5 Concurrency primitives
- Understanding BEAM concurrency principles
- Working with processes
- Working with stateful server processes
- Run-time considerations
Now that you have sufficient knowledge of Elixir and functional programming idioms, we’ll turn our attention to BEAM concurrency—a feature that plays a central role in Elixir’s and Erlang’s support for scalability, fault tolerance, and distribution. In this chapter, we’ll start our tour of BEAM concurrency by looking at basic techniques and tools. Before we explore the lower-level details, we’ll take a look at higher-level principles.
5.1 Concurrency in BEAM
Erlang is all about writing highly available systems—systems that run forever and are always able to meaningfully respond to client requests. To make your system highly available, you must tackle the following challenges:
-
Fault tolerance—Minimize, isolate, and recover from the effects of run-time errors.
-
Scalability—Handle a load increase by adding more hardware resources without changing or redeploying the code.
-
Distribution—Run your system on multiple machines so that others can take over if one machine crashes.
If you address these challenges, your systems can constantly provide service with minimal downtime and failures.
Concurrency plays an important role in achieving high availability. In BEAM, the unit of concurrency is a process—a basic building block that makes it possible to build scalable, fault-tolerant, distributed systems.
Note A BEAM process shouldn’t be confused with an OS process. As you’re about to learn, BEAM processes are much lighter and cheaper than OS processes. Because this book deals mostly with BEAM, the term process in the remaining text refers to a BEAM process.
In production, a typical server system must handle many simultaneous requests from different clients, maintain a shared state (e.g., caches, user session data, and server-wide data), and run some additional background processing jobs. For the server to work normally, all of these tasks should run reasonably quickly and be reliable.
Because many tasks are pending simultaneously, it’s imperative to execute them in parallel as much as possible, thus taking advantage of all available CPU resources. For example, it’s extremely bad if the lengthy processing of one request blocks all other pending requests and background jobs. Such behavior can lead to a constant increase in the request queue, and the system can become unresponsive.
Moreover, tasks should be as isolated from each other as possible. You don’t want an unhandled exception in one request handler to crash another unrelated request handler; a background job; or, especially, the entire server. You also don’t want a crashing task to leave behind an inconsistent memory state, which might later compromise another task.
That’s exactly what the BEAM concurrency model does for us. Processes help us run things in parallel, allowing us to achieve scalability—the ability to address a load increase by adding more hardware power, which the system automatically takes advantage of.
Processes also ensure isolation, which, in turn, gives us fault tolerance—the ability to localize and limit the effect of unexpected run-time errors that inevitably occur. If you can localize exceptions and recover from them, you can implement a system that truly never stops, even when unexpected errors occur.
In BEAM, a process is a concurrent thread of execution. Two processes run concurrently and may, therefore, run in parallel, assuming at least two CPU cores are available. Unlike OS processes or threads, BEAM processes are lightweight, concurrent entities handled by the VM, which uses its own scheduler to manage their concurrent execution.
By default, BEAM uses as many schedulers as there are CPU cores available. For example, on a quad-core machine, four schedulers are used, as shown in figure 5.1.
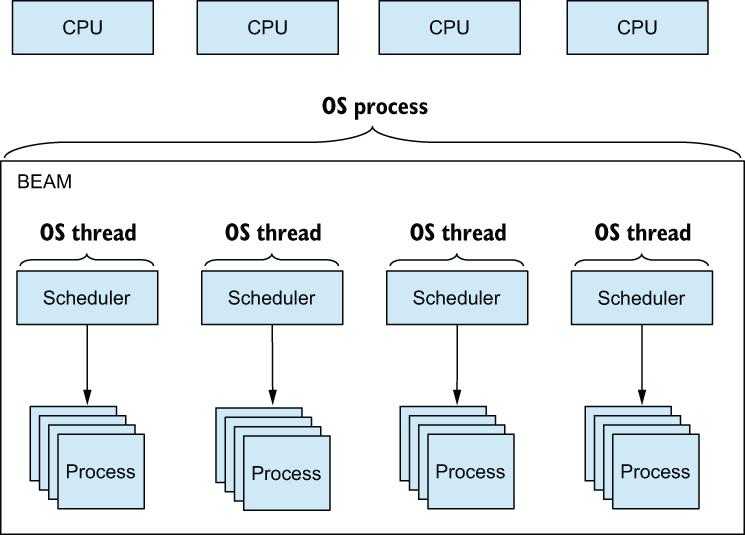
Figure 5.1 BEAM as a single OS process, using a few threads to schedule a large number of processes
Each scheduler runs in its own thread, and the entire VM runs in a single OS process. In figure 5.1, there’s one OS process and four OS threads, and that’s all you need to run a highly concurrent server system.
A scheduler is in charge of the interchangeable execution of processes. Each process gets an execution time slot; after the time is up, the running process is preempted, and the next one takes over.
Processes are light. It takes only a couple of microseconds to create a single process, and its initial memory footprint is a few kilobytes. By comparison, OS threads usually use a couple megabytes just for the stack. Therefore, you can create a large number of processes; the theoretical limit imposed by the VM is roughly 134 million!
This feature can be exploited in server-side systems to manage various tasks that should run simultaneously. Using a dedicated process for each task, you can take advantage of all available CPU cores and parallelize the work as much as possible.
Moreover, running tasks in different processes improves the server’s reliability and fault tolerance. BEAM processes are completely isolated; they share no memory, and a crash of one process won’t take down other processes. In addition, BEAM provides a means to detect a process crash and do something about it, such as restarting the crashed process. All this makes it easier to create systems that are more stable and can gracefully recover from unexpected errors, which will inevitably occur during production.
Finally, each process can manage some state and receive messages from other processes to manipulate or retrieve that state. As you saw in part 1 of this book, data in Elixir is immutable. To keep it alive, you need to hold on to it, constantly passing the result of one function to another. A process can be considered a container of this data—a place where an immutable structure is stored and kept alive for a longer time, possibly forever.
As you can see, there’s more to concurrency than parallelization of the work. With this high-level view of BEAM processes in place, let’s look at how you can create processes and work with them.
5.2 Working with processes
The benefits of processes are most obvious when you want to run something concurrently and parallelize the work as much as possible. For example, let’s say you need to run a bunch of potentially long-running database queries. You could run those queries sequentially, one at a time, or you could try to run them concurrently, hoping that the total execution time will be reduced.
To keep things simple, we’ll use a simulation of a long-running database query, presented in the following snippet:
iex(1)> run_query =
fn query_def ->
Process.sleep(2000) ❶
"#{query_def} result"
end
❶ Simulates a long- running query
Here, the code sleeps for two seconds to simulate a long-running operation. When you call the run_query lambda, the shell is blocked until the lambda is done:
iex(2)> run_query.("query 1")
"query 1 result" ❶
Consequently, if you run five queries, it will take 10 seconds to get all the results:
iex(3)> Enum.map(
1..5,
fn index ->
query_def = "query #{index}"
run_query.(query_def)
end
)
["query 1 result", "query 2 result", "query 3 result" ❶
"query 4 result", "query 5 result"]
Obviously, this is neither performant nor scalable. Assuming the queries are already optimized, the only thing you can do to try to make things faster is run the queries concurrently. This won’t speed up individual queries, but the total time required to run all the queries should be reduced. In the BEAM world, to run something concurrently, you must create a separate process.
5.2.1 Creating processes
To create a process, you can use the auto-imported spawn/1 function:
spawn(fn -> expression_1 ❶ ... ❶ expression_n ❶ end)
The function spawn/1 creates (spawns) a new process. The provided zero-arity lambda will run concurrently, in the spawned process. After the lambda finishes, the spawned process is stopped. As soon as the new process is spawned, spawn/1 returns and the caller process can continue its execution.
You can try this to run the query concurrently:
iex(4)> spawn(fn ->
query_result = run_query.("query 1")
IO.puts(query_result)
end)
#PID<0.48.0> ❶
query 1 result ❷
As you can see, the call to spawn/1 returns immediately, and you can do something else in the shell while the query runs concurrently. Then, after 2 seconds, the result is printed to the screen.
The funny-looking #PID<0.48.0> that’s returned by spawn/1 is the identifier of the created process, often called a PID. This can be used to communicate with the process, as you’ll see later in this chapter.
In the meantime, let’s do some more experimenting with concurrent execution. First, you’ll create a helper lambda that concurrently runs the query and prints the result:
iex(5)> async_query =
fn query_def ->
spawn(fn ->
query_result = run_query.(query_def)
IO.puts(query_result)
end)
end
iex(6)> async_query.("query 1")
#PID<0.52.0>
query 1 result ❶
This code demonstrates an important technique: passing data to the created process. Notice that async_query takes one argument and binds it to the query_def variable. This data is then passed to the newly created process via the closure mechanism. The inner lambda—the one that runs in a separate process—references the variable query_def from the outer scope. This results in cross-process data passing; the contents of query_def are passed from the main process to the newly created one. When it’s passed to another process, the data is deep copied because two processes can’t share any memory.
Note In BEAM, everything runs in a process. This also holds for the interactive shell. All expressions you enter in iex are executed in a single shell-specific process. In this example, the main process is the shell process.
Now that you have the async_query lambda in place, you can try to run five queries concurrently:
iex(7)> Enum.each(1..5, &async_query.("query #{&1}"))
:ok ❶
query 1 result ❷
query 2 result ❷
query 3 result ❷
query 4 result ❷
query 5 result ❷
As expected, the call to Enum.each/2 now returns immediately (in the first sequential version, you had to wait 10 seconds for it to finish). Moreover, all the results are printed at practically the same time, 2 seconds later, which is a five-fold improvement over the sequential version. This happens because you run each computation concurrently.
For the same reason, the order of execution isn’t deterministic. The output results can be printed in any order.
In contrast to the sequential version, the caller process doesn’t get the result of the spawned processes. The processes run concurrently, each one printing the result to the screen. At the same time, the caller process runs independently and has no access to any data from the spawned processes. Remember, processes are completely independent and isolated.
Often, a simple “fire-and-forget” concurrent execution, where the caller process doesn’t receive any notification from the spawned ones, will suffice. Sometimes, though, you’ll want to return the result of the concurrent operation to the caller process. For this purpose, you can use the message-passing mechanism.
5.2.2 Message passing
In complex systems, you often need concurrent tasks to cooperate in some way. For example, you may have a main process that spawns multiple concurrent calculations, and then you may want to handle all the results in the main process.
Being completely isolated, processes can’t use shared data structures to exchange knowledge. Instead, processes communicate via messages, as illustrated in figure 5.2.
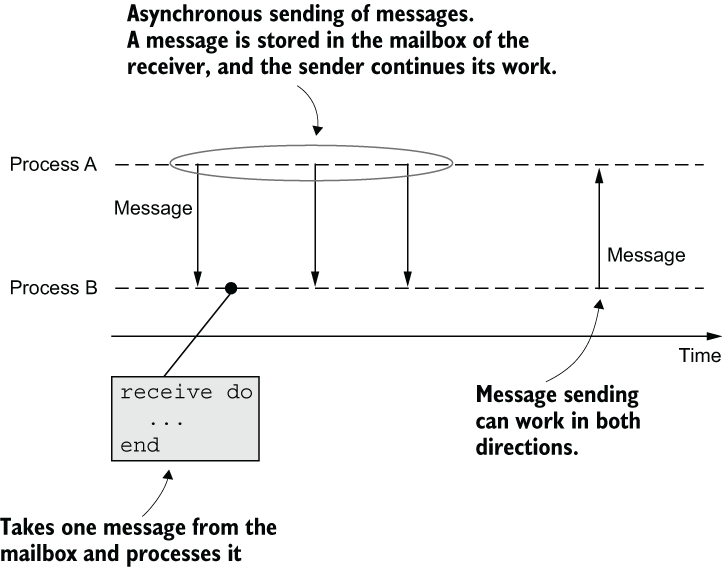
Figure 5.2 Inter-process communication via messages
When process A wants process B to do something, it sends an asynchronous message to B. The content of the message is an Elixir term—anything you can store in a variable. Sending a message amounts to storing it into the receiver’s mailbox. The caller then continues with its own execution, and the receiver can pull the message in at any time and process it in some way. Because processes can’t share memory, a message is deep copied when it’s sent.
The process mailbox is a FIFO queue limited only by the available memory. The receiver consumes messages in the order received, and a message can be removed from the queue only if it’s consumed.
To send a message to a process, you need to have access to its process identifier (PID). Recall from the previous section that the PID of the newly created process is the result of the spawn/1 function. In addition, you can obtain the PID of the current process by calling the auto-imported self/0 function.
Once you have a receiver’s PID, you can send it messages using the Kernel.send/2 function:
send(pid, {:an, :arbitrary, :term})
The consequence of send is that a message is placed in the mailbox of the receiver. The caller process then continues running subsequent expressions.
On the receiver side, to pull a message from the mailbox, you must use the receive expression:
receive do pattern_1 -> do_something pattern_2 -> do_something_else end
The receive expression works similarly to the case expression you saw in chapter 3. It tries to pull one message from the process mailbox, match it against any of the provided patterns, and run the corresponding code. You can easily test this by forcing the shell process to send messages to itself:
iex(1)> send(self(), "a message") ❶ iex(2)> receive do ❷ message -> IO.inspect(message) ❷ end ❷ "a message"
If you want to handle a specific message, you can rely on pattern matching:
iex(3)> send(self(), {:message, 1})
iex(4)> receive do
{:message, id} -> ❶
IO.puts("received message #{id}")
end
received message 1
If there are no messages in the mailbox, receive waits indefinitely for a new message to arrive. The following call blocks the shell, and you need to manually terminate it:
iex(5)> receive do
message -> IO.inspect(message)
end ❶
❶ The shell is blocked because the process mailbox is empty.
The same thing happens if no message in the mailbox matches the provided patterns:
iex(1)> send(self(), {:message, 1})
iex(2)> receive do
{_, _, _} -> ❶
IO.puts("received")
end ❷
❶ This doesn’t match the sent message.
If you don’t want receive to block, you can specify the after clause, which is executed if a message isn’t received in a given time frame (in milliseconds):
iex(1)> receive do
message -> IO.inspect(message)
after
5000 -> IO.puts("message not received")
end
message not received ❶
Recall from chapter 3 that an error is raised when you can’t pattern-match the given term. The receive expression is an exception to this rule. If a message doesn’t match any of the provided clauses, it’s put back into the process mailbox and the next message is processed.
The receive expression works as follows:
-
Try to match it against any of the provided patterns, going from top to bottom.
-
If a pattern matches the message, run the corresponding code.
-
If no pattern matches, take the next message, and start from step 2.
-
If there are no more messages in the queue, wait for a new one to arrive. When a new message arrives, start from step 2.
-
If the
afterclause is specified and no message is matched in the given amount of time, run the code from theafterblock.
As you already know, each Elixir expression returns a value, and receive is no different. The result of receive is the result of the last expression in the appropriate clause:
iex(1)> send(self(), {:message, 1})
iex(2)> receive_result =
receive do
{:message, x} ->
x + 2 ❶
end
iex(3)> IO.inspect(receive_result)
3
To summarize, receive tries to find the first (oldest) message in the process mailbox that can be matched against any of the provided patterns. If such a message is found, the corresponding code is executed. Otherwise, receive waits for such a message for a specified amount of time or indefinitely if the after clause isn’t provided.
The basic message-passing mechanism is the asynchronous “fire-and-forget” kind. A process sends a message and then continues to run, oblivious to what happens in the receiver. Sometimes, a caller needs some kind of response from the receiver. There’s no special support for doing this. Instead, you must program both parties to cooperate using the basic asynchronous messaging facility.
The caller must include its own PID in the message contents and then wait for a response from the receiver:
send(pid, {self(), some_message}) ❶
receive do
{:response, response} -> ... ❷
end
❶ Includes caller PID in the message
The receiver uses the included PID to send the response to the caller:
receive do
{caller_pid, message} ->
response = ...
send(caller_pid, {:response, response}) ❶
end
❶ Sends the response to the caller
You’ll see this in action a bit later, when we discuss server processes.
Let’s try message passing with the concurrent queries developed in the previous section. In the previous attempt, you ran queries in separate processes and printed them to the screen from those processes. Let’s recall how this works:
iex(1)> run_query =
fn query_def ->
Process.sleep(2000)
"#{query_def} result"
end
iex(2)> async_query =
fn query_def ->
spawn(fn ->
query_result = run_query.(query_def)
IO.puts(query_result)
end)
end
Now, instead of printing to the screen, let’s collect all the results in the main process. First, you need to make the lambda send the query result to the caller process:
iex(3)> async_query =
fn query_def ->
caller = self() ❶
spawn(fn ->
query_result = run_query.(query_def)
send(caller, {:query_result, query_result}) ❷
end)
end
❶ Stores the PID of the calling process
❷ Responds to the calling process
In this code, you first store the PID of the calling process to a distinct caller variable. This is necessary to allow the worker process (the one doing the calculation) to know the PID of the process that should receive the response.
Keep in mind that the result of self/0 depends on the calling process. If you didn’t store the result to the caller variable and you tried to send(self(), ...) from the inner lambda, it would have no effect. The spawned process would send the message to itself because calling self/0 returns the PID of the process that invoked the function.
The worker process can now use the caller variable to return the result of the calculation. The message is in the custom format {:query_result, result}. This makes it possible to distinguish between your messages and any others that might be sent to the caller process.
Now, you can start your queries:
iex(4)> Enum.each(1..5, &async_query.("query #{&1}"))
This runs all the queries concurrently, and the result is stored in the mailbox of the caller process. In this case, this is the shell (iex) process.
Notice that the caller process is neither blocked nor interrupted while receiving messages. Sending a message doesn’t disturb the receiving process in any way. If the process is performing computations, it continues to do so. The only thing affected is the content of the receiving process’s mailbox. Messages remain in the mailbox until they’re consumed or the process terminates.
Let’s get the results. First, you make a lambda that pulls one message from the mailbox and extracts the query result from it:
iex(5)> get_result =
fn ->
receive do
{:query_result, result} -> result
end
end
Now, you can pull all the messages from the mailbox into a single list:
iex(6)> results = Enum.map(1..5, fn _ -> get_result.() end) ["query 3 result", "query 2 result", "query 1 result", "query 5 result", "query 4 result"]
Notice the use of Enum.map/2, which maps anything enumerable to a list of the same length. In this case, you create a range of size 5 and then map each element to the result of the get_result lambda. This works because you know there are five messages waiting for you. Otherwise, the loop would get stuck waiting for new messages to arrive.
It’s also worth repeating that results arrive in a nondeterministic order. Because all computations run concurrently, it’s not certain in which order they’ll finish.
This is a simple implementation of a parallel map technique that can be used to process a large amount of work in parallel and then collect the results into a list. This idea can be expressed with a pipeline:
iex(7)> 1..5
|> Enum.map(&async_query.("query #{&1}")) ❶
|> Enum.map(fn _ -> get_result.() end) ❷
❶ Starts concurrent computations
5.3 Stateful server processes
Spawning processes to perform one-off tasks isn’t the only use case for concurrency. In Elixir, it’s common to create long-running processes that can serve various requests, sent in the form of messages. In addition, such processes may maintain some internal state—an arbitrary piece of data that may change over time.
We call such processes stateful server processes, and they are an important concept in Elixir and Erlang systems, so we’ll spend some time exploring them.
5.3.1 Server processes
A server process is an informal name for a process that runs for a long time (or forever) and can handle various requests (messages). To make a process run forever, you must use endless tail recursion. You may remember from chapter 3 that tail calls receive special treatment. If the last thing a function does is call another function (or itself), a simple jump takes place instead of a stack push. Consequently, a function that always calls itself will run forever, without causing a stack overflow or consuming additional memory.
This can be used to implement a server process. You need to run the endless loop and wait for a message in each step of the loop. When the message is received, you handle it and then continue the loop. Let’s try this by creating a server process that can run a query on demand.
The basic sketch of a long-running server process is provided in the following listing.
Listing 5.1 Long-running server process (database_server.ex)
defmodule DatabaseServer do
def start do
spawn(&loop/0) ❶
end
defp loop do
receive do ❷
... ❷
end ❷
loop() ❸
end
...
end
❶ Starts the loop concurrently
start/0 is the so-called interface function used by clients to start the server process. When start/0 is called, it spawns the process that runs the loop/0 function. This function powers the infinite loop of the process. The function waits for a message, handles it, and then calls itself, ensuring the process never stops.
Such implementation is what makes this process a server. Instead of actively running some computation, the process is mostly idle, waiting for the message (request) to arrive. It’s worth noting that this loop isn’t CPU intensive. Waiting for a message puts the process in a suspended state and doesn’t waste CPU cycles.
Notice that functions in this module run in different processes. The function start/0 is called by clients and runs in a client process. The private function loop/0 runs in the server process. It’s perfectly normal to have different functions from the same module running in different processes—there’s no special relationship between modules and processes. A module is just a collection of functions, and these functions can be invoked in any process.
When implementing a server process, it usually makes sense to put all of its code in a single module. The functions of this module generally fall into two categories: interface and implementation. Interface functions are public and are executed in the caller process. They hide the details of process creation and the communication protocol. Implementation functions are usually private and run in the server process.
Note As was the case with classical loops, you typically won’t need to code the recursion loop yourself. A standard abstraction called GenServer (generic server process) is provided, which simplifies the development of stateful server processes. The abstraction still relies on recursion, but this recursion is implemented in GenServer. You’ll learn about this abstraction in chapter 6.
Let’s look at the full implementation of the loop/0 function.
Listing 5.2 Database server loop (database_server.ex)
defmodule DatabaseServer do
...
defp loop do
receive do ❶
{:run_query, caller, query_def} ->
query_result = run_query(query_def) ❷
send(caller, {:query_result, query_result}) ❷
end
loop()
end
defp run_query(query_def) do ❸
Process.sleep(2000)
"#{query_def} result"
end
...
end
❷ Runs the query and sends the response to the caller
This code reveals the communication protocol between the caller process and the database server. The caller sends a message in the format {:run_query, caller, query_def}. The server process handles such a message by executing the query and sending the query result back to the caller process.
Usually, you want to hide these communication details from clients. Clients shouldn’t depend on knowing the exact structure of messages that must be sent or received. To hide this, it’s best to provide a dedicated interface function. Let’s introduce a function called run_async/2, which will be used by clients to request the operation—in this case, a query execution—from the server. This function makes the clients unaware of message-passing details; they just call run_async/2 and get the result. The implementation is given in the following listing.
Listing 5.3 Implementation of run_async/2 (database_server.ex)
defmodule DatabaseServer do
...
def run_async(server_pid, query_def) do
send(server_pid, {:run_query, self(), query_def})
end
...
end
The run_async/2 function receives the PID of the database server and a query you want to execute. It sends the appropriate message to the server and then does nothing else. Calling run_async/2 from the client requests the server process to run the query while the caller goes about its business.
Once the query is executed, the server sends a message to the caller process. To get this result, you need to add another interface function: get_result/0.
Listing 5.4 Implementation of get_result/0 (database_server.ex)
defmodule DatabaseServer do
...
def get_result do
receive do
{:query_result, result} -> result
after
5000 -> {:error, :timeout}
end
end
...
end
get_result/0 is called when the client wants to get the query result. Here, you use receive to get the message. The after clause ensures that you give up after some time passes (e.g., if something goes wrong during the query execution and a response never comes back).
The database server is now complete. Let’s see how to use it:
iex(1)> server_pid = DatabaseServer.start() iex(2)> DatabaseServer.run_async(server_pid, "query 1") iex(3)> DatabaseServer.get_result() "query 1 result" iex(4)> DatabaseServer.run_async(server_pid, "query 2") iex(5)> DatabaseServer.get_result() "query 2 result"
Notice how you execute multiple queries in the same process. First, you run query 1, and then query 2. This proves the server process continues running after a message is received.
Because communication details are wrapped in functions, the client isn’t aware of them. Instead, it communicates with the process with plain functions. Here, the server PID plays an important role. You receive the PID by calling DatabaseServer.start/0, and then you use it to issue requests to the server.
Of course, the request is handled asynchronously in the server process. After calling DatabaseServer.run_async/2, you can do whatever you want in the client (iex) process and collect the result when you need it.
Server processes are sequential
It’s important to realize that a server process is internally sequential. It runs a loop that processes one message at a time. Thus, if you issue five asynchronous query requests to a single server process, they will be handled one by one, and the result of the last query will come after 10 seconds.
This is a good thing because it helps you reason about the system. A server process can be considered a synchronization point. If several actions need to happen synchronously, in a serialized manner, you can introduce a single process and forward all requests to that process, which handles the requests sequentially.
Of course, in this case, a sequential property is a problem. You want to run multiple queries concurrently to get the result as quickly as possible. What can you do about it?
Assuming the queries can be run independently, you can start a pool of server processes, and then for each query, you can somehow choose one of the processes from the pool and have that process run the query. If the pool is large enough and you divide the work uniformly across each worker in the pool, you’ll parallelize the total work as much as possible.
Here’s a basic sketch of how this can be done. First, create a pool of database-server processes:
iex(1)> pool = Enum.map(1..100, fn _ -> DatabaseServer.start() end)
Here, you create 100 database-server processes and store their PIDs in a list. You may think 100 processes is a lot, but recall that processes are lightweight. They take up a small amount of memory (~2 KB) and are created very quickly (in a few microseconds). Furthermore, because all of these processes wait for a message, they’re effectively idle and don’t waste CPU time.
Next, when you run a query, you need to decide which process will execute the query. The simplest way is to use the :rand.uniform/1 function, which takes a positive integer n and returns a random number in the range 1..n. Taking advantage of this, the following expression distributes five queries over a pool of processes:
iex(2)> Enum.each(
1..5,
fn query_def ->
server_pid = Enum.at(pool, :rand.uniform(100) - 1) ❶
DatabaseServer.run_async(server_pid, query_def) ❷
end
)
Note that this isn’t efficient; you’re using Enum.at/2 to choose a random PID. Because you use a list to keep the processes, and a random lookup is an O(n) operation, selecting a random worker isn’t very performant. You could do better if you used a map with process indexes as keys and PIDs as values. There are also several alternative approaches, such as using a round-robin approach. But for now, let’s stick with this simple implementation.
Once you’ve queued the queries to the workers, you need to collect the responses. This is now straightforward, as illustrated in the following snippet:
iex(3)> Enum.map(1..5, fn _ -> DatabaseServer.get_result() end) ["5 result", "3 result", "1 result", "4 result", "2 result"]
Thanks to this, you get all the results much faster because queries are, again, executed concurrently.
5.3.2 Keeping a process state
Server processes open the possibility of keeping some kind of process-specific state. For example, when you talk to a database, you need to maintain a connection handle.
To keep state in the process, you can extend the loop function with additional argument(s). Here’s a basic sketch:
def start do
spawn(fn ->
initial_state = ... ❶
loop(initial_state) ❷
end)
end
defp loop(state) do
...
loop(state) ❸
end
❶ Initializes the state during process creation
❷ Enters the loop with that state
❸ Keeps the state during the loop
Let’s use this technique to extend the database server with a connection. In this example, you’ll use a random number as a simulation of the connection handle. First, you need to initialize the connection while the process starts, as demonstrated in the following listing.
Listing 5.5 Initializing the process state (stateful_database_server.ex)
defmodule DatabaseServer do
...
def start do
spawn(fn ->
connection = :rand.uniform(1000)
loop(connection)
end)
end
...
end
Here, you open the connection and then pass the corresponding handle to the loop function. In real life, instead of generating a random number, you’d use a database client library (e.g., ODBC) to open the connection.
Next, you need to modify the loop function.
Listing 5.6 Using the connection while querying (stateful_database_server.ex)
defmodule DatabaseServer do
...
defp loop(connection) do
receive do
{:run_query, from_pid, query_def} ->
query_result = run_query(connection, query_def) ❶
send(from_pid, {:query_result, query_result})
end
loop(connection) ❷
end
defp run_query(connection, query_def) do
Process.sleep(2000)
"Connection #{connection}: #{query_def} result"
end
...
end
❶ Uses the connection while running the query
❷ Keeps the connection in the loop argument
The loop function takes the state (connection) as the first argument. Every time the loop is resumed, the function passes on the state to itself, so it is available in the next step.
Additionally, you must extend the run_query function to use the connection while querying the database. The connection handle (in this case, a number) is included in the query result.
With this, your stateful database server is complete. Notice that you didn’t change the interface of its public functions, so the usage remains the same as it was. Let’s see how it works:
iex(1)> server_pid = DatabaseServer.start() iex(2)> DatabaseServer.run_async(server_pid, "query 1") iex(3)> DatabaseServer.get_result() "Connection 753: query 1 result" iex(4)> DatabaseServer.run_async(server_pid, "query 2") iex(5)> DatabaseServer.get_result() "Connection 753: query 2 result"
The results for different queries are executed using the same connection handle, which is kept internally in the process loop and is completely invisible to other processes.
5.3.3 Mutable state
So far, you’ve seen how to keep constant process-specific state. It doesn’t take much to make this state mutable. Here’s the basic idea:
defp loop(state) do new_state = ❶ receive do msg1 -> ... msg2 -> ... end loop(new_state) ❷ end
❶ Computes the new state based on the message
This is a standard, stateful server technique in Elixir. The process determines the new state while handling the message. Then, the loop function calls itself with the new state, which, effectively, changes the state. The next received message operates on the new state.
From the outside, stateful processes are mutable. By sending messages to a process, a caller can affect its state and the outcome of subsequent requests handled in that server. In that sense, sending a message is an operation with possible side effects. Still, the server relies on immutable data structures. A state can be any valid Elixir variable, ranging from simple numbers to complex data abstractions, such as TodoList (which you built in chapter 4).
Let’s see this in action. You’ll start with a simple example: a stateful calculator process that keeps a number as its state. Initially, the state of the process is 0, and you can manipulate it by issuing requests such as add, sub, mul, and div. You can also retrieve the process state with the value request.
Here’s how you use the server:
iex(1)> calculator_pid = Calculator.start() ❶ iex(2)> Calculator.value(calculator_pid) ❷ 0 ❷ iex(3)> Calculator.add(calculator_pid, 10) ❸ iex(4)> Calculator.sub(calculator_pid, 5) ❸ iex(5)> Calculator.mul(calculator_pid, 3) ❸ iex(6)> Calculator.div(calculator_pid, 5) ❸ iex(7)> Calculator.value(calculator_pid) ❹ 3.0
In this code, you start the process and check its initial state. Then, you issue some modifier requests and verify the result of the operations (((0 + 10) - 5) * 3) / 5, which is 3.0.
Now, it’s time to implement this. First, let’s look at the server’s inner loop.
Listing 5.7 Concurrent stateful calculator (calculator.ex)
defmodule Calculator do
...
defp loop(current_value) do
new_value =
receive do
{:value, caller} -> ❶
send(caller, {:response, current_value}) ❶
current_value ❶
{:add, value} -> current_value + value ❷
{:sub, value} -> current_value - value ❷
{:mul, value} -> current_value * value ❷
{:div, value} -> current_value / value ❷
invalid_request -> ❸
IO.puts("invalid request #{inspect invalid_request}") ❸
current_value ❸
end
loop(new_value)
end
...
end
❷ Arithmetic operations requests
The loop handles various messages. The :value message is used to retrieve the server’s state. Because you need to send the response back, the caller must include its PID in the message. Notice that the last expression of this block returns current_value. This is needed because the result of receive is stored in new_value, which is then used as the server’s new state. By returning current_value, you specify that the :value request doesn’t change the process state.
The arithmetic operations compute the new state based on the current value and the argument received in the message. Unlike a :value message handler, arithmetic operation handlers don’t send responses back to the caller. This makes it possible to run these operations asynchronously, as you’ll see soon when you implement interface functions.
The final receive clause matches all the other messages. These are the ones you’re not supporting, so you log them to the screen and return current_value, leaving the state unchanged.
Next, you need to implement the interface functions that will be used by clients. This is done in the next listing.
Listing 5.8 Calculator interface functions (calculator.ex)
defmodule Calculator do def start do ❶ spawn(fn -> loop(0) end) ❶ end ❶ def value(server_pid) do ❷ send(server_pid, {:value, self()}) ❷ ❷ receive do ❷ {:response, value} -> ❷ value ❷ end ❷ end ❷ def add(server_pid, value), do: send(server_pid, {:add, value}) ❸ def sub(server_pid, value), do: send(server_pid, {:sub, value}) ❸ def mul(server_pid, value), do: send(server_pid, {:mul, value}) ❸ def div(server_pid, value), do: send(server_pid, {:div, value}) ❸ ... end
❶ Starts the server and initializes the state
The interface functions follow the protocol specified in the loop/1 function. The :value request is an example of the synchronous message passing mentioned in section 5.2.2. The caller sends a message, and then it awaits the response. The caller is blocked until the response comes back, which makes the request handling synchronous.
The arithmetic operations run asynchronously. There’s no response message, so the caller doesn’t need to wait for anything. Therefore, a caller can issue several of these requests and continue doing its own work while the operations run concurrently in the server process. Keep in mind that the server handles messages in the order received, so requests are handled in the proper order.
Why make the arithmetic operations asynchronous? Because you don’t care when they’re executed. Until you request the server’s state (via the value/1 function), you don’t want the client to block. This makes the client more efficient because it doesn’t block while the server is doing a computation.
As you introduce multiple requests to your server, the loop function becomes more complex. If you have to handle many requests, it will become bloated, turning into a huge switch/case-like expression.
You can refactor this by relying on pattern matching and moving the message handling to a separate multiclause function. This keeps the code of the loop function very simple:
defp loop(current_value) do
new_value =
receive do
message -> process_message(current_value, message)
end
loop(new_value)
end
Looking at this code, you can see the general workflow of the server. A message is first received and then processed. Message processing generally amounts to computing the new state based on the current state and the message received. Finally, you loop with this new state, effectively setting it in place of the old one.
process_message/2 is a simple multiclause function that receives the current state and the message. Its task is to perform message-specific code and return the new state:
defp process_message(current_value, {:value, caller}) do
send(caller, {:response, current_value})
current_value
end
defp process_message(current_value, {:add, value}) do
current_value + value
end
...
This code is a simple reorganization of the server process loop. It allows you to keep the loop code compact and move the message-handling details to a separate multiclause function, with each clause handling a specific message.
5.3.4 Complex states
State is usually much more complex than a simple number. However, the technique always remains the same: you keep the mutable state using the private loop function. As the state becomes more complex, the code of the server process can become increasingly complicated. It’s worth extracting the state manipulation to a separate module and keeping the server process focused only on passing messages and keeping the state.
Let’s look at this technique using the TodoList abstraction developed in chapter 4. First, let’s recall the basic usage of the structure:
iex(1)> todo_list =
TodoList.new() |>
TodoList.add_entry(%{date: ~D[2023-12-19], title: "Dentist"}) |>
TodoList.add_entry(%{date: ~D[2023-12-20], title: "Shopping"}) |>
TodoList.add_entry(%{date: ~D[2023-12-19], title: "Movies"})
iex(2)> TodoList.entries(todo_list, ~D[2023-12-19])
[
%{date: ~D[2023-12-19], id: 1, title: "Dentist"},
%{date: ~D[2023-12-19], id: 3, title: "Movies"}
]
As you may recall, a TodoList is a pure functional abstraction. To keep the structure alive, you must constantly hold on to the result of the last operation performed on the structure.
In this example, you’ll build a TodoServer module that keeps this abstraction in the private state. Let’s see how the server is used:
iex(1)> todo_server = TodoServer.start()
iex(2)> TodoServer.add_entry(
todo_server,
%{date: ~D[2023-12-19], title: "Dentist"}
)
iex(3)> TodoServer.add_entry(
todo_server,
%{date: ~D[2023-12-20], title: "Shopping"}
)
iex(4)> TodoServer.add_entry(
todo_server,
%{date: ~D[2023-12-19], title: "Movies"}
)
iex(5)> TodoServer.entries(todo_server, ~D[2023-12-19])
[
%{date: ~D[2023-12-19], id: 3, title: "Movies"},
%{date: ~D[2023-12-19], id: 1, title: "Dentist"}
]
You start the server and then interact with it via the TodoServer API. In contrast to the pure functional approach, you don’t need to take the result of a modification and feed it as an argument to the next operation. Instead, you constantly use the same todo_server variable to work with the to-do list.
Let’s start implementing this server. First, you need to place all the modules in a single file.
Listing 5.9 TodoServer modules (todo_server.ex)
defmodule TodoServer do ... end defmodule TodoList do ... end
Putting both modules in the same file ensures that you have everything available when you load the file while starting the iex shell. In more complicated systems, you’d use a proper Mix project, as will be explained in chapter 7, but for now, this is sufficient.
The TodoList implementation is the same as in chapter 4. It has all the features you need to use it in a server process.
Now, set up the basic structure of the to-do server process.
Listing 5.10 TodoServer basic structure (todo_server.ex)
defmodule TodoServer do
def start do
spawn(fn -> loop(TodoList.new()) end) ❶
end
defp loop(todo_list) do
new_todo_list =
receive do
message -> process_message(todo_list, message)
end
loop(new_todo_list)
end
...
end
❶ Uses a to-do list as the initial state
There’s nothing new here. You start the loop using a new instance of the TodoList abstraction as the initial state. In the loop, you receive messages and apply them to the state by calling the process_message/2 function, which returns the new state. Finally, you loop with the new state.
For each request you want to support, you must add a dedicated clause in the process_message/2 function. Additionally, a corresponding interface function must be introduced. You’ll begin by supporting the add_entry request.
Listing 5.11 The add_entry request (todo_server.ex)
defmodule TodoServer do ... def add_entry(todo_server, new_entry) do ❶ send(todo_server, {:add_entry, new_entry}) ❶ end ❶ ... defp process_message(todo_list, {:add_entry, new_entry}) do ❷ TodoList.add_entry(todo_list, new_entry) ❷ end ❷ ... end
The interface function sends the new entry data to the server. This message will be handled in the corresponding clause of process_message/2. Here, you delegate to the TodoList.add_entry/2 function and return the modified TodoList instance. This returned instance is used as the new server’s state.
Using a similar approach, you can implement the entries request, keeping in mind that you need to wait for the response message. The code is shown in the next listing.
Listing 5.12 The entries request (todo_server.ex)
defmodule TodoServer do
...
def entries(todo_server, date) do
send(todo_server, {:entries, self(), date})
receive do
{:todo_entries, entries} -> entries
after
5000 -> {:error, :timeout}
end
end
...
defp process_message(todo_list, {:entries, caller, date}) do
send(caller, {:todo_entries, TodoList.entries(todo_list, date)}) ❶
todo_list ❷
end
...
end
❶ Sends the response to the caller
❷ The state remains unchanged.
This is a synthesis of techniques you’ve seen previously. You send a message and wait for the response. In the corresponding process_message/2 clause, you delegate to TodoList, and then you send the response and return the unchanged to-do list. This is needed because loop/2 takes the result of process_message/2 as the new state.
In a similar way, you can add support for other to-do list requests, such as update_entry and delete_entry. The implementation of these requests is left for you as an exercise.
Concurrent vs. functional approach
A process that maintains mutable state can be regarded as a kind of mutable data structure. But you shouldn’t abuse processes to avoid using the functional approach of transforming immutable data.
The data should be modeled using pure functional abstractions, just as you did with TodoList. A pure functional data structure provides many benefits, such as integrity, atomicity, reusability, and testability.
A stateful process serves as a container of such a data structure. The process keeps the state alive and allows other processes in the system to interact with this data via the exposed API.
With such separation of responsibilities, building a highly concurrent system becomes straightforward. For example, if you’re implementing a web server that manages multiple to-do lists, you could run one server process for each to-do list. While handling an HTTP request, you can find the corresponding to-do server and have it perform the requested operation. Each to-do list manipulation runs concurrently, thus making your server scalable and more performant. Moreover, there are no synchronization problems because each to-do list is managed in a dedicated process. Recall that a single process is always sequential, so multiple competing requests that manipulate the same to-do list are serialized and handled sequentially in the corresponding process. Don’t worry if this seems vague—you’ll see it in action in chapter 7.
5.3.5 Registered processes
For a process to cooperate with other processes, it must know their whereabouts. In BEAM, a process is identified by its corresponding PID. To make process A send messages to process B, you must bring the PID of process B to process A.
Sometimes, it can be cumbersome to keep and pass PIDs. If you know there will always be only one instance of some type of server, you can give the process a local name and use that name to send messages to the process. The name is called local because it has meaning only in the currently running BEAM instance. This distinction becomes important when you start connecting multiple BEAM instances to a distributed system, as you’ll see in chapter 12.
Registering a process can be done with Process.register(pid, name), where a name must be an atom. Here’s a quick illustration:
iex(1)> Process.register(self(), :some_name) ❶ iex(2)> send(:some_name, :msg) ❷ iex(3)> receive do ❸ msg -> IO.puts("received #{msg}") end received msg
❷ Sends a message via a symbolic name
❸ Verifies that the message is received
The following constraints apply to registered names:
If these constraints aren’t met, an error is raised.
For practice, try to change the to-do server to run as a registered process. The interface of the server will then be simplified because you don’t need to keep and pass the server’s PID.
Here’s an example of how such a server can be used:
iex(1)> TodoServer.start()
iex(2)> TodoServer.add_entry(%{date: ~D[2023-12-19], title: "Dentist"})
iex(3)> TodoServer.add_entry(%{date: ~D[2023-12-20], title: "Shopping"})
iex(4)> TodoServer.add_entry(%{date: ~D[2023-12-19], title: "Movies"})
iex(5)> TodoServer.entries(~D[2023-12-19])
[%{date: ~D[2023-12-19], id: 3, title: "Movies"},
%{date: ~D[2023-12-19], id: 1, title: "Dentist"}]
To make this work, you must register a server process under a name (e.g., :todo_ server). Then, you change all the interface functions to use the registered name when sending a message to the process. If you get stuck, the solution is provided in the registered_todo_server.ex file.
Using the registered server is much simpler because you don’t have to store the server’s PID and pass it to the interface functions. Instead, the interface functions internally use the registered name to send messages to the process.
Local registration plays an important role in process discovery. Registered names provide a way of communicating with a process without knowing its PID. This becomes increasingly important when you start dealing with restarting processes (as you’ll see in chapters 8 and 9) and distributed systems (discussed in chapter 12).
This concludes our initial exploration of stateful processes. They play an important role in Elixir-based systems, and you’ll continue using them throughout the book. Next, we’ll look at some important runtime properties of BEAM processes.
5.4 Runtime considerations
You’ve learned a great deal about how to work with processes. Now, its time to discuss some important runtime properties of BEAM concurrency.
5.4.1 A process is sequential
It has already been mentioned, but it’s very important, so I’ll stress it again: a single process is a sequential program—it runs expressions in a sequence one by one. Multiple processes run concurrently, so they may run in parallel with each other. But if many processes send messages to a single process, that single process may become a bottleneck, which significantly affects overall throughput of the system.
Let’s look at an example. The code in the following listing implements a slow echo server.
Listing 5.13 Demonstration of a process bottleneck (process_bottleneck.ex)
defmodule Server do
def start do
spawn(fn -> loop() end)
end
def send_msg(server, message) do
send(server, {self(), message})
receive do
{:response, response} -> response
end
end
defp loop do
receive do
{caller, msg} ->
Process.sleep(1000) ❶
send(caller, {:response, msg}) ❷
end
loop()
end
end
Upon receiving a message, the server sends the message back to the caller. Before that, it sleeps for a second to simulate a long-running request.
To test its behavior in a concurrent setting, start the server and fire up five concurrent clients:
iex(1)> server = Server.start()
iex(2)> Enum.each(
1..5,
fn i ->
spawn(fn -> ❶
IO.puts("Sending msg ##{i}")
response = Server.send_msg(server, i) ❷
IO.puts("Response: #{response}")
end)
end
)
❷ Synchronous request to the server
As soon as you start this, you’ll see the following lines printed:
Sending msg #1 Sending msg #2 Sending msg #3 Sending msg #4 Sending msg #5
So far, so good. Five processes have been started and are running concurrently. But now, the problems begin—the responses come back slowly, one by one, a second apart:
Response: 1 ❶ Response: 2 ❷ Response: 3 ❸ Response: 4 ❹ Response: 5 ❺
What happened? The echo server can handle only one message per second. Because all other processes depend on the echo server, they’re constrained by its throughput.
What can you do about this? Once you identify the bottleneck, you should try to optimize the process internally. Generally, a server process has a simple flow. It receives and handles messages one by one. So the goal is to make the server handle messages at least as fast as they arrive. In this example, server optimization amounts to removing the Process.sleep/1 call.
If you can’t make message handling fast enough, you can try to split the server into multiple processes, effectively parallelizing the original work and hoping that doing so will boost performance on a multicore system. This should be your last resort, though. Parallelization isn’t a remedy for a poorly structured algorithm.
5.4.2 Unlimited process mailboxes
Theoretically, a process mailbox has unlimited size. In practice, though, the mailbox size is limited by available memory. Thus, if a process constantly falls behind, meaning messages arrive faster than the process can handle them, the mailbox will constantly grow and increasingly consume memory. Ultimately, a single slow process may cause an entire system to crash by consuming all the available memory.
A more subtle version of the same problem occurs if a process doesn’t handle some messages at all. Consider the following server loop:
defp loop
receive do
{:message, msg} -> do_something(msg)
end
loop()
end
A server powered by this loop only handles messages in the following form: {:message, something}. All other messages remain in the process mailbox forever, taking up memory space for no reason.
Overgrown mailbox contents can significantly affect performance. It puts extra pressure on the garbage collector and can lead to slow pattern matches in receive.
To avoid this, you should introduce a match-all receive clause that deals with unexpected kinds of messages. Typically, you’ll emit a warning that a process has received the unknown message and do nothing else about it:
defp loop
receive
{:message, msg} -> do_something(msg)
other -> warn_about_unknown_message(other) ❶
end
loop()
end
Since the process handles every kind of message, the uncontrolled growth of its mailbox is less likely to happen.
It’s also worth noting that BEAM gives you tools for analyzing processes at run time. In particular, you can query each process for its mailbox size and, thus, detect those for which the mailbox-queue buildup occurs. We’ll discuss this feature in chapter 13.
5.4.3 Shared-nothing concurrency
As already mentioned, processes share no memory. Thus, sending a message to another process results in a deep copy of the message contents:
send(target_pid, data) \ ❶
❶ The contents of data are deep copied.
Less obviously, a variable closure in a spawned element also results in deep copying the closed variable:
data = ...
spawn(fn ->
...
some_fun(data) ❶
...
end)
❶ Results in a deep copy of the data variable
This is something you should be aware of when moving code into a separate process. Deep copying is an in-memory operation, so it should be reasonably fast, and occasionally sending a big message shouldn’t present a problem. But having many processes frequently send big messages may affect system performance. The notion of “small” versus “big” is subjective. Simple data, such as a number, an atom, or a tuple with few elements, is obviously small. On the other hand, a list of a million complex structures is big. The border lies somewhere in between and depends on your specific case.
There are a couple of special cases in which the data is copied by reference. This happens with binaries (including strings) larger than 64 bytes, hardcoded constants (also known as literals), and terms created via the :persistent_term API (https://www.erlang.org/doc/man/persistent_term.xhtml).
Shared-nothing concurrency ensures complete isolation between processes: one process can’t compromise the internal state of another. This promotes the integrity and fault tolerance of the system.
In addition, because processes share no memory, garbage collection can take place on a process level. Each process gets an initial small chunk of heap memory (~2 KB on 64-bit BEAM). When more memory is needed, garbage collection for that process takes place. As a result, garbage collection is concurrent and distributed. Instead of one large “stop-the-entire-system” collection, you end up running many smaller, typically faster, collections. This prevents unwanted long, complete blockages and keeps the entire system more responsive.
5.4.4 Scheduler inner workings
Generally, you can assume there are n schedulers that run m processes, with m most often being significantly larger than n. This is called m:n threading, and it reflects the fact that you run a large number of logical microthreads using a smaller number of OS threads, as illustrated in figure 5.3.
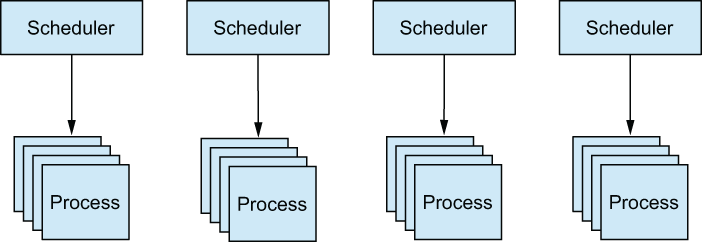
Figure 5.3 m:n threading: A small number of schedulers running a large number of BEAM processes
Each BEAM scheduler is an OS thread that manages the execution of BEAM processes. By default, BEAM uses only as many schedulers as there are logical processors available. You can change these settings via various Erlang emulator flags.
To provide Erlang flags, you can use the following syntax:
$ iex --erl "put Erlang emulator flags here"
A list of all Erlang flags can be found at https://erlang.org/doc/man/erl.xhtml.
For example, to use only one scheduler thread, you can provide the +S 1 Erlang flag:
$ iex --erl "+S 1" Erlang/OTP 26 [erts-14.0] [source] [64-bit] [smp:1:1] [ds:1:1:10]
Notice the smp:1:1 part in the output. This informs us that only one scheduler thread is used. You can also check the number of schedulers programmatically:
iex(1)> System.schedulers() 1
If you’re running other external services on the system, you could consider reducing the number of BEAM scheduler threads. Doing this will leave more computational resources for non-BEAM services.
Internally, each scheduler picks one process, runs it for a while, and then picks another process. While in the scheduler, the process gets a small execution window of approximately 2,000 function calls, after which it’s preempted. It’s also worth mentioning that in some cases, long-running CPU-bound work or a larger garbage collection might be performed on another thread (called a dirty scheduler).
If a process is doing a network IO or waiting for a message, it yields the execution to the scheduler. The same thing happens when Process.sleep is invoked. As a result, you don’t have to care about the nature of the work performed in a process. If you want to separate the execution of one function from the rest of the code, you just need to run that function in a separate process, regardless of whether the work is CPU or IO bound.
As a consequence of all of this, context switching is performed frequently. Typically, a single process is in the scheduler for less than one millisecond. This promotes the responsiveness of BEAM-powered systems. If one process performs a long CPU-bound operation, such as computing the value of pi to a billion decimals, it won’t block the entire scheduler, and other processes shouldn’t be affected.
This can easily be proven. Start an iex session with just one scheduler thread:
$ iex --erl "+S 1"
Spawn a process that runs an infinite CPU-bound loop:
iex(1)> spawn(fn ->
Stream.repeatedly(fn -> :rand.uniform() end)
|> Stream.run()
end)
This code uses Stream.repeatedly/1 to create a lazy infinite stream of random numbers. The stream is executed using Stream.run/1 function, which will effectively run an infinite CPU-bound loop. To avoid blocking the iex shell session, the work is done in a separate process.
As soon as you start this computation, you should notice the CPU usage going to 100%, which proves you’re now running an intensive, long-running CPU-bound work.
Still, even though BEAM is using only one scheduler thread, the iex session is responsive, and you can evaluate other expressions. For example, let’s sum the first 1,000,000,000 integers:
iex(2)> Enum.sum(1..1_000_000_000) 500000000500000000
We were able to run another job on an already busy scheduler thread, and that job finished almost immediately. This is the consequence of frequent context switching, which ensures that an occasional long-running job won’t significantly affect the responsiveness of the entire system.
Summary
-
A BEAM process is a lightweight concurrent unit of execution. Processes are completely isolated and share no memory.
-
Processes can communicate with asynchronous messages. Synchronous sends and responses are manually built on top of this basic mechanism.
-
A server process is a process that runs for a long time (possibly forever) and handles various messages. Server processes are powered by endless recursion.
-
Server processes can maintain their own private state, using the arguments of endless recursion.