros are one of the most important features Elixir brings to the table that are unavailable in plain Erlang. They make it possible to perform powerful code transformations at compile time, thus reducing boilerplate and providing elegant, mini-DSL expressions.
Macros are a fairly complex subject, and it would take a small book to treat them extensively. Because this book is more oriented toward runtime and BEAM, and macros are a somewhat advanced feature that should be used sparingly, I won’t provide a detailed treatment. But you should have a general idea of how macros work because many Elixir features are powered by them.
A macro consists of Elixir code that can change the semantics of the input code. A macro is always called at compile time; it receives the parsed representation of the input Elixir code, and it has the opportunity to return an alternative version of that code.
Let’s clear this up with an example. unless (an equivalent of if not) is a simple macro provided by Elixir:
unless some_expression do block_1 else block_2 end
unless isn’t a special keyword. It’s a macro (meaning an Elixir function) that transforms the input code into something like this:
if some_expression do block_2 else block_1 end
Such a transformation isn’t possible with C-style macros because the code of the expression can be arbitrarily complex and deeply nested. But in Elixir macros (which are heavily inspired by Lisp), you already work on a parsed source representation, so you’ll have access to the expression and both blocks in separate variables.
The end effect is that many parts of Elixir are written in Elixir with the help of macros. This includes the unless and if expressions as well as defmodule and def. Whereas other languages usually use keywords for such features, in Elixir, they’re built on top of a much smaller language core.
The main point to take away is that macros are compile-time code transformers. Whenever I note that something is a macro, the underlying implication is that it runs at compile time and produces alternative code.
For details, you may want to look at the official meta-programming guide (https://mng.bz/BAd1). Meanwhile, we’re done with our initial tour of the Elixir language. But before we finish this chapter, we should discuss some important aspects of the underlying runtime.
2.7 Understanding the runtime
As has been mentioned, the Elixir runtime is a BEAM instance. Once the compiling is done and the system is started, Erlang takes control. It’s important to be familiar with some details of the virtual machine, so you can understand how your systems work. First, let’s look at the significance of modules in the runtime.
2.7.1 Modules and functions in the runtime
Regardless of how you start the runtime, an OS process for the BEAM instance is started, and everything runs inside that process. This is true even when you’re using the iex shell. If you need to find this OS process, you can look it up under the name beam.
Once the system is started, you run some code, typically by calling functions from modules. How does the runtime access the code? The VM keeps track of all modules loaded in-memory. When you call a function from a module, BEAM first checks whether the module is loaded. If it is, the code of the corresponding function is executed. Otherwise, the VM tries to find the compiled module file—the bytecode—on the disk and then load it and execute the function.
Note The previous description reveals that each compiled module resides in a separate file. A compiled module file has the extension .beam (for Bogdan/ Björn’s Erlang Abstract Machine). The name of the file corresponds to the module name.
Let’s recall how modules are defined:
defmodule Geometry do ... end
Also recall from the discussion about atoms that Geometry is an alias that corresponds to :"Elixir.Geometry", as demonstrated in the following snippet:
iex(1)> Geometry == :"Elixir.Geometry" true
This isn’t an accident. When you compile the source containing the Geometry module, the file generated on the disk is named Elixir.Geometry.beam, regardless of the name of the input source file. In fact, if multiple modules are defined in a single source file, the compiler will produce multiple .beam files that correspond to those modules. You can try this by calling the Elixir compiler (elixirc) from the command line:
$ elixirc source.ex
Here, the file source.ex defines a couple of modules. Assuming there are no syntax errors, you’ll see multiple .beam files generated on the disk.
In the runtime, module names are aliases, and as I said, aliases are atoms. The first time you call the function of a module, BEAM tries to find the corresponding file on the disk. The VM looks for the file in the current folder and then in the code paths.
When you start BEAM with Elixir tools (e.g., iex), some code paths are predefined for you. You can add additional code paths by providing the -pa switch:
$ iex -pa my/code/path -pa another/code/path
You can check which code paths are used at run time by calling the Erlang function :code.get_path.
If the module is loaded, the runtime doesn’t search for it on the disk. This can be used when starting the shell, to autoload modules:
$ iex my_source.ex
This command compiles the source file and then immediately loads all generated modules. Notice that in this case, .beam files aren’t saved to disk. The iex tool performs an in-memory compilation.
Similarly, you can define modules in the shell:
iex(1)> defmodule MyModule do ❶
def my_fun, do: :ok
end
iex(2)> MyModule.my_fun
:ok
❶ In-memory bytecode generation and loading of a module
Again, the bytecode isn’t saved to the disk in this case.
You’ve already seen how to call a function from a pure (non-Elixir) Erlang module. Let’s talk a bit about this syntax:
:code.get_path ❶
❶ Calls the get_path function of the pure Erlang :code module
In Erlang, modules also correspond to atoms. Somewhere on the disk is a file named code.beam that contains the compiled code of the :code module. Erlang uses simple filenames, which is the reason for this call syntax. But the rules are the same as with Elixir modules. In fact, Elixir modules are nothing more than Erlang modules with fancier names (e.g., Elixir.MyModule).
You can create modules with simple names in Elixir (although this isn’t recommended):
defmodule :my_module do ... end
Compiling the source file that contains such a definition will generate my_module.beam on the disk.
The important thing to remember from this discussion is that at run time, module names are atoms. And somewhere on the disk is an xyz.beam file, where xyz is the expanded form of an alias (e.g., Elixir.MyModule when the module is named MyModule).
Somewhat related to this discussion is the ability to dynamically call functions at run time. This can be done with the help of the Kernel.apply/3 function:
iex(1)> apply(IO, :puts, ["Dynamic function call."]) Dynamic function call.
Kernel.apply/3 receives three arguments: the module atom, the function atom, and the list of arguments passed to the function. Together, these three arguments, often called module, function, arguments (MFA), contain all the information needed to call an exported (public) function. Kernel.apply/3 can be useful when you need to make a runtime decision about which function to call.
2.7.2 Starting the runtime
There are several ways to start BEAM. So far, you’ve been using iex, and you’ll continue to do so for some time. But let’s quickly look at all the possible ways to start the runtime.
When you start the shell, the BEAM instance is started underneath, and the Elixir shell takes control. The shell takes the input, interprets it, and prints the result.
It’s important to be aware that input is interpreted because that means it won’t be as performant as the compiled code. This is generally fine because you use the shell only to experiment with the language. However, you shouldn’t try to measure performance directly from iex. On the other hand, modules are always compiled. Even if you define a module in the shell, it will be compiled and loaded in-memory, so there will be no performance hit.
The elixir command can be used to run a single Elixir source file. Here’s the basic syntax:
$ elixir my_source.ex
When you start this, the following actions take place:
-
The file my_source.ex is compiled in-memory, and the resulting modules are loaded to the VM. No .beam file is generated on the disk.
This is generally useful for running scripts. In fact, it’s recommended for such a script to have an .exs extension, with the trailing s indicating it’s a script.
The following listing shows a simple Elixir script.
Listing 2.5 Elixir script (script.exs)
defmodule MyModule do
def run do
IO.puts("Called MyModule.run")
end
end
MyModule.run ❶
❶ Code outside of a module is executed immediately.
You can execute this script from the command line:
$ elixir script.exs
This call first does the in-memory compilation of the MyModule module and then calls MyModule.run. After the call to MyModule.run finishes, the BEAM instance is stopped.
If you don’t want a BEAM instance to terminate, you can provide the --no-halt parameter:
$ elixir --no-halt script.exs
This is most often useful if your main code (outside a module) starts concurrent tasks that perform all the work. In this situation, your main call finishes as soon as the concurrent tasks are started, and BEAM is immediately terminated (and no work is done). Providing the --no-halt option keeps the entire system alive and running.
The mix tool is used to manage projects made up of multiple source files. Whenever you need to build a production-ready system, mix is your best option.
To create a new Mix project, you can call the mix new project_name from the command line:
$ mix new my_project
This creates a new folder, named my_project, containing a few subfolders and files. You can change to the my_project folder and compile the entire project:
$ cd my_project $ mix compile $ mix compile Compiling 1 file (.ex) Generated my_project app
The compilation goes through all the files from the lib folder and places the resulting .beam files in the ebin folder.
You can execute various mix commands on the project. For example, the generator created the module MyProject with the single function hello/0. You can invoke it with mix run:
$ mix run -e "IO.puts(MyProject.hello())" world
The generator also create a couple of tests, which can be executed with mix test:
$ mix test .. Finished in 0.03 seconds 2 tests, 0 failures
Regardless of how you start the Mix project, it ensures the ebin folder (where the .beam files are placed) is in the load path, so the VM can find your modules.
You’ll use mix a lot once you start creating more complex systems. For now, there’s no need to go into any more detail.
Summary
-
Elixir is a dynamic language. The type of a variable is determined by the value it holds.
-
Data is immutable—it can’t be modified. A function can return the modified version of the input that resides in another memory location. The modified version shares as much memory as possible with the original data.
-
The most important primitive data types are numbers, atoms, and binaries.
-
There is no Boolean type. Instead, the atoms
trueandfalseare used. -
There is no nullability. The atom
nilcan be used for this purpose. -
There is no string type. Instead, you can use either binaries (recommended) or lists (when needed).
-
The built-in complex types are tuples, lists, and maps. Tuples are used to group a small, fixed-size number of fields. Lists are used to manage variable-size collections. A map is a key-value data structure.
-
Range, keyword lists,MapSet,Date,Time,NaiveDateTime, andDateTimeare abstractions built on top of the existing built-in types. -
Module names are atoms (or aliases) that correspond to .beam files on the disk.
-
There are multiple ways of starting programs:
iex,elixir, and themixtool.