9 Isolating error effects
In chapter 8, you learned about the basic theory behind error handling in concurrent systems based on the concept of supervisors. The idea is to have a process whose only job is to supervise other processes and to restart them if they crash. This gives you a way to deal with all sorts of unexpected errors in your system. Regardless of what goes wrong in a worker process, you can be sure that the supervisor will detect an error and restart the worker.
In addition to providing basic error detection and recovery, supervisors play an important role in isolating error effects. By placing individual workers directly under a supervisor, you can confine an error’s impact to a single worker. This has an important benefit: it makes your system more available to its clients. Unexpected errors will occur no matter how hard you try to avoid them. Isolating the effects of such errors allows other parts of the system to run and provide service while you’re recovering from the error.
For example, a database error in this book’s example to-do system shouldn’t stop the cache from working. While you’re trying to recover from whatever went wrong in the database part, you should continue to serve existing cached data, thus providing at least partial service. Going even further, an error in an individual database worker shouldn’t affect other database operations. Ultimately, if you can confine an error’s impact to a small part of the system, your system can provide most of its services all the time.
Isolating errors and minimizing their negative effects is the topic of this chapter. The main idea is to run each worker under a supervisor, which makes it possible to restart each worker individually. You’ll see how this works in the next section, in which you start to build a fine-grained supervision tree.
9.1 Supervision trees
In this section, we’ll discuss how to reduce the effect of an error on the entire system. The basic tools are processes, links, and supervisors, and the general approach is fairly simple. You must always consider what will happen to the rest of the system if a process crashes due to an error, and you should take corrective measures when an error’s impact is too wide (when the error affects too many processes).
9.1.1 Separating loosely dependent parts
Let’s look at how errors are propagated in the to-do system. Links between processes are depicted in figure 9.1.
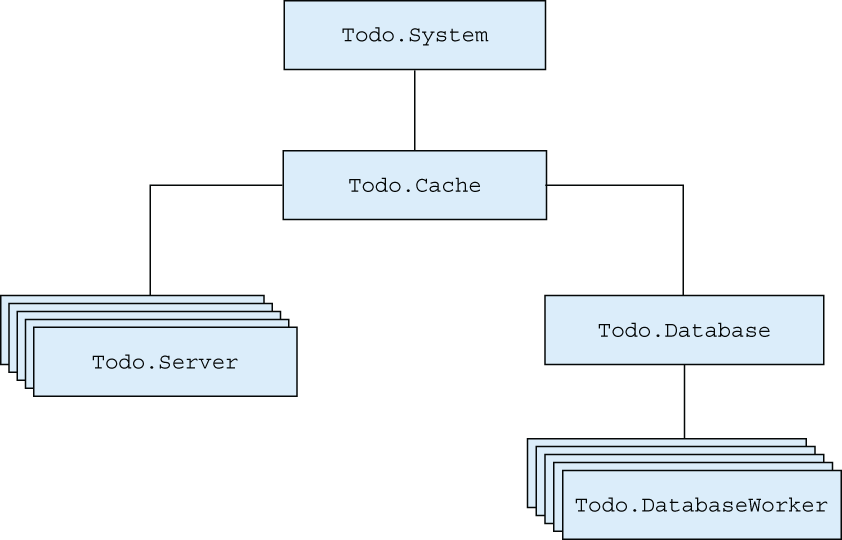
Figure 9.1 Process links in the to-do system
As you can see in the diagram, the entire structure is connected. Regardless of which process crashes, the exit signal will be propagated to its linked processes. Ultimately, the to-do cache process will crash as well, and this will be noticed by the Todo.System, which will, in turn, restart the cache process.
This is a correct error-handling approach because you restart the system and don’t leave behind any dangling processes. But such a recovery approach is too coarse. Wherever an error happens, the entire system is restarted. In the case of a database error, the entire to-do cache will terminate. Similarly, an error in one to-do server process will take down all the database workers.
This coarse-grained error recovery is due to the fact that you’re starting worker processes from within other workers. For example, a database server is started from the to-do cache. To reduce error effects, you need to start individual workers from the supervisor. Such a scheme makes it possible for the supervisor to supervise and restart each worker separately.
Let’s see how to do this. First, you’ll move the database server so that it’s started directly from the supervisor. This will allow you to isolate database errors from those that happen in the cache.
Placing the database server under supervision is simple enough. You must remove the call to Todo.Database.start_link from Todo.Cache.init/1. Then, you must add another child specification when invoking Supervisor.start_link/2.
Listing 9.1 Supervising database server (supervise_database/lib/todo/system.ex)
defmodule Todo.System do
def start_link do
Supervisor.start_link(
[
Todo.Database, ❶
Todo.Cache
],
strategy: :one_for_one
)
end
end
❶ Includes database in the specification list
There’s one more small change that needs to be made. Just like you did with Todo.Cache, you need to adapt Todo.Database.start_link to take exactly one argument and ignore it. This will make it possible to rely on the autogenerated Todo.Database.child_spec/1, obtained by use GenServer.
Listing 9.2 Adapting start_link (supervise_database/lib/todo/database.ex)
defmodule Todo.Database do
...
def start_link(_) do
...
end
...
end
These changes ensure that the cache and the database are separated, as shown in figure 9.2. Running both the database and cache processes under the supervisor makes it possible to restart each worker individually. An error in the database worker will crash the entire database structure, but the cache will remain undisturbed. This means all clients reading from the cache will be able to get their results while the database part is restarting.
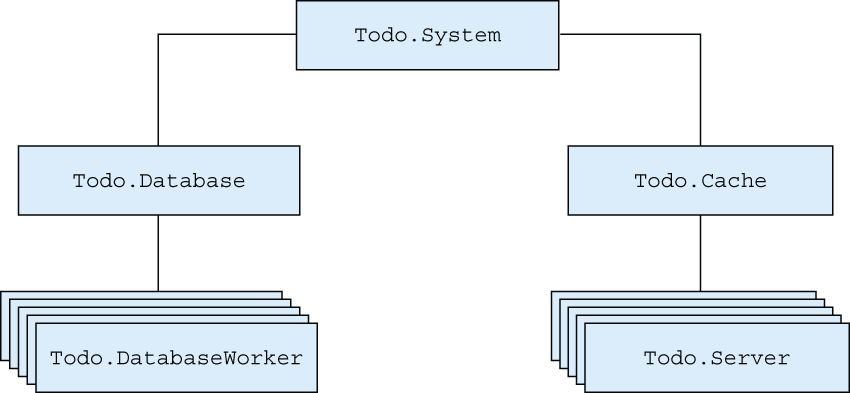
Figure 9.2 Separated supervision of database and cache
Let’s verify this. Go to the supervise_database folder, and start the shell (iex -S mix). Then, start the system:
iex(1)> Todo.System.start_link() Starting database server. Starting database worker. Starting database worker. Starting database worker. Starting to-do cache.
Now, kill the database server:
iex(2)> Process.exit(Process.whereis(Todo.Database), :kill) Starting database server. Starting database worker. Starting database worker. Starting database worker.
As you can see from the output, only database-related processes are restarted. The same is true if you terminate the to-do cache. By placing both processes under a supervisor, you localize the negative impact of an error. A cache error will have no effect on the database part, and vice versa.
Recall chapter 8’s discussion of process isolation. Because each part is implemented in a separate process, the database server and the to-do cache are isolated and don’t affect each other. Of course, these processes are indirectly linked via the supervisor, but the supervisor is trapping exit signals, thus preventing further propagation. This is a property of one_for_one supervisors in particular: they confine an error’s impact to a single worker and take the corrective measure (restart) only on that process.
In this example, the supervisor starts two child processes. It’s important to be aware that children are started synchronously, in the order specified. The supervisor starts a child, waits for it to finish, and then moves on to start the next child. When the worker is a GenServer, the next child is started only after the init/1 callback function for the current child is finished.
You may recall from chapter 7 that init/1 shouldn’t run for a long time. This is precisely why. If Todo.Database was taking, say, 5 minutes to start, you wouldn’t have the to-do cache available all that time. Always make sure your init/1 functions run quickly, and use the technique mentioned in chapter 7 (post-initialization continuation via the handle_continue/2 callback) when you need more complex initialization.
9.1.2 Rich process discovery
Although you now have some basic error isolation, there’s still a lot to be desired. An error in one database worker will crash the entire database structure and terminate all running database operations. Ideally, you want to confine a database error to a single worker. This means each database worker must be directly supervised.
There’s one problem with this approach. Recall that in the current version, the database server starts the workers and keeps their PIDs in its internal list. But if a process is started from a supervisor, you don’t have access to the PID of the worker process. This is a property of supervisors. You can’t keep a worker’s PID for a long time because that process might be restarted, and its successor will have a different PID.
Therefore, you need a way to give symbolic names to supervised processes and access each process via this name. When a process is restarted, the successor will register itself under the same name, which will allow you to reach the right process even after multiple restarts.
You could use registered names for this purpose. The problem is that names can only be atoms, and in this case, you need something more elaborate that will allow you to use arbitrary terms, such as {:database_worker, 1}, {:database_worker, 2}, and so on. What you need is a process registry that maintains a key-value map, where the keys are names and the values are PIDs. A process registry differs from standard local registration in that names can be arbitrarily complex.
Every time a process is created, it can register itself to the registry under a name. If a process is terminated and restarted, the new process will reregister itself. Having a registry will give you a fixed point where you can discover processes (their PIDs). The idea is illustrated in figure 9.3.
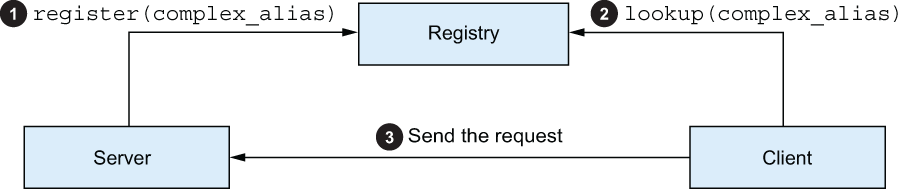
Figure 9.3 Discovering processes through a registry
First, the worker process registers itself, usually during initialization. Sometime later, the client process will query the registry for the PID of the desired worker. The client can then issue a request to the server process.
Elixir’s standard library includes the implementation of a process registry in the Registry module. This module allows you to associate a process with one or more arbitrary complex keys and then find the process (its PID) by performing a key-based lookup.
Let’s look at a couple of examples. The process registry is, itself, a process. You can start it by invoking Registry.start_link/1:
iex(1)> Registry.start_link(name: :my_registry, keys: :unique)
The single argument is a keyword list of registry options. The mandatory options are :name and :keys.
The :name option is an atom, and it specifies the name of the registry process. You’ll use this name to interact with the registry.
The :keys option can either be :unique or :duplicate. In a unique registry, names are unique—only one process can be registered under any key. This is useful when you want to assign a unique role to processes. For example, in your system, only one process could be associated with {:database_worker, 1}. In contrast, in a duplicate registry, several processes can have the same name. Duplicate registry is useful in scenarios where a single publisher process needs to send notifications to a dynamic number of subscriber processes that tend to come and go over time.
Once you have the registry started, you can register a process under some key. Let’s try it out. You’ll spawn a mock {:database_worker, 1} process that waits for a message and then prints it to the console:
iex(2)> spawn(fn ->
Registry.register(:my_registry, {:database_worker, 1}, nil) ❶
receive do
msg -> IO.puts("got message #{inspect(msg)}")
end
end)
❶ Registers the process at the registry
The crucial bit happens when invoking Registry.register/3. Here, you’re passing the name of the registry (:my_registry), the desired name of the spawned process ({:database_worker, 1}), and an arbitrary value. The Registry will then store a mapping of the name to the provided value and the PID of the caller process.
At this point, the registered process can be discovered by other processes. Notice how in the preceding snippet, you didn’t take the PID of the database worker. That’s because you don’t need it. You can look it up in the registry by invoking Registry.lookup/2:
iex(3)> [{db_worker_pid, _value}] =
Registry.lookup(
:my_registry,
{:database_worker, 1}
)
Registry.lookup/2 takes the name of the registry and the key (process name) and returns a list of {pid, value} tuples. When the registry is unique, this list can be either empty (no process is registered under the given key), or it can have one element. For a duplicate registry, this list can have any number of entries. The pid element in each tuple is the PID of the registered process, whereas the value is the value provided to Registry.register/3.
Now that you’ve discovered the mock database worker, you can send it a message:
iex(4)> send(db_worker_pid, :some_message) got message :some_message
A very useful property of Registry is that it links to all the registered processes. This allows the registry to notice the termination of these processes and remove the corresponding entry from its internal structure.
You can immediately verify this. The database worker mock was a one-off process. It received a message, printed it, and then stopped. Try to discover it again:
iex(5)> Registry.lookup(:my_registry, {:database_worker, 1})
[]
As you can see, no entry is found under the given key because the database worker terminated.
Note It’s worth mentioning that Registry is implemented in plain Elixir. You can think of Registry as something like a GenServer that holds the map of names to PIDs in its state. In reality, the implementation is more sophisticated and relies on the ETS table feature, which you’ll learn about in chapter 10. ETS tables allow Registry to be very efficient and scalable. Lookups and writes are very fast, and in many cases, they won’t block each other, meaning multiple operations on the same registry may run in parallel.
Registry has more features and properties, which we won’t discuss here. You can take a look at the official documentation at https://hexdocs.pm/elixir/Registry.xhtml for more details. But there’s one very important feature of OTP processes that you need to learn about: via tuples.
9.1.3 Via tuples
A via tuple is a mechanism that allows you to use an arbitrary third-party registry to register OTP-compliant processes, such as GenServer and supervisors. Recall that you can provide a :name option when starting a GenServer:
GenServer.start_link(callback_module, some_arg, name: some_name)
So far, you’ve only passed atoms as the :name option, which caused the started process to be registered locally. But the :name option can also be provided in the shape of {:via, some_module, some_arg}. Such a tuple is also called a via tuple.
If you provide a via tuple as the name option, GenServer will invoke a well-defined function from some_module to register the process. Likewise, you can pass a via tuple as the first argument to GenServer.cast and GenServer.call, and GenServer will discover the PID using some_module. In this sense, some_module acts like a custom third-party process registry, and the via tuple is the way of connecting such a registry with GenServer and similar OTP abstractions.
The third element of the via tuple, some_arg, is a piece of data that’s passed to functions of some_module. The exact shape of this data is defined by the registry module. At the very least, this piece of data must contain the name under which the process should be registered and looked up.
In the case of Registry, the third argument should be a pair, {registry_name, process_key}, so the entire via tuple then has the shape of {:via, Registry, {registry_name, process_key}}.
Let’s look at an example. We’ll revisit our old friend from chapter 6: the EchoServer. This is a simple GenServer that handles a call request by returning the request payload. Now, you’ll add registration to the echo server. When you start the server, you’ll provide the server ID—an arbitrary term that uniquely identifies the server. When you want to send a request to the server, you’ll pass this ID, instead of the PID.
Here’s the full implementation:
defmodule EchoServer do
use GenServer
def start_link(id) do
GenServer.start_link(__MODULE__, nil, name: via_tuple(id)) ❶
end
def init(_), do: {:ok, nil}
def call(id, some_request) do
GenServer.call(via_tuple(id), some_request) ❷
end
defp via_tuple(id) do
{:via, Registry, {:my_registry, {__MODULE__, id}}} ❸
end
def handle_call(some_request, _, state) do
{:reply, some_request, state}
end
end
❶ Registers the server using a via tuple
❷ Discovers the server using a via tuple
❸ Registry-compliant via tuple
Here, you consolidate the shaping of the via tuple in the via_tuple/1 helper function. The registered name of the process will be {__MODULE__, id} or, in this case, {EchoServer, id}.
Try it out. Start the iex session, copy and paste the module definition, and then start :my_registry:
iex(1)> defmodule EchoServer do ... end iex(2)> Registry.start_link(name: :my_registry, keys: :unique)
Now, you can start and interact with multiple echo servers without needing to keep track of their PIDs:
iex(3)> EchoServer.start_link("server one")
iex(4)> EchoServer.start_link("server two")
iex(5)> EchoServer.call("server one", :some_request)
:some_request
iex(6)> EchoServer.call("server two", :another_request)
:another_request
Notice that the IDs here are strings, and also recall that the whole registered key is, in fact, {EchoServer, some_id}, which proves that you’re using arbitrary complex terms to register processes and discover them.
9.1.4 Registering database workers
Now that you’ve learned the basics of Registry, you can implement registration and discovery of your database workers. First, you need to create the Todo.ProcessRegistry module.
Listing 9.3 To-do process registry (pool_supervision/lib/todo/process_registry.ex)
defmodule Todo.ProcessRegistry do
def start_link do
Registry.start_link(keys: :unique, name: __MODULE__)
end
def via_tuple(key) do
{:via, Registry, {__MODULE__, key}}
end
def child_spec(_) do ❶
Supervisor.child_spec( ❶
Registry, ❶
id: __MODULE__, ❶
start: {__MODULE__, :start_link, []} ❶
) ❶
end
end
The interface functions are straightforward. The start_link function simply forwards to the Registry module to start a unique registry. The via_tuple/1 function can be used by other modules, such as Todo.DatabaseWorker, to create the appropriate via tuple that registers a process with this registry.
Because the registry is a process, it should be supervised. Therefore, you include child_spec/1 in the module. Here, you’re using Supervisor.child_spec/2 to adjust the default specification from the Registry module. This invocation essentially states that you’ll use whatever child specification is provided by Registry, with :id and :start fields changed. By doing this, you don’t need to know about the internals of the Registry implementation, such as whether the registry process is a worker or a supervisor.
With this in place, you can immediately put the registry under the Todo.System supervisor.
Listing 9.4 Supervising registry (pool_supervision/lib/todo/system.ex)
defmodule Todo.System do
def start_link do
Supervisor.start_link(
[
Todo.ProcessRegistry, ❶
Todo.Database,
Todo.Cache
],
strategy: :one_for_one
)
end
end
Keep in mind that processes are started synchronously, in the order you specify. Thus, the order in the child specification list matters and isn’t chosen arbitrarily. A child must always be specified after its dependencies. In this case, you must start the registry first because database workers will depend on it.
With Todo.ProcessRegistry in place, you can start adapting the database workers. The relevant changes are presented in the following listing.
Listing 9.5 Registering workers (pool_supervision/lib/todo/database_worker.ex)
defmodule Todo.DatabaseWorker do
use GenServer
def start_link({db_folder, worker_id}) do
GenServer.start_link(
__MODULE__,
db_folder,
name: via_tuple(worker_id) ❶
)
end
def store(worker_id, key, data) do
GenServer.cast(via_tuple(worker_id), {:store, key, data}) ❷
end
def get(worker_id, key) do
GenServer.call(via_tuple(worker_id), {:get, key}) ❷
end
defp via_tuple(worker_id) do
Todo.ProcessRegistry.via_tuple({__MODULE__, worker_id})
end
...
end
This code introduces the notion of a worker_id, which is an integer in the range 1..pool_size. The start_link function now takes this parameter together with db_ folder. However, notice that the function takes both parameters as a single {db_folder, worker_id} tuple. The reason is again in conformance with the autogenerated child_spec/1, which forwards to start_link/1. To manage a worker under a supervisor, you can now use the {Todo.DatabaseWorker, {db_folder, worker_id}} child specification.
When invoking GenServer.start_link, you provide the via tuple as the name option. The exact shape of the tuple is wrapped in the internal via_tuple/1 function, which takes the worker ID and returns the corresponding via tuple. This function just delegates to Todo.ProcessRegistry, passing it the desired name in the form {__MODULE__, worker_id}. Therefore, a worker is registered with the key {Todo.DatabaseWorker, worker_id}. Such a name eliminates possible clashes with other types of processes that might be registered with the same registry.
Similarly, you use the via_tuple/1 helper to discover the processes when invoking GenServer.call and GenServer.cast. Notice that store/3 and get/2 functions now receive a worker ID as the first argument. This means their clients don’t need to keep track of the PIDs anymore.
9.1.5 Supervising database workers
Now, you can create a new supervisor that will manage the pool of workers. Why introduce a separate supervisor? Theoretically, placing workers under Todo.System would work fine. But remember from the previous chapter that if restarts happen too often, the supervisor gives up at some point and terminates all of its children. If you keep too many children under the same supervisor, you might reach the maximum restart intensity sooner—in which case, all processes are restarted. In other words, problems in a single process could easily ripple out to the majority of the system.
In this case, I made an arbitrary decision to place a distinct part of the system (the database) under a separate supervisor. This approach may limit the impact of a failed restart to database operations. If restarting one database worker fails, the supervisor will terminate, which means the parent supervisor will try to restart the entire database service without touching other processes in the system.
Either way, the consequence of these changes is that you don’t need the database GenServer anymore. The purpose of this server was to start a pool of worker processes and manage the mapping of a worker ID to PID. With these new changes, the workers are started by the supervisor; the mapping is already handled by the registry. Therefore, the database GenServer is redundant.
You can keep the Todo.Database module. It will now implement a supervisor of database worker processes and retain the same interface functions as before. As a result, you don’t need to change the code of the client Todo.Server module at all, and you can keep Todo.Database in the list of Todo.System children.
Next, you’ll convert the database into a supervisor.
Listing 9.6 Supervising workers (pool_supervision/lib/todo/database.ex)
defmodule Todo.Database do
@pool_size 3
@db_folder "./persist"
def start_link do
File.mkdir_p!(@db_folder)
children = Enum.map(1..@pool_size, &worker_spec/1)
Supervisor.start_link(children, strategy: :one_for_one)
end
defp worker_spec(worker_id) do
default_worker_spec = {Todo.DatabaseWorker, {@db_folder, worker_id}}
Supervisor.child_spec(default_worker_spec, id: worker_id)
end
...
end
You start off by creating a list of three child specifications, each of them describing one database worker. Then, you pass this list to Supervisor.start_link/2.
The specification for each worker is created in worker_spec/1. You start off with the default specification for the database worker, {Todo.DatabaseWorker, {@db_folder, worker_id}}. Then, you use Supervisor.child_spec/2 to set the unique ID for the worker.
Without that, you’d end up having multiple children with the same ID. Recall from chapter 8 that a default child_spec/1, generated via use GenServer, provides the name of the module in the :id field. Consequently, if you use that default specification and try to start two database workers, they’ll both get the same ID of Todo.DatabaseWorker. Then, the Supervisor module will complain about it and raise an error.
You also need to implement Todo.Database.child_spec/1. You just converted the database into a supervisor, so the module doesn’t contain use GenServer anymore, meaning child_spec/1 isn’t autogenerated. The code is shown in the following listing.
Listing 9.7 Database operations (pool_supervision/lib/todo/database.ex)
defmodule Todo.Database do
...
def child_spec(_) do
%{
id: __MODULE__,
start: {__MODULE__, :start_link, []},
type: :supervisor
}
end
...
end
The specification contains the field :type, which hasn’t been mentioned before. This field can be used to indicate the type of the started process. The valid values are :supervisor (if the child is a supervisor process) or :worker (for any other kind of process). If you omit this field, the default value of :worker is used.
The child_spec/1 in listing 9.7, therefore, specifies that Todo.Database is a supervisor and that it can be started by invoking Todo.Database.start_link/0.
This is a nice example of how child_spec/1 helps you keep implementation details in the module that powers a process. You just turned the database into a supervisor, and you changed the arity of its start_link function (it now takes zero arguments), but nothing needs to be changed in the Todo.System module.
Next, you need to adapt the store/2 and get/1 functions.
Listing 9.8 Database operations (pool_supervision/lib/todo/database.ex)
defmodule Todo.Database do
...
def store(key, data) do
key
|> choose_worker()
|> Todo.DatabaseWorker.store(key, data)
end
def get(key) do
key
|> choose_worker()
|> Todo.DatabaseWorker.get(key)
end
defp choose_worker(key) do
:erlang.phash2(key, @pool_size) + 1
end
...
end
The only difference from the previous version is in the choose_worker/1 function. Previously, this function issued a call to the database server. Now, it just selects the worker ID in the range 1..@pool_size. This ID is then passed to Todo.DatabaseWorker functions, which will perform a registry lookup and forward the request to the corresponding database worker.
At this point, you can test how the system works. Start everything:
iex(1)> Todo.System.start_link() Starting database server. Starting database worker. Starting database worker. Starting database worker. Starting to-do cache.
Now, verify that you can restart individual workers correctly. To do that, you need to get the PID of a worker. Because you know the internals of the system, this can easily be done by looking it up in the registry. Once you have the PID, you can terminate the worker:
iex(2)> [{worker_pid, _}] =
Registry.lookup(
Todo.ProcessRegistry,
{Todo.DatabaseWorker, 2}
)
iex(3)> Process.exit(worker_pid, :kill)
Starting database worker.
The worker is restarted, as expected, and the rest of the system is undisturbed.
It’s worth repeating how the registry supports proper behavior in the system regarding restarted processes. When a worker is restarted, the new process has a different PID. But owing to the registry, the client code doesn’t care about that. You resolve the PID at the latest possible moment, doing a registry lookup prior to issuing a request to the database worker. Therefore, in most cases, the lookup will succeed, and you’ll talk to the proper process.
In some cases, the discovery of the database worker might return an invalid value, such as if the database worker crashes after the client process found its PID but before the request is sent. In this case, the client process has a stale PID, so the request will fail. A similar problem can occur if a client wants to find a database worker that has just crashed. Restarting and registration run concurrently with the client, so the client might not find the worker PID in the registry.
Both scenarios lead to the same result: the client process—in this case, a to-do server—will crash, and the error will be propagated to the end user. This is a consequence of the highly concurrent nature of the system. A failure recovery is performed concurrently in the supervisor process, so some part of the system might not be in a consistent state for a brief period.
9.1.6 Organizing the supervision tree
Let’s stop for a moment and reflect on what you’ve done so far. The relationship between processes is presented in figure 9.4.
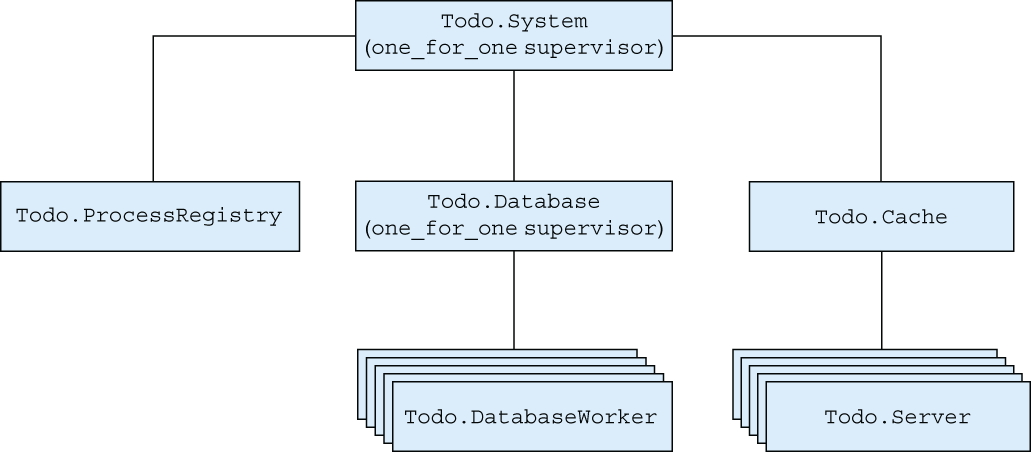
This is an example of a simple supervision tree—a nested structure of supervisors and workers. The tree describes how the system is organized into a hierarchy of services. In this example, the system consists of three services: the process registry, the database, and the cache.
Each service can be further subdivided into subservices. For example, the database is composed of several workers, and the cache is composed of multiple to-do servers. Even the registry is further subdivided into multiple processes, but that’s an implementation detail of the Registry module, so it’s not shown on the diagram.
Although supervisors are frequently mentioned in the context of fault tolerance and error recovery, defining the proper starting order is their most essential role. The supervision tree describes how the system is started and how it’s taken down.
A more granular tree allows you to take down an arbitrary part of the system, without touching anything else. In the current version, stopping the database service is as easy as asking its parent (Todo.System) to stop the Todo.Database child, using the Supervisor.terminate_child/2 function. This will take down the database process together with its descendants.
If worker processes are small services in a system, you can think of supervisors as being service managers—a built-in equivalent of systemd, Windows Service Manager, and the like. They’re responsible for the life cycles of services they directly manage. If any critical service stops, its parent will try to restart it.
Looking at the supervision tree, you can reason about how errors are handled and propagated throughout the system. If a database worker crashes, the database supervisor will restart it, leaving the rest of the system alone. If that doesn’t help, you’ll exceed the maximum restart frequency, and the database supervisor will terminate all database workers and then itself.
This will be noticed by the system supervisor, which will then start a fresh database pool in hopes of solving the problem. What does all this restarting get you? By restarting an entire group of workers, you effectively terminate all pending database operations and begin clean. If that doesn’t help, there’s nothing more you can do, so you propagate the error up the tree (in this case, killing everything). This is how error recovery works in supervision trees—you try to recover from an error locally, affecting as few processes as possible. If that doesn’t work, you move up and try to restart the wider part of the system.
All processes that are started directly from a supervisor should be OTP compliant. To implement an OTP-compliant process, it’s not enough to spawn or link a process; you also must handle some OTP-specific messages in a particular way. The details of what exactly must be done are provided in the Erlang documentation at https://www.erlang.org/doc/design_principles/spec_proc.xhtml#special-processes.
Luckily, you usually won’t need to implement an OTP-compliant process from scratch. Instead, you can use various higher-level abstractions, such as GenServer, Supervisor, and Registry. The processes started with these modules will be OTP-compliant. Elixir also ships with Task and Agent modules that can be used to run OTP-compliant processes. You’ll learn about tasks and agents in the next chapter.
Plain processes started by spawn_link aren’t OTP-compliant, so such processes shouldn’t be started directly from a supervisor. You can freely start plain processes from workers, such as GenServer, but it’s generally better to use OTP-compliant processes wherever possible.
An important benefit of supervision trees is the ability to stop the entire system without leaving dangling processes. When you terminate a supervisor, all of its immediate children are also terminated. If all other processes are directly or indirectly linked to those children, they will eventually be terminated as well. Consequently, you can stop the entire system by terminating the top-level supervisor process.
Most often, a supervisor subtree is terminated in a controlled manner. A supervisor process will instruct its children to terminate gracefully, thus giving them the chance to do final cleanup. If some of those children are, themselves, supervisors, they will take down their own trees in the same way. Graceful termination of a GenServer worker involves invoking the terminate/2 callback but only if the worker process is trapping exits. Therefore, if you want to do some cleanup from a GenServer process, make sure you set up an exit trap from an init/1 callback.
Because graceful termination involves the possible execution of cleanup code, it may take longer than desired. The :shutdown option in a child specification lets you control how long the supervisor will wait for the child to terminate gracefully. If the child doesn’t terminate in this time, it will be forcefully terminated. You can choose the shutdown time by specifying shutdown: shutdown_strategy in child_spec/1 and passing an integer representing a time in milliseconds. Alternatively, you can pass the atom :infinity, which instructs the supervisor to wait indefinitely for the child to terminate. Finally, you can pass the atom :brutal_kill, telling the supervisor to immediately terminate the child in a forceful way. The forceful termination is done by sending a :kill exit signal to the process, like you did with Process.exit(pid, :kill). The default value of the :shutdown option is 5_000 for a worker process or :infinity for a supervisor process.
By default, a supervisor restarts a terminated process regardless of the exit reason. Even if the process terminates with the reason :normal, it will be restarted. Sometimes, you may want to alter this behavior.
For example, consider a process that handles an HTTP request or a TCP connection. If such a process fails, the socket will be closed, and there’s no point in restarting the process (the remote party will be disconnected anyway). You still want to have such processes under a supervision tree because this makes it possible to terminate the entire supervisor subtree without leaving dangling processes. In this situation, you can set up a temporary worker by providing restart: :temporary in child_spec/1. A temporary worker isn’t restarted on termination.
Another option is a transient worker, which is restarted only if it terminates abnormally. Transient workers can be used for processes that may terminate normally as part of the standard system workflow. A typical example for this is a one-off job you want to execute when the system is started. You could start the corresponding process (usually powered by the Task module) in the supervision tree, and then configure it as transient. A transient worker can be specified by providing restart: :transient in child_spec/1.
So far, you’ve been using only the :one_for_one restart strategy. In this mode, a supervisor handles a process termination by starting a new process in its place, leaving other children alone. There are two additional restart strategies:
-
:one_for_all—When a child crashes, the supervisor terminates all other children and then starts all children. -
:rest_for_one—When a child crashes, the supervisor terminates all younger siblings of the crashed child. Then, the supervisor starts new child processes in place of the terminated ones.
These strategies are useful if there’s tight coupling between siblings, where the service of some child doesn’t make any sense without its siblings. One example is when a process keeps the PID of some sibling in its own state. In this case, the process is tightly coupled to an instance of the sibling. If the sibling terminates, so should the dependent process.
By opting for :one_for_all or :rest_for_one, you can make that happen. The former is useful when there’s tight dependency in all directions (every sibling depends on other siblings). The latter is appropriate if younger siblings depend on the older ones.
For example, in the to-do system, you could use :rest_for_one to take down database workers if the registry process terminates. Without the registry, these processes can’t serve any purpose, so taking them down would be the proper thing to do. In this case, however, you don’t need to do that because Registry links each registered process to the registry process. As a result, a termination of the registry process is properly propagated to the registered processes. Any such process that doesn’t trap exits will be taken down automatically; processes that trap exits will receive a notification message.
This concludes our initial look at fine-grained supervision. You’ve made several changes that minimize the effects of errors, but there’s still a lot of room for improvement. You’ll continue extending the system in the next section, where you’ll learn how to start workers dynamically.
9.2 Starting processes dynamically
With the changes you made in the previous section, the impact of a database-worker error is now confined to a single worker. It’s time to do the same thing for to-do servers. You’ll use roughly the same approach as you did with database workers: running each to-do server under a supervisor and registering the servers in the process registry.
9.2.1 Registering to-do servers
You’ll start off by adding registration to to-do servers. The change is simple, as shown in the following listing.
Listing 9.9 Registering to-do servers (dynamic_workers/lib/todo/server.ex)
defmodule Todo.Server do
use GenServer, restart: :temporary
def start_link(name) do
GenServer.start_link(__MODULE__, name, name: via_tuple(name)) ❶
end
defp via_tuple(name) do
Todo.ProcessRegistry.via_tuple({__MODULE__, name})
end
...
end
This is the same technique you used with database workers. You pass the via tuple as the name option. The via tuple will state that the server should be registered with the {__MODULE__, name} key to the process registry. Using this form of the key avoids possible collisions between to-do server keys and database worker keys.
The functions add_entry/2 and entries/2 are unchanged, and they still take the PID as the first argument, so the usage remains the same. A client process first obtains the PID of the to-do server by invoking Todo.Cache.server_process/1, and then it invokes Todo.Server functions.
9.2.2 Dynamic supervision
Next, you need to supervise to-do servers. There’s a twist, though. Unlike database workers, to-do servers are created dynamically when needed. Initially, no to-do server is running; each is created on demand when you call Todo.Cache.server_process/1. This effectively means you can’t specify supervisor children up front because you don’t know how many children you’ll need.
For such cases, you need a dynamic supervisor that can start children on demand. In Elixir, this feature is available via the DynamicSupervisor module.
DynamicSupervisor is similar to Supervisor, but where Supervisor is used to start a predefined list of children, DynamicSupervisor is used to start children on demand. When you start a dynamic supervisor, you don’t provide a list of child specifications, so only the supervisor process is started. Then, whenever you want to, you can start a supervised child using DynamicSupervisor.start_child/2.
Let’s see this in action. You’ll convert Todo.Cache into a dynamic supervisor, much like what you did with the database. The relevant code is presented in the following listing.
Listing 9.10 To-do cache as a supervisor (dynamic_workers/lib/todo/cache.ex)
defmodule Todo.Cache do
def start_link() do
IO.puts("Starting to-do cache.")
DynamicSupervisor.start_link( ❶
name: __MODULE__,
strategy: :one_for_one
)
end
...
end
You start the supervisor using DynamicSupervisor.start_link/1. This will start the supervisor process, but no children are specified at this point. Notice that when starting the supervisor, you’re also passing the :name option. This will cause the supervisor to be registered under a local name.
By making the supervisor locally registered, it’s easier for you to interact with the supervisor and ask it to start a child. You can immediately use this by adding the start_child/1 function, which starts the to-do server for the given to-do list:
defmodule Todo.Cache do
...
defp start_child(todo_list_name) do
DynamicSupervisor.start_child(
__MODULE__,
{Todo.Server, todo_list_name}
)
end
...
end
Here, you’re invoking DynamicSupervisor.start_child/2, passing it the name of your supervisor and the child specification of the child you want to start. The {Todo.Server, todo_list_name} specification will lead to the invocation of Todo.Server.start_ link(todo_list_name). The to-do server will be started as the child of the Todo.Cache supervisor.
It’s worth noting that DynamicSupervisor.start_child/2 is a cross-process synchronous call. A request is sent to the supervisor process, which then starts the child. If several client processes simultaneously try to start a child under the same supervisor, the requests will be serialized.
For more details on dynamic supervisors, refer to the official documentation at https://hexdocs.pm/elixir/DynamicSupervisor.xhtml.
One small thing left to do is implement child_spec/1:
defmodule Todo.Cache do
...
def child_spec(_arg) do
%{
id: __MODULE__,
start: {__MODULE__, :start_link, []},
type: :supervisor
}
end
...
end
At this point, the to-do cache is converted into a dynamic supervisor.
9.2.3 Finding to-do servers
The final thing left to do is to change the discovery Todo.Cache.server_process/1 function. This function takes a name and returns the pid of the to-do server, starting it if it’s not running. The implementation is provided in the following listing.
Listing 9.11 Finding a to-do server (dynamic_workers/lib/todo/cache.ex)
defmodule Todo.Cache do
...
def server_process(todo_list_name) do
case start_child(todo_list_name) do
{:ok, pid} -> pid ❶
{:error, {:already_started, pid}} -> pid ❷
end
end
defp start_child(todo_list_name) do
DynamicSupervisor.start_child(
__MODULE__,
{Todo.Server, todo_list_name}
)
end
end
❷ The server was already running.
The function first invokes the local start_child/1 function, which you prepared in the previous section and which is a simple wrapper around DynamicSupervisor .start_child/2.
This invocation can have two successful outcomes. In the most obvious case, the function returns {:ok, pid} with the pid of the newly started to-do server.
The second outcome is more interesting. If the result is {:error, {:already_started, pid}}, the to-do process failed to register because another process is already registered with the same name—a to-do server for the list with the given name is already running. For the to-do example, this outcome is also a success. You tried to start the server, but it was already running. That’s fine. You have the pid of the server, and you can interact with it.
The result {:error, {:already_started, pid}} is returned, due to the inner workings of GenServer registration. When the :name option is provided to GenServer.start_link, the registration is performed in the started process before init/1 is invoked. This registration can fail if some other process is already registered under the same key. In this case, GenServer.start_link doesn’t resume to run the server loop. Instead, it returns {:error, {:already_started, pid}}, where the pid points to the process that’s registered under the same key. This result is then returned by DynamicSupervisor.start_child.
It’s worth briefly discussing how server_process/1 behaves in a concurrent scenario. Consider the case of two processes invoking this function at the same time. The execution moves to DynamicSupervisor.start_child/2, so you might end up with two simultaneous executions of start_child on the same supervisor. Recall that a child is started in the supervisor process. Therefore, the invocations of start_child are serialized and server_process/1 doesn’t suffer from race conditions.
On the flip side, the way start_child is used here is not very efficient. Every time you want to work with a to-do list, you issue a request to the supervisor, so the supervisor process can become a bottleneck. Even if the to-do server is already running, the supervisor will briefly start a new child, which will immediately stop. This process can easily be improved, but we’ll leave it for now because the current implementation is behaving properly. We’ll revisit this issue in chapter 12 when we move to a distributed registration.
9.2.4 Using the temporary restart strategy
There’s one thing left to do. You’ll configure the to-do server to be a :temporary child. As a result, if a to-do server stops—say, due to a crash—it won’t be restarted.
Why choose this approach? Servers are started on demand, so when a user tries to interact with a to-do list, if the server process isn’t running, it will be started. If a to-do list server crashes, it will be started on the next use, so there’s no need to restart it automatically.
Opting for the :temporary strategy also means the parent supervisor won’t be restarted, due to too many failures in its children. Even if there are frequent crashes in one to-do server—say, due to corrupt state—you’ll never take down the entire cache, which should improve the availability of the entire system.
Changing the restart strategy is easily done by providing the :restart option to use GenServer.
Listing 9.12 Changing to-do server restart strategy (dynamic_workers/lib/todo/server.ex)
defmodule Todo.Server do use GenServer, restart: :temporary ... end
The :temporary value will be included under the :restart key in the result of child_spec/1, so the parent supervisor will treat the child as temporary. If the child terminates, it won’t be restarted.
You might wonder why to-do servers are supervised if they’re not restarted. There are two important benefits of this. First, this structure ensures that the failure of a single to-do server doesn’t affect any other process in the system. In addition, as explained in section 9.1.6, this allows you to properly take down the system, or some service in the system, without leaving any dangling processes behind. To stop all to-do servers, you need to stop the Todo.Cache supervisor. In other words, supervision isn’t just about restarting crashed processes but also about isolating individual crashes and enabling proper termination.
9.2.5 Testing the system
At this point, the to-do servers are supervised, and you can test the code. Notice that you didn’t have to make any change in the Todo.System supervisor. The Todo.Cache was already listed as a child, and you only changed its internals. Let’s see if this works.
Start the shell and the entire system:
iex(1)> Todo.System.start_link() Starting database server. Starting database worker. Starting database worker. Starting database worker. Starting to-do cache.
Now, you can get one to-do server:
iex(2)> bobs_list = Todo.Cache.server_process("Bob's list")
Starting to-do server for Bob's list
#PID<0.118.0>
Repeating the request doesn’t start another server:
iex(3)> bobs_list = Todo.Cache.server_process("Bob's list")
#PID<0.118.0>
In contrast, using a different to-do list name creates another process:
iex(4)> alices_list = Todo.Cache.server_process("Alice's list")
Starting to-do server for Alice's list
#PID<0.121.0>
iex(5)> Process.exit(bobs_list, :kill)
The subsequent call to Todo.Cache.server_process/1 will return a different PID:
iex(6)> Todo.Cache.server_process("Bob's list")
Starting to-do server for Bob's list
#PID<0.124.0>
Of course, Alice’s server remains undisturbed:
iex(7)> Todo.Cache.server_process("Alice's list")
#PID<0.121.0>
The supervision tree of the new code is presented in figure 9.5. The diagram depicts how you supervise each process, limiting the effect of unexpected errors.
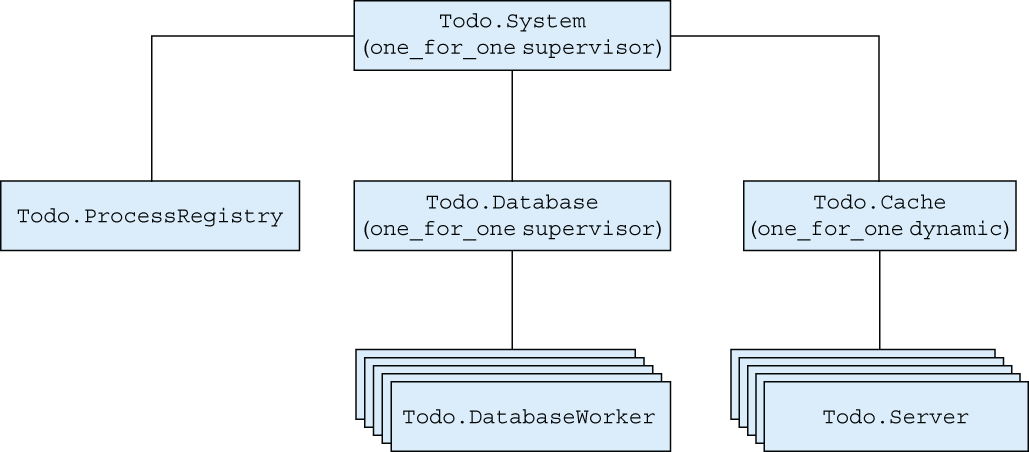
Figure 9.5 Supervising to-do servers
With this, you’re finished making your to-do system fault tolerant. You’ve introduced additional supervisor processes to the system, and you’ve also managed to simplify some other parts (removing the to-do cache and database server processes). You’ll make many more changes to this system, but for now, let’s leave it and look at some important, practical considerations.
9.3 “Let it crash”
In general, when you develop complex systems, you should employ supervisors to do your error handling and recovery. With properly designed supervision trees, you can limit the impact of unexpected errors, and the system will, hopefully, recover. I can personally testify that supervisors have helped me in occasional weird situations in production, keeping the running system stable and saving me from unwanted phone calls in the middle of the night. It’s also worth noting that OTP provides logging facilities, so process crashes are logged and you can see that something went wrong. It’s even possible to set up an event handler that will be triggered on every process crash, thus allowing you to perform custom actions, such as sending an email or reporting to an external system.
An important consequence of this style of error handling is that the worker code is liberated from paranoid, defensive try/catch constructs. Usually, these aren’t needed because you use supervisors to handle error recovery. Joe Armstrong, one of the inventors of Erlang, described such a style in his PhD thesis (“Making reliable distributed systems in the presence of software errors,” https://erlang.org/download/armstrong_ thesis_2003.pdf) as intentional programming. Using this approach, the code states the programmer’s intention, rather than being cluttered with all sorts of defensive constructs.
This style is also known as let it crash. In addition to making the code shorter and more focused, “let it crash” promotes clean-slate recovery. Remember, when a new process starts, it starts with new state, which should be consistent. Furthermore, the message queue (mailbox) of the old process is thrown away. This will cause some requests in the system to fail. However, the new process starts fresh, which gives it a better chance to resume normal operation.
Initially, “let it crash” may seem confusing, and people may mistake it for the “let everything crash” approach. There are two important situations in which you should explicitly handle an error:
9.3.1 Processes that shouldn’t crash
Processes that shouldn’t crash are informally called a system’s error kernel—processes that are critical for the entire system to work and whose state can’t be restored in a simple and consistent way. Such processes are the heart of your system, and you generally don’t want them to crash because, without them, the system can’t provide any service.
You should keep the code of such important processes as simple as possible. The less logic that happens in the process, the smaller the chance of a process crash. If the code of your error-kernel process is complex, consider splitting it into two processes: one that holds state and another that does the actual work. The former process then becomes extremely simple and is unlikely to crash, whereas the worker process can be removed from the error kernel (because it no longer maintains critical state).
Additionally, you could consider including defensive try/catch expressions in each handle_* callback of a critical process, to prevent a process from crashing. Here’s a simple sketch of the idea:
def handle_call(message, _, state) do
try
new_state =
state
|> transformation_1()
|> transformation_2()
...
{:reply, response, new_state}
catch _, _ ->
{:reply, {:error, reason}, state} ❶
end
end
❶ Catches all errors and uses the original state
This snippet illustrates how immutable data structures allow you to implement a fault-tolerant server. While processing a request, you make a series of transformations on the state. If anything bad happens, you use the initial state, effectively performing a rollback of all changes. This preserves state consistency while keeping the process constantly alive.
Keep in mind that this technique doesn’t completely guard against a process crash. For example, you can always kill a process by invoking Process.exit(pid, :kill) because a :kill exit reason can’t be intercepted, even if you’re trapping exits. Therefore, you should always have a recovery plan for the crash of a critical process. Set up a proper supervision hierarchy to ensure the termination of all dependent processes in the case of an error-kernel process crash.
9.3.2 Handling expected errors
The whole point of the “let it crash” approach is to leave recovery of unexpected errors to supervisors. But if you can predict an error and you have a way to deal with it, there’s no reason to let the process crash.
Here’s a simple example. Look at the :get request in the database worker:
def handle_call({:get, key}, _, db_folder) do
data =
case File.read(file_name(db_folder, key)) do
{:ok, contents} -> :erlang.binary_to_term(contents)
_ -> nil ❶
end
{:reply, data, db_folder}
end
When handling a get request, you try to read from a file, covering the case when this read fails. If it doesn’t succeed, you return nil, treating this case as if an entry for the given key isn’t in the database.
But you can do better. Consider using an error only when the file isn’t available. This error is identified with {:error, :enoent}, so the corresponding code would look like this:
case File.read(...) do
{:ok, contents} -> do_something_with(contents)
{:error, :enoent} -> nil
end
Notice how you rely on pattern matching here. If neither of these two expected situations happens, a pattern match will fail, and so will your process. This is the idea of “let it crash.” You deal with expected situations (the file is either available or doesn’t exist), crashing if anything else goes wrong (e.g., you don’t have permissions).
In contrast, when storing data, you use File.write!/2 (notice the exclamation mark), which may throw an exception and crash the process. If you don’t succeed in saving the data, your database worker has failed, and there’s no point in hiding this fact. It’s better to fail fast, which will cause an error that will be logged and (hopefully) noticed and fixed.
Of course, restarting may not help. In this case, the supervisor will give up and crash itself, and the system will quickly come to a halt, which is probably a good thing. There is no point in working if you can’t persist the data.
As a general rule, if you know what to do with an error, you should definitely handle it. Otherwise, for anything unexpected, let the process crash and ensure proper error isolation and recovery via supervisors.
9.3.3 Preserving the state
Keep in mind that state isn’t preserved when a process is restarted. Remember from chapter 5 that a process’s state is its own private affair. When a process crashes, the memory it occupied is reclaimed, and the new process starts with new state. This has the important advantage of starting clean. Perhaps the process crashed due to inconsistent state, and starting fresh may fix the error.
That said, in some cases, you’ll want the process’s state to survive the crash. This isn’t provided out of the box; you need to implement it yourself. The general approach is to save the state outside of the process (e.g., in another process or to a database) and then restore the state when the successor process is started.
You already have this functionality in the to-do server. Recall that you have a simple database system that persists to-do lists to disk. When the to-do server is started, the first thing it tries to do is to restore the data from the database. This makes it possible for the new process to inherit the state of the old one.
In general, be careful when preserving state. As you learned in chapter 4, a typical change in a functional data abstraction goes through chained transformations:
new_state = state |> transformation_1(...) ... |> transformation_n(...)
As a rule, the state should be persisted after all transformations are completed. Only then can you be certain that your state is consistent, so this is a good opportunity to save it. For example, you do this in the to-do server after you modify the internal data abstraction:
def handle_cast({:add_entry, new_entry}, {name, todo_list}) do
new_list = Todo.List.add_entry(todo_list, new_entry)
Todo.Database.store(name, new_list) ❶
{:noreply, {name, new_list}}
end
tip Persistent state can have a negative effect on restarts. Let’s say an error is caused by state that’s somehow invalid (perhaps due to a bug). If this state is persisted, your process can never restart successfully because the process will restore the invalid state and then crash again (either on starting or when handling a request). You should be careful when persisting state. If you can afford to, it’s better to start clean and terminate all other dependent processes.
Summary
-
Supervisors allow you to localize the impact of an error, keeping unrelated parts of the system undisturbed.
-
The registry helps you find processes without needing to track their PIDs. This is very helpful if a process is restarted.
-
Each process should reside somewhere in a supervision tree. This makes it possible to terminate the entire system (or an arbitrary subpart of it) by terminating the supervisor.
-
When a process crashes, its state is lost. You can deal with this by storing state outside the process, but more often than not, it’s best to start with a clean state.
-
In general, you should handle unexpected errors through a proper supervision hierarchy. Explicit handling through a
tryconstruct should be used only when you have a meaningful way to deal with an error.