Chapter 8. Crates and Modules
This is one note in a Rust theme: systems programmers can have nice things.
Robert O’Callahan, “Random Thoughts on Rust: crates.io and IDEs”
Suppose you’re writing a program that simulates the growth of ferns, from the level of individual cells on up. Your program, like a fern, will start out very simple, with all the code, perhaps, in a single file—just the spore of an idea. As it grows, it will start to have internal structure. Different pieces will have different purposes. It will branch out into multiple files. It may cover a whole directory tree. In time it may become a significant part of a whole software ecosystem. For any program that grows beyond a few data structures or a few hundred lines, some organization is necessary.
This chapter covers the features of Rust that help keep your program organized: crates and modules. We’ll also cover other topics related to the structure and distribution of a Rust crate, including how to document and test Rust code, how to silence unwanted compiler warnings, how to use Cargo to manage project dependencies and versioning, how to publish open source libraries on Rust’s public crate repository, crates.io, how Rust evolves through language editions, and more, using the fern simulator as our running example.
Crates
Rust programs are made of crates. Each crate is a complete, cohesive unit: all the source code for a single library or executable, plus any associated tests, examples, tools, configuration, and other junk. For your fern simulator, you might use third-party libraries for 3D graphics, bioinformatics, parallel computation, and so on. These libraries are distributed as crates (see Figure 8-1).
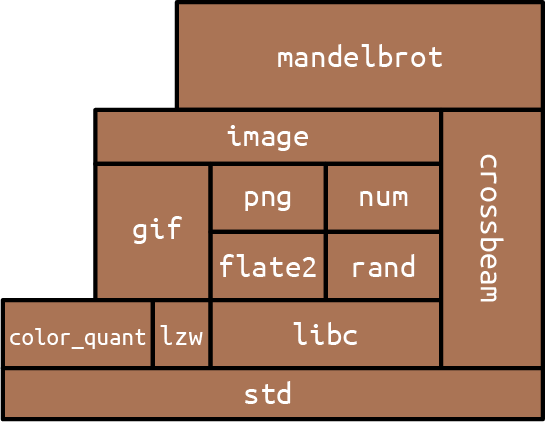
Figure 8-1. A crate and its dependencies
The easiest way to see what crates are and how they work together is to use cargo build with the --verbose flag to build an existing project that has some dependencies. We did this using “A Concurrent Mandelbrot Program” as our example. The results are shown here:
$cdmandelbrot$cargo clean# delete previously compiled code$cargo build --verboseUpdating registry `https://github.com/rust-lang/crates.io-index`Downloading autocfg v1.0.0Downloading semver-parser v0.7.0Downloading gif v0.9.0Downloading png v0.7.0... (downloading and compiling many more crates)Compiling jpeg-decoder v0.1.18Running `rustc--crate-name jpeg_decoder--crate-type lib...--extern byteorder=.../libbyteorder-29efdd0b59c6f920.rmeta...Compiling image v0.13.0Running `rustc--crate-name image--crate-type lib...--extern byteorder=.../libbyteorder-29efdd0b59c6f920.rmeta--extern gif=.../libgif-a7006d35f1b58927.rmeta--extern jpeg_decoder=.../libjpeg_decoder-5c10558d0d57d300.rmetaCompiling mandelbrot v0.1.0 (/tmp/rustbook-test-files/mandelbrot)Running `rustc--edition=2018--crate-name mandelbrot--crate-type bin...--extern crossbeam=.../libcrossbeam-f87b4b3d3284acc2.rlib--extern image=.../libimage-b5737c12bd641c43.rlib--extern num=.../libnum-1974e9a1dc582ba7.rlib -C link-arg=-fuse-ld=lld`Finished dev [unoptimized + debuginfo] target(s) in 16.94s$
We reformatted the rustc command lines for readability, and we deleted a lot of compiler options that aren’t relevant to our discussion, replacing them with an ellipsis (...).
You might recall that by the time we were done, the Mandelbrot program’s main.rs contained several use declarations for items from other crates:
usenum::Complex;// ...useimage::ColorType;useimage::png::PNGEncoder;
We also specified in our Cargo.toml file which version of each crate we wanted:
[dependencies] num = "0.4" image = "0.13" crossbeam = "0.8"
The word dependencies here just means other crates this project uses: code we’re depending on. We found these crates on crates.io, the Rust community’s site for open source crates. For example, we found out about the image library by going to crates.io and searching for an image library. Each crate’s page on crates.io shows its README.md file and links to documentation and source, as well as a line of configuration like image = "0.13" that you can copy and add to your Cargo.toml. The version numbers shown here are simply the latest versions of these three packages at the time we wrote the program.
The Cargo transcript tells the story of how this information is used. When we run cargo build, Cargo starts by downloading source code for the specified versions of these crates from crates.io. Then, it reads those crates’ Cargo.toml files, downloads their dependencies, and so on recursively. For example, the source code for version 0.13.0 of the image crate contains a Cargo.toml file that includes this:
[dependencies] byteorder = "1.0.0" num-iter = "0.1.32" num-rational = "0.1.32" num-traits = "0.1.32" enum_primitive = "0.1.0"
Seeing this, Cargo knows that before it can use image, it must fetch these crates as well. Later we’ll see how to tell Cargo to fetch source code from a Git repository or the local filesystem rather than crates.io.
Since mandelbrot depends on these crates indirectly, through its use of the image crate, we call them transitive dependencies of mandelbrot. The collection of all these dependency relationships, which tells Cargo everything it needs to know about what crates to build and in what order, is known as the dependency graph of the crate. Cargo’s automatic handling of the dependency graph and transitive dependencies is a huge win in terms of programmer time and effort.
Once it has the source code, Cargo compiles all the crates. It runs rustc, the Rust compiler, once for each crate in the project’s dependency graph. When compiling libraries, Cargo uses the --crate-type lib option. This tells rustc not to look for a main() function but instead to produce an .rlib file containing compiled code that can be used to create binaries and other .rlib files.
When compiling a program, Cargo uses --crate-type bin, and the result is a binary executable for the target platform: mandelbrot.exe on Windows, for example.
With each rustc command, Cargo passes --extern options, giving the filename of each library the crate will use. That way, when rustc sees a line of code like use image::png::PNGEncoder, it can figure out that image is the name of another crate, and thanks to Cargo, it knows where to find that compiled crate on disk. The Rust compiler needs access to these .rlib files because they contain the compiled code of the library. Rust will statically link that code into the final executable. The .rlib also contains type information so Rust can check that the library features we’re using in our code actually exist in the crate and that we’re using them correctly. It also contains a copy of the crate’s public inline functions, generics, and macros, features that can’t be fully compiled to machine code until Rust sees how we use them.
cargo build supports all sorts of options, most of which are beyond the scope of this book, but we will mention one here: cargo build --release produces an optimized build. Release builds run faster, but they take longer to compile, they don’t check for integer overflow, they skip debug_assert!() assertions, and the stack traces they generate on panic are generally less reliable.
Editions
Rust has extremely strong compatibility guarantees. Any code that compiled on Rust 1.0 must compile just as well on Rust 1.50 or, if it’s ever released, Rust 1.900.
But sometimes the community comes across compelling proposals for extensions to the language that would cause older code to no longer compile. For example, after much discussion, Rust settled on a syntax for asynchronous programming support that repurposes the identifiers async and await as keywords (see Chapter 20). But this language change would break any existing code that uses async or await as the name of a variable.
To evolve without breaking existing code, Rust uses editions. The 2015 edition of Rust is compatible with Rust 1.0. The 2018 edition changed async and await into keywords, streamlined the module system, and introduced various other language changes that are incompatible with the 2015 edition. Each crate indicates which edition of Rust it is written in with a line like this in the [package] section atop its Cargo.toml file:
edition = "2018"
If that keyword is absent, the 2015 edition is assumed, so old crates don’t have to change at all. But if you want to use asynchronous functions or the new module system, you’ll need edition = "2018" in your Cargo.toml file (or perhaps something even newer).
Rust promises that the compiler will always accept all extant editions of the language, and programs can freely mix crates written in different editions. It’s even fine for a 2015 edition crate to depend on a 2018 edition crate. In other words, a crate’s edition only affects how its source code is construed; edition distinctions are gone by the time the code has been compiled. This means there’s no pressure to update old crates just to continue to participate in the modern Rust ecosystem. Similarly, there’s no pressure to keep your crate on an older edition to avoid inconveniencing its users. You only need to change editions when you want to use new language features in your own code.
Editions don’t come out every year, only when the Rust project decides one is necessary. For example, there’s no 2020 edition. Setting edition to "2020" causes an error. The Rust Edition Guide covers the changes introduced in each edition and provides good background on the edition system.
It’s almost always a good idea to use the latest edition, especially for new code. cargo new creates new projects on the latest edition by default. This book uses the 2018 edition throughout.
If you have a crate written in an older edition of Rust, the cargo fix command may be able to help you automatically upgrade your code to the newer edition. The Rust Edition Guide explains the cargo fix command in detail.
Build Profiles
There are several configuration settings you can put in your Cargo.toml file that affect the rustc command lines that cargo generates (Table 8-1).
| Command line | Cargo.toml section used |
|---|---|
cargo build |
[profile.dev] |
cargo build --release |
[profile.release] |
cargo test |
[profile.test] |
The defaults are usually fine, but one exception we’ve found is when you want to use a profiler—a tool that measures where your program is spending its CPU time. To get the best data from a profiler, you need both optimizations (usually enabled only in release builds) and debug symbols (usually enabled only in debug builds). To enable both, add this to your Cargo.toml:
[profile.release] debug = true # enable debug symbols in release builds
The debug setting controls the -g option to rustc. With this configuration, when you type cargo build --release, you’ll get a binary with debug symbols. The optimization settings are unaffected.
The Cargo documentation lists many other settings you can adjust in Cargo.toml.
Modules
Whereas crates are about code sharing between projects, modules are about code organization within a project. They act as Rust’s namespaces, containers for the functions, types, constants, and so on that make up your Rust program or library. A module looks like this:
modspores{usecells::{Cell,Gene};/// A cell made by an adult fern. It disperses on the wind as part of/// the fern life cycle. A spore grows into a prothallus -- a whole/// separate organism, up to 5mm across -- which produces the zygote/// that grows into a new fern. (Plant sex is complicated.)pubstructSpore{...}/// Simulate the production of a spore by meiosis.pubfnproduce_spore(factory:&mutSporangium)->Spore{...}/// Extract the genes in a particular spore.pub(crate)fngenes(spore:&Spore)->Vec<Gene>{...}/// Mix genes to prepare for meiosis (part of interphase).fnrecombine(parent:&mutCell){...}...}
A module is a collection of items, named features like the Spore struct and the two functions in this example. The pub keyword makes an item public, so it can be accessed from outside the module.
One function is marked pub(crate), meaning that it is available anywhere inside this crate, but isn’t exposed as part of the external interface. It can’t be used by other crates, and it won’t show up in this crate’s documentation.
Anything that isn’t marked pub is private and can only be used in the same module in which it is defined, or any child modules:
lets=spores::produce_spore(&mutfactory);// okspores::recombine(&mutcell);// error: `recombine` is private
Marking an item as pub is often known as “exporting” that item.
The rest of this section covers the details you’ll need to know to make full use of modules:
-
We show how to nest modules and distribute them across different files and directories, if needed.
-
We explain the path syntax Rust uses to refer to items from other modules and show how to import items so that you can use them without having to write out their full paths.
-
We touch on Rust’s fine-grained control for struct fields.
-
We introduce prelude modules, which reduce boilerplate by gathering together common imports that almost any user will need.
-
We present constants and statics, two ways to define named values, for clarity and consistency.
Nested Modules
Modules can nest, and it’s fairly common to see a module that’s just a collection of submodules:
modplant_structures{pubmodroots{...}pubmodstems{...}pubmodleaves{...}}
If you want an item in a nested module to be visible to other crates, be sure to mark it and all enclosing modules as public. Otherwise you may see a warning like this:
warning: function is never used: `is_square`--> src/crates_unused_items.rs:23:9|23 | / pub fn is_square(root: &Root) -> bool {24 | | root.cross_section_shape().is_square()25 | | }| |_________^|
Perhaps this function really is dead code at the moment. But if you meant to use it in other crates, Rust is letting you know that it’s not actually visible to them. You should make sure its enclosing modules are all pub as well.
It’s also possible to specify pub(super), making an item visible to the parent module only, and pub(in <path>), which makes it visible in a specific parent module and its descendants. This is especially useful with deeply nested modules:
modplant_structures{pubmodroots{pubmodproducts{pub(incrate::plant_structures::roots)structCytokinin{...}}useproducts::Cytokinin;// ok: in `roots` module}useroots::products::Cytokinin;// error: `Cytokinin` is private}// error: `Cytokinin` is privateuseplant_structures::roots::products::Cytokinin;
In this way, we could write out a whole program, with a huge amount of code and a whole hierarchy of modules, related in whatever ways we wanted, all in a single source file.
Actually working that way is a pain, though, so there’s an alternative.
Modules in Separate Files
A module can also be written like this:
modspores;
Earlier, we included the body of the spores module, wrapped in curly braces. Here, we’re instead telling the Rust compiler that the spores module lives in a separate file, called spores.rs:
// spores.rs/// A cell made by an adult fern...pubstructSpore{...}/// Simulate the production of a spore by meiosis.pubfnproduce_spore(factory:&mutSporangium)->Spore{...}/// Extract the genes in a particular spore.pub(crate)fngenes(spore:&Spore)->Vec<Gene>{...}/// Mix genes to prepare for meiosis (part of interphase).fnrecombine(parent:&mutCell){...}
spores.rs contains only the items that make up the module. It doesn’t need any kind of boilerplate to declare that it’s a module.
The location of the code is the only difference between this spores module and the version we showed in the previous section. The rules about what’s public and what’s private are exactly the same either way. And Rust never compiles modules separately, even if they’re in separate files: when you build a Rust crate, you’re recompiling all of its modules.
A module can have its own directory. When Rust sees mod spores;, it checks for both spores.rs and spores/mod.rs; if neither file exists, or both exist, that’s an error. For this example, we used spores.rs, because the spores module did not have any submodules. But consider the plant_structures module we wrote out earlier. If we decide to split that module and its three submodules into their own files, the resulting project would look like this:
fern_sim/├── Cargo.toml└── src/├── main.rs├── spores.rs└── plant_structures/├── mod.rs├── leaves.rs├── roots.rs└── stems.rs
In main.rs, we declare the plant_structures module:
pubmodplant_structures;
This causes Rust to load plant_structures/mod.rs, which declares the three submodules:
// in plant_structures/mod.rspubmodroots;pubmodstems;pubmodleaves;
The content of those three modules is stored in separate files named leaves.rs, roots.rs, and stems.rs, located alongside mod.rs in the plant_structures directory.
It’s also possible to use a file and directory with the same name to make up a module. For instance, if stems needed to include modules called xylem and phloem, we could choose to keep stems in plant_structures/stems.rs and add a stems directory:
fern_sim/├── Cargo.toml└── src/├── main.rs├── spores.rs└── plant_structures/├── mod.rs├── leaves.rs├── roots.rs├── stems/│ ├── phloem.rs│ └── xylem.rs└── stems.rs
Then, in stems.rs, we declare the two new submodules:
// in plant_structures/stems.rspubmodxylem;pubmodphloem;
These three options—modules in their own file, modules in their own directory with a mod.rs, and modules in their own file with a supplementary directory containing submodules—give the module system enough flexibility to support almost any project structure you might desire.
Paths and Imports
The :: operator is used to access features of a module. Code anywhere in your project can refer to any standard library feature by writing out its path:
ifs1>s2{std::mem::swap(&muts1,&muts2);}
std is the name of the standard library. The path std refers to the top-level module of the standard library. std::mem is a submodule within the standard library, and std::mem::swap is a public function in that module.
You could write all your code this way, spelling out std::f64::consts::PI and std::collections::HashMap::new every time you want a circle or a dictionary, but it would be tedious to type and hard to read. The alternative is to import features into the modules where they’re used:
usestd::mem;ifs1>s2{mem::swap(&muts1,&muts2);}
The use declaration causes the name mem to be a local alias for std::mem throughout the enclosing block or module.
We could write use std::mem::swap; to import the swap function itself instead of the mem module. However, what we did earlier is generally considered the best style: import types, traits, and modules (like std::mem) and then use relative paths to access the functions, constants, and other members within.
Several names can be imported at once:
usestd::collections::{HashMap,HashSet};// import bothusestd::fs::{self,File};// import both `std::fs` and `std::fs::File`.usestd::io::prelude::*;// import everything
This is just shorthand for writing out all the individual imports:
usestd::collections::HashMap;usestd::collections::HashSet;usestd::fs;usestd::fs::File;// all the public items in std::io::prelude:usestd::io::prelude::Read;usestd::io::prelude::Write;usestd::io::prelude::BufRead;usestd::io::prelude::Seek;
You can use as to import an item but give it a different name locally:
usestd::io::ResultasIOResult;// This return type is just another way to write `std::io::Result<()>`:fnsave_spore(spore:&Spore)->IOResult<()>...
Modules do not automatically inherit names from their parent modules. For example, suppose we have this in our proteins/mod.rs:
// proteins/mod.rspubenumAminoAcid{...}pubmodsynthesis;
Then the code in synthesis.rs does not automatically see the type AminoAcid:
// proteins/synthesis.rspubfnsynthesize(seq:&[AminoAcid])// error: can't find type `AminoAcid`...
Instead, each module starts with a blank slate and must import the names it uses:
// proteins/synthesis.rsusesuper::AminoAcid;// explicitly import from parentpubfnsynthesize(seq:&[AminoAcid])// ok...
By default, paths are relative to the current module:
// in proteins/mod.rs// import from a submoduleusesynthesis::synthesize;
self is also a synonym for the current module, so we could write either:
// in proteins/mod.rs// import names from an enum,// so we can write `Lys` for lysine, rather than `AminoAcid::Lys`useself::AminoAcid::*;
or simply:
// in proteins/mod.rsuseAminoAcid::*;
(The AminoAcid example here is, of course, a departure from the style rule we mentioned earlier about only importing types, traits, and modules. If our program includes long amino acid sequences, this is justified under Orwell’s Sixth Rule: “Break any of these rules sooner than say anything outright barbarous.”)
The keywords super and crate have a special meaning in paths: super refers to the parent module, and crate refers to the crate containing the current module.
Using paths relative to the crate root rather than the current module makes it easier to move code around the project, since all the imports won’t break if the path of the current module changes. For example, we could write synthesis.rs using crate:
// proteins/synthesis.rsusecrate::proteins::AminoAcid;// explicitly import relative to crate rootpubfnsynthesize(seq:&[AminoAcid])// ok...
Submodules can access private items in their parent modules with use super::*.
If you have a module with the same name as a crate that you are using, then referring to their contents takes some care. For example, if your program lists the image crate as a dependency in its Cargo.toml file, but also has a module named image, then paths starting with image are ambiguous:
modimage{pubstructSampler{...}}// error: Does this refer to our `image` module, or the `image` crate?useimage::Pixels;
Even though the image module has no Pixels type, the ambiguity is still considered an error: it would be confusing if adding such a definition later could silently change what paths elsewhere in the program refer to.
To resolve the ambiguity, Rust has a special kind of path called an absolute path, starting with ::, which always refers to an external crate. To refer to the Pixels type in the image crate, you can write:
use::image::Pixels;// the `image` crate's `Pixels`
To refer to your own module’s Sampler type, you can write:
useself::image::Sampler;// the `image` module's `Sampler`
Modules aren’t the same thing as files, but there is a natural analogy between modules and the files and directories of a Unix filesystem. The use keyword creates aliases, just as the ln command creates links. Paths, like filenames, come in absolute and relative forms. self and super are like the . and .. special directories.
The Standard Prelude
We said a moment ago that each module starts with a “blank slate,” as far as imported names are concerned. But the slate is not completely blank.
For one thing, the standard library std is automatically linked with every project. This means you can always go with use std::whatever or refer to std items by name, like std::mem::swap() inline in your code. Furthermore, a few particularly handy names, like Vec and Result, are included in the standard prelude and automatically imported. Rust behaves as though every module, including the root module, started with the following import:
usestd::prelude::v1::*;
The standard prelude contains a few dozen commonly used traits and types.
In Chapter 2, we mentioned that libraries sometimes provide modules named prelude. But std::prelude::v1 is the only prelude that is ever imported automatically. Naming a module prelude is just a convention that tells users it’s meant to be imported using *.
Making use Declarations pub
Even though use declarations are just aliases, they can be public:
// in plant_structures/mod.rs...pubuseself::leaves::Leaf;pubuseself::roots::Root;
This means that Leaf and Root are public items of the plant_structures module. They are still simple aliases for plant_structures::leaves::Leaf and plant_structures::roots::Root.
The standard prelude is written as just such a series of pub imports.
Making Struct Fields pub
A module can include user-defined struct types, introduced using the struct keyword. We cover these in detail in Chapter 9, but this is a good point to mention how modules interact with the visibility of struct fields.
A simple struct looks like this:
pubstructFern{pubroots:RootSet,pubstems:StemSet}
A struct’s fields, even private fields, are accessible throughout the module where the struct is declared, and its submodules. Outside the module, only public fields are accessible.
It turns out that enforcing access control by module, rather than by class as in Java or C++, is surprisingly helpful for software design. It cuts down on boilerplate “getter” and “setter” methods, and it largely eliminates the need for anything like C++ friend declarations. A single module can define several types that work closely together, such as perhaps frond::LeafMap and frond::LeafMapIter, accessing each other’s private fields as needed, while still hiding those implementation details from the rest of your program.
Statics and Constants
In addition to functions, types, and nested modules, modules can also define constants and statics.
The const keyword introduces a constant. The syntax is just like let except that it may be marked pub, and the type is required. Also, UPPERCASE_NAMES are conventional for constants:
pubconstROOM_TEMPERATURE:f64=20.0;// degrees Celsius
The static keyword introduces a static item, which is nearly the same thing:
pubstaticROOM_TEMPERATURE:f64=68.0;// degrees Fahrenheit
A constant is a bit like a C++ #define: the value is compiled into your code every place it’s used. A static is a variable that’s set up before your program starts running and lasts until it exits. Use constants for magic numbers and strings in your code. Use statics for larger amounts of data, or any time you need to borrow a reference to the constant value.
There are no mut constants. Statics can be marked mut, but as discussed in Chapter 5, Rust has no way to enforce its rules about exclusive access on mut statics. They are, therefore, inherently non-thread-safe, and safe code can’t use them at all:
staticmutPACKETS_SERVED:usize=0;println!("{} served",PACKETS_SERVED);// error: use of mutable static
Rust discourages global mutable state. For a discussion of the alternatives, see “Global Variables”.
Turning a Program into a Library
As your fern simulator starts to take off, you decide you need more than a single program. Suppose you’ve got one command-line program that runs the simulation and saves results in a file. Now, you want to write other programs for performing scientific analysis of the saved results, displaying 3D renderings of the growing plants in real time, rendering photorealistic pictures, and so on. All these programs need to share the basic fern simulation code. You need to make a library.
The first step is to factor your existing project into two parts: a library crate, which contains all the shared code, and an executable, which contains the code that’s only needed for your existing command-line program.
To show how you can do this, let’s use a grossly simplified example program:
structFern{size:f64,growth_rate:f64}implFern{/// Simulate a fern growing for one day.fngrow(&mutself){self.size*=1.0+self.growth_rate;}}/// Run a fern simulation for some number of days.fnrun_simulation(fern:&mutFern,days:usize){for_in0..days{fern.grow();}}fnmain(){letmutfern=Fern{size:1.0,growth_rate:0.001};run_simulation(&mutfern,1000);println!("final fern size: {}",fern.size);}
We’ll assume that this program has a trivial Cargo.toml file:
[package] name = "fern_sim" version = "0.1.0" authors = ["You <you@example.com>"] edition = "2018"
Turning this program into a library is easy. Here are the steps:
-
Rename the file src/main.rs to src/lib.rs.
-
Add the
pubkeyword to items in src/lib.rs that will be public features of our library. -
Move the
mainfunction to a temporary file somewhere. We’ll come back to it in a minute.
The resulting src/lib.rs file looks like this:
pubstructFern{pubsize:f64,pubgrowth_rate:f64}implFern{/// Simulate a fern growing for one day.pubfngrow(&mutself){self.size*=1.0+self.growth_rate;}}/// Run a fern simulation for some number of days.pubfnrun_simulation(fern:&mutFern,days:usize){for_in0..days{fern.grow();}}
Note that we didn’t need to change anything in Cargo.toml. This is because our minimal Cargo.toml file leaves Cargo to its default behavior. By default, cargo build looks at the files in our source directory and figures out what to build. When it sees the file src/lib.rs, it knows to build a library.
The code in src/lib.rs forms the root module of the library. Other crates that use our library can only access the public items of this root module.
The src/bin Directory
Getting the original command-line fern_sim program working again is also straightforward: Cargo has some built-in support for small programs that live in the same crate as a library.
In fact, Cargo itself is written this way. The bulk of the code is in a Rust library. The cargo command-line program that we’ve been using throughout this book is a thin wrapper program that calls out to the library for all the heavy lifting. Both the library and the command-line program live in the same source repository.
We can keep our program and our library in the same crate, too. Put this code into a file named src/bin/efern.rs:
usefern_sim::{Fern,run_simulation};fnmain(){letmutfern=Fern{size:1.0,growth_rate:0.001};run_simulation(&mutfern,1000);println!("final fern size: {}",fern.size);}
The main function is the one we set aside earlier. We’ve added a use declaration for some items from the fern_sim crate, Fern and run_simulation. In other words, we’re using that crate as a library.
Because we’ve put this file into src/bin, Cargo will compile both the fern_sim library and this program the next time we run cargo build. We can run the efern program using cargo run --bin efern. Here’s what it looks like, using --verbose to show the commands Cargo is running:
$cargo build --verboseCompiling fern_sim v0.1.0 (file:///.../fern_sim)Running `rustc src/lib.rs --crate-name fern_sim --crate-type lib ...`Running `rustc src/bin/efern.rs --crate-name efern --crate-type bin ...`$cargo run --bin efern --verboseFresh fern_sim v0.1.0 (file:///.../fern_sim)Running `target/debug/efern`final fern size: 2.7169239322355985
We still didn’t have to make any changes to Cargo.toml, because, again, Cargo’s default is to look at your source files and figure things out. It automatically treats .rs files in src/bin as extra programs to build.
We can also build larger programs in the src/bin directory using subdirectories. Suppose we want to provide a second program that draws a fern on the screen, but the drawing code is large and modular, so it belongs in its own file. We can give the second program its own subdirectory:
fern_sim/├── Cargo.toml└── src/└── bin/├── efern.rs└── draw_fern/├── main.rs└── draw.rs
This has the advantage of letting larger binaries have their own submodules without cluttering up either the library code or the src/bin directory.
Of course, now that fern_sim is a library, we also have another option. We could have put this program in its own isolated project, in a completely separate directory, with its own Cargo.toml listing fern_sim as a dependency:
[dependencies]
fern_sim = { path = "../fern_sim" }
Perhaps that is what you’ll do for other fern-simulating programs down the road. The src/bin directory is just right for simple programs like efern and draw_fern.
Attributes
Any item in a Rust program can be decorated with attributes. Attributes are Rust’s catchall syntax for writing miscellaneous instructions and advice to the compiler. For example, suppose you’re getting this warning:
libgit2.rs: warning: type `git_revspec` should have a camel case namesuch as `GitRevspec`, #[warn(non_camel_case_types)] on by default
But you chose this name for a reason, and you wish Rust would shut up about it. You can disable the warning by adding an #[allow] attribute on the type:
#[allow(non_camel_case_types)]pubstructgit_revspec{...}
Conditional compilation is another feature that’s written using an attribute, namely, #[cfg]:
// Only include this module in the project if we're building for Android.#[cfg(target_os ="android")]modmobile;
The full syntax of #[cfg] is specified in the Rust Reference; the most commonly used options are listed in Table 8-2.
#[cfg(...)] option |
Enabled when |
|---|---|
test |
Tests are enabled (compiling with cargo test or rustc --test). |
debug_assertions |
Debug assertions are enabled (typically in nonoptimized builds). |
unix |
Compiling for Unix, including macOS. |
windows |
Compiling for Windows. |
target_pointer_width = "64" |
Targeting a 64-bit platform. The other possible value is "32". |
target_arch = "x86_64" |
Targeting x86-64 in particular. Other values: "x86", "arm", "aarch64", "powerpc", "powerpc64", "mips". |
target_os = "macos" |
Compiling for macOS. Other values: "windows", "ios", "android", "linux", "freebsd", "openbsd", "netbsd", "dragonfly". |
feature = "robots" |
The user-defined feature named "robots" is enabled (compiling with cargo build --feature robots or rustc --cfg feature='"robots"'). Features are declared in the [features] section of Cargo.toml. |
not(A) |
A is not satisfied. To provide two different implementations of a function, mark one with #[cfg(X)] and the other with #[cfg(not(X))]. |
all(A,B) |
Both A and B are satisfied (the equivalent of &&). |
any(A,B) |
Either A or B is satisfied (the equivalent of ||). |
Occasionally, we need to micromanage the inline expansion of functions, an optimization that we’re usually happy to leave to the compiler. We can use the #[inline] attribute for that:
/// Adjust levels of ions etc. in two adjacent cells/// due to osmosis between them.#[inline]fndo_osmosis(c1:&mutCell,c2:&mutCell){...}
There’s one situation where inlining won’t happen without #[inline]. When a function or method defined in one crate is called in another crate, Rust won’t inline it unless it’s generic (it has type parameters) or it’s explicitly marked #[inline].
Otherwise, the compiler treats #[inline] as a suggestion. Rust also supports the more insistent #[inline(always)], to request that a function be expanded inline at every call site, and #[inline(never)], to ask that a function never be inlined.
Some attributes, like #[cfg] and #[allow], can be attached to a whole module and apply to everything in it. Others, like #[test] and #[inline], must be attached to individual items. As you might expect for a catchall feature, each attribute is custom-made and has its own set of supported arguments. The Rust Reference documents the full set of supported attributes in detail.
To attach an attribute to a whole crate, add it at the top of the main.rs or lib.rs file, before any items, and write #! instead of #, like this:
// libgit2_sys/lib.rs#![allow(non_camel_case_types)]pubstructgit_revspec{...}pubstructgit_error{...}
The #! tells Rust to attach an attribute to the enclosing item rather than whatever comes next: in this case, the #![allow] attribute attaches to the whole libgit2_sys crate, not just struct git_revspec.
#! can also be used inside functions, structs, and so on, but it’s only typically used at the beginning of a file, to attach an attribute to the whole module or crate. Some attributes always use the #! syntax because they can only be applied to a whole crate.
For example, the #![feature] attribute is used to turn on unstable features of the Rust language and libraries, features that are experimental, and therefore might have bugs or might be changed or removed in the future. For instance, as we’re writing this, Rust has experimental support for tracing the expansion of macros like assert!, but since this support is experimental, you can only use it by (1) installing the nightly version of Rust and (2) explicitly declaring that your crate uses macro tracing:
#![feature(trace_macros)]fnmain(){// I wonder what actual Rust code this use of assert_eq!// gets replaced with!trace_macros!(true);assert_eq!(10*10*10+9*9*9,12*12*12+1*1*1);trace_macros!(false);}
Over time, the Rust team sometimes stabilizes an experimental feature so that it becomes a standard part of the language. The #![feature] attribute then becomes superfluous, and Rust generates a warning advising you to remove it.
Tests and Documentation
As we saw in “Writing and Running Unit Tests”, a simple unit testing framework is built into Rust. Tests are ordinary functions marked with the #[test] attribute:
#[test]fnmath_works(){letx:i32=1;assert!(x.is_positive());assert_eq!(x+1,2);}
cargo test runs all the tests in your project:
$cargotestCompiling math_test v0.1.0 (file:///.../math_test)Running target/release/math_test-e31ed91ae51ebf22running 1 testtest math_works ... oktest result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
(You’ll also see some output about “doc-tests,” which we’ll get to in a minute.)
This works the same whether your crate is an executable or a library. You can run specific tests by passing arguments to Cargo: cargo test math runs all tests that contain math somewhere in their name.
Tests commonly use the assert! and assert_eq! macros from the Rust standard library. assert!(expr) succeeds if expr is true. Otherwise, it panics, which causes the test to fail. assert_eq!(v1, v2) is just like assert!(v1 == v2) except that if the assertion fails, the error message shows both values.
You can use these macros in ordinary code, to check invariants, but note that assert! and assert_eq! are included even in release builds. Use debug_assert! and debug_assert_eq! instead to write assertions that are checked only in debug builds.
To test error cases, add the #[should_panic] attribute to your test:
/// This test passes only if division by zero causes a panic,/// as we claimed in the previous chapter.#[test]#[allow(unconditional_panic, unused_must_use)]#[should_panic(expected="divide by zero")]fntest_divide_by_zero_error(){1/0;// should panic!}
In this case, we also need to add an allow attribute to tell the compiler to let us do things that it can statically prove will panic, and perform divisions and just throw away the answer, because normally, it tries to stop that kind of silliness.
You can also return a Result<(), E> from your tests. As long as the error variant is Debug, which is usually the case, you can simply return a Result by using ? to throw away the Ok variant:
usestd::num::ParseIntError;/// This test will pass if "1024" is a valid number, which it is.#[test]fnmain()->Result<(),ParseIntError>{i32::from_str_radix("1024",10)?;Ok(())}
Functions marked with #[test] are compiled conditionally. A plain cargo build or cargo build --release skips the testing code. But when you run cargo test, Cargo builds your program twice: once in the ordinary way and once with your tests and the test harness enabled. This means your unit tests can live right alongside the code they test, accessing internal implementation details if they need to, and yet there’s no run-time cost. However, it can result in some warnings. For example:
fnroughly_equal(a:f64,b:f64)->bool{(a-b).abs()<1e-6}#[test]fntrig_works(){usestd::f64::consts::PI;assert!(roughly_equal(PI.sin(),0.0));}
In builds that omit the test code, roughly_equal appears unused, and Rust will complain:
$cargo buildCompiling math_test v0.1.0 (file:///.../math_test)warning: function is never used: `roughly_equal`--> src/crates_unused_testing_function.rs:7:1|7 | / fn roughly_equal(a: f64, b: f64) -> bool {8 | | (a - b).abs() < 1e-69 | | }| |_^|= note: #[warn(dead_code)] on by default
So the convention, when your tests get substantial enough to require support code, is to put them in a tests module and declare the whole module to be testing-only using the #[cfg] attribute:
#[cfg(test)]// include this module only when testingmodtests{fnroughly_equal(a:f64,b:f64)->bool{(a-b).abs()<1e-6}#[test]fntrig_works(){usestd::f64::consts::PI;assert!(roughly_equal(PI.sin(),0.0));}}
Rust’s test harness uses multiple threads to run several tests at a time, a nice side benefit of your Rust code being thread-safe by default. To disable this, either run a single test, cargo test testname, or run cargo test -- --test-threads 1. (The first -- ensures that cargo test passes the --test-threads option through to the test executable.) This means that, technically, the Mandelbrot program we showed in Chapter 2 was not the second multithreaded program in that chapter, but the third! The cargo test run in “Writing and Running Unit Tests” was the first.
Normally, the test harness only shows the output of tests that failed. To show the output from tests that pass too, run cargo test -- --no-capture.
Integration Tests
Your fern simulator continues to grow. You’ve decided to put all the major functionality into a library that can be used by multiple executables. It would be nice to have some tests that link with the library the way an end user would, using fern_sim.rlib as an external crate. Also, you have some tests that start by loading a saved simulation from a binary file, and it is awkward having those large test files in your src directory. Integration tests help with these two problems.
Integration tests are .rs files that live in a tests directory alongside your project’s src directory. When you run cargo test, Cargo compiles each integration test as a separate, standalone crate, linked with your library and the Rust test harness. Here is an example:
// tests/unfurl.rs - Fiddleheads unfurl in sunlightusefern_sim::Terrarium;usestd::time::Duration;#[test]fntest_fiddlehead_unfurling(){letmutworld=Terrarium::load("tests/unfurl_files/fiddlehead.tm");assert!(world.fern(0).is_furled());letone_hour=Duration::from_secs(60*60);world.apply_sunlight(one_hour);assert!(world.fern(0).is_fully_unfurled());}
Integration tests are valuable in part because they see your crate from the outside, just as a user would. They test the crate’s public API.
cargo test runs both unit tests and integration tests. To run only the integration tests in a particular file—for example, tests/unfurl.rs—use the command cargo test --test unfurl.
Documentation
The command cargo doc creates HTML documentation for your library:
$cargo doc --no-deps --openDocumenting fern_sim v0.1.0 (file:///.../fern_sim)
The --no-deps option tells Cargo to generate documentation only for fern_sim itself, and not for all the crates it depends on.
The --open option tells Cargo to open the documentation in your browser afterward.
You can see the result in Figure 8-2. Cargo saves the new documentation files in target/doc. The starting page is target/doc/fern_sim/index.html.

Figure 8-2. Example of documentation generated by rustdoc
The documentation is generated from the pub features of your library, plus any doc comments you’ve attached to them. We’ve seen a few doc comments in this chapter already. They look like comments:
/// Simulate the production of a spore by meiosis.pubfnproduce_spore(factory:&mutSporangium)->Spore{...}
But when Rust sees comments that start with three slashes, it treats them as a #[doc] attribute instead. Rust treats the preceding example exactly the same as this:
#[doc ="Simulate the production of a spore by meiosis."]pubfnproduce_spore(factory:&mutSporangium)->Spore{...}
When you compile a library or binary, these attributes don’t change anything, but when you generate documentation, doc comments on public features are included in the output.
Likewise, comments starting with //! are treated as #![doc] attributes and are attached to the enclosing feature, typically a module or crate. For example, your fern_sim/src/lib.rs file might begin like this:
//! Simulate the growth of ferns, from the level of//! individual cells on up.
The content of a doc comment is treated as Markdown, a shorthand notation for simple HTML formatting. Asterisks are used for *italics* and **bold type**, a blank line is treated as a paragraph break, and so on. You can also include HTML tags, which are copied verbatim into the formatted documentation.
One special feature of doc comments in Rust is that Markdown links can use Rust item paths, like leaves::Leaf, instead of relative URLs, to indicate what they refer to. Cargo will look up what the path refers to and subtitute a link to the right place in the right documentation page. For example, the documentation generated from this code links to the documentation pages for VascularPath, Leaf, and Root:
/// Create and return a [`VascularPath`] which represents the path of/// nutrients from the given [`Root`][r] to the given [`Leaf`](leaves::Leaf).////// [r]: roots::Rootpubfntrace_path(leaf:&leaves::Leaf,root:&roots::Root)->VascularPath{...}
You can also add search aliases to make it easier to find things using the built-in search feature. Searching for either “path” or “route” in this crate’s documentation will lead to VascularPath:
#[doc(alias ="route")]pubstructVascularPath{...}
You can use `backticks` to set off bits of code in the middle of running text. In the output, these snippets will be formatted in a fixed-width font. Larger code samples can be added by indenting four spaces:
/// A block of code in a doc comment:////// if samples::everything().works() {/// println!("ok");/// }
You can also use Markdown-fenced code blocks. This has exactly the same effect:
/// Another snippet, the same code, but written differently:////// ```/// if samples::everything().works() {/// println!("ok");/// }/// ```
Whichever format you use, an interesting thing happens when you include a block of code in a doc comment. Rust automatically turns it into a test.
Doc-Tests
When you run tests in a Rust library crate, Rust checks that all the code that appears in your documentation actually runs and works. It does this by taking each block of code that appears in a doc comment, compiling it as a separate executable crate, linking it with your library, and running it.
Here is a standalone example of a doc-test. Create a new project by running cargo new --lib ranges (the --lib flag tells Cargo we’re creating a library crate, not an executable crate) and put the following code in ranges/src/lib.rs:
usestd::ops::Range;/// Return true if two ranges overlap.////// assert_eq!(ranges::overlap(0..7, 3..10), true);/// assert_eq!(ranges::overlap(1..5, 101..105), false);////// If either range is empty, they don't count as overlapping.////// assert_eq!(ranges::overlap(0..0, 0..10), false);///pubfnoverlap(r1:Range<usize>,r2:Range<usize>)->bool{r1.start<r1.end&&r2.start<r2.end&&r1.start<r2.end&&r2.start<r1.end}
The two small blocks of code in the doc comment appear in the documentation generated by cargo doc, as shown in Figure 8-3.

Figure 8-3. Documentation showing some doc-tests
They also become two separate tests:
$cargotestCompiling ranges v0.1.0 (file:///.../ranges)...Doc-tests rangesrunning 2 teststest overlap_0 ... oktest overlap_1 ... oktest result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out
If you pass the --verbose flag to Cargo, you’ll see that it’s using rustdoc --test to run these two tests. rustdoc stores each code sample in a separate file, adding a few lines of boilerplate code, to produce two programs. Here’s the first:
useranges;fnmain(){assert_eq!(ranges::overlap(0..7,3..10),true);assert_eq!(ranges::overlap(1..5,101..105),false);}
And here’s the second:
useranges;fnmain(){assert_eq!(ranges::overlap(0..0,0..10),false);}
The tests pass if these programs compile and run successfully.
These two code samples contain assertions, but that’s just because in this case, the assertions make decent documentation. The idea behind doc-tests is not to put all your tests into comments. Rather, you write the best possible documentation, and Rust makes sure the code samples in your documentation actually compile and run.
Very often a minimal working example includes some details, such as imports or setup code, that are necessary to make the code compile, but just aren’t important enough to show in the documentation. To hide a line of a code sample, put a # followed by a space at the beginning of that line:
/// Let the sun shine in and run the simulation for a given/// amount of time.////// # use fern_sim::Terrarium;/// # use std::time::Duration;/// # let mut tm = Terrarium::new();/// tm.apply_sunlight(Duration::from_secs(60));///pubfnapply_sunlight(&mutself,time:Duration){...}
Sometimes it’s helpful to show a complete sample program in documentation, including a main function. Obviously, if those pieces of code appear in your code sample, you do not also want rustdoc to add them automatically. The result wouldn’t compile. rustdoc therefore treats any code block containing the exact string fn main as a complete program and doesn’t add anything to it.
Testing can be disabled for specific blocks of code. To tell Rust to compile your example, but stop short of actually running it, use a fenced code block with the no_run annotation:
/// Upload all local terrariums to the online gallery.////// ```no_run/// let mut session = fern_sim::connect();/// session.upload_all();/// ```pubfnupload_all(&mutself){...}
If the code isn’t even expected to compile, use ignore instead of no_run. Blocks marked with ignore don’t show up in the output of cargo run, but no_run tests show up as having passed if they compile. If the code block isn’t Rust code at all, use the name of the language, like c++ or sh, or text for plain text. rustdoc doesn’t know the names of hundreds of programming languages; rather, it treats any annotation it doesn’t recognize as indicating that the code block isn’t Rust. This disables code highlighting as well as doc-testing.
Specifying Dependencies
We’ve seen one way of telling Cargo where to get source code for crates your project depends on: by version number.
image = "0.6.1"
There are several ways to specify dependencies, and some rather nuanced things you might want to say about which versions to use, so it’s worth spending a few pages on this.
First of all, you may want to use dependencies that aren’t published on crates.io at all. One way to do this is by specifying a Git repository URL and revision:
image = { git = "https://github.com/Piston/image.git", rev = "528f19c" }
This particular crate is open source, hosted on GitHub, but you could just as easily point to a private Git repository hosted on your corporate network. As shown here, you can specify the particular rev, tag, or branch to use. (These are all ways of telling Git which revision of the source code to check out.)
Another alternative is to specify a directory that contains the crate’s source code:
image = { path = "vendor/image" }
This is convenient when your team has a single version control repository that contains source code for several crates, or perhaps the entire dependency graph. Each crate can specify its dependencies using relative paths.
Having this level of control over your dependencies is powerful. If you ever decide that any of the open source crates you use isn’t exactly to your liking, you can trivially fork it: just hit the Fork button on GitHub and change one line in your Cargo.toml file. Your next cargo build will seamlessly use your fork of the crate instead of the official version.
Versions
When you write something like image = "0.13.0" in your Cargo.toml file, Cargo interprets this rather loosely. It uses the most recent version of image that is considered compatible with version 0.13.0.
The compatibility rules are adapted from Semantic Versioning.
-
A version number that starts with 0.0 is so raw that Cargo never assumes it’s compatible with any other version.
-
A version number that starts with 0.x, where x is nonzero, is considered compatible with other point releases in the 0.x series. We specified
imageversion 0.6.1, but Cargo would use 0.6.3 if available. (This is not what the Semantic Versioning standard says about 0.x version numbers, but the rule proved too useful to leave out.) -
Once a project reaches 1.0, only new major versions break compatibility. So if you ask for version 2.0.1, Cargo might use 2.17.99 instead, but not 3.0.
Version numbers are flexible by default because otherwise the problem of which version to use would quickly become overconstrained. Suppose one library, libA, used num = "0.1.31" while another, libB, used num = "0.1.29". If version numbers required exact matches, no project would be able to use those two libraries together. Allowing Cargo to use any compatible version is a much more practical default.
Still, different projects have different needs when it comes to dependencies and versioning. You can specify an exact version or range of versions by using operators, as illustrated in Table 8-3.
| Cargo.toml line | Meaning |
|---|---|
image = "=0.10.0" |
Use only the exact version 0.10.0 |
image = ">=1.0.5" |
Use 1.0.5 or any higher version (even 2.9, if it’s available) |
image = ">1.0.5 <1.1.9" |
Use a version that’s higher than 1.0.5, but lower than 1.1.9 |
image = "<=2.7.10" |
Use any version up to 2.7.10 |
Another version specification you’ll occasionally see is the wildcard *. This tells Cargo that any version will do. Unless some other Cargo.toml file contains a more specific constraint, Cargo will use the latest available version. The Cargo documentation at doc.crates.io covers version specifications in even more detail.
Note that the compatibility rules mean that version numbers can’t be chosen purely for marketing reasons. They actually mean something. They’re a contract between a crate’s maintainers and its users. If you maintain a crate that’s at version 1.7 and you decide to remove a function or make any other change that isn’t fully backward compatible, you must bump your version number to 2.0. If you were to call it 1.8, you’d be claiming that the new version is compatible with 1.7, and your users might find themselves with broken builds.
Cargo.lock
The version numbers in Cargo.toml are deliberately flexible, yet we don’t want Cargo to upgrade us to the latest library versions every time we build. Imagine being in the middle of an intense debugging session when suddenly cargo build upgrades you to a new version of a library. This could be incredibly disruptive. Anything changing in the middle of debugging is bad. In fact, when it comes to libraries, there’s never a good time for an unexpected change.
Cargo therefore has a built-in mechanism to prevent this. The first time you build a project, Cargo outputs a Cargo.lock file that records the exact version of every crate it used. Later builds will consult this file and continue to use the same versions. Cargo upgrades to newer versions only when you tell it to, either by manually bumping up the version number in your Cargo.toml file or by running cargo update:
$cargo updateUpdating registry `https://github.com/rust-lang/crates.io-index`Updating libc v0.2.7 -> v0.2.11Updating png v0.4.2 -> v0.4.3
cargo update only upgrades to the latest versions that are compatible with what you’ve specified in Cargo.toml. If you’ve specified image = "0.6.1", and you want to upgrade to version 0.10.0, you’ll have to change that in Cargo.toml. The next time you build, Cargo will update to the new version of the image library and store the new version number in Cargo.lock.
The preceding example shows Cargo updating two crates that are hosted on crates.io. Something very similar happens for dependencies that are stored in Git. Suppose our Cargo.toml file contains this:
image = { git = "https://github.com/Piston/image.git", branch = "master" }
cargo build will not pull new changes from the Git repository if it sees that we’ve got a Cargo.lock file. Instead, it reads Cargo.lock and uses the same revision as last time. But cargo update will pull from master so that our next build uses the latest revision.
Cargo.lock is automatically generated for you, and you normally won’t edit it by hand. Nonetheless, if your project is an executable, you should commit Cargo.lock to version control. That way, everyone who builds your project will consistently get the same versions. The history of your Cargo.lock file will record your dependency updates.
If your project is an ordinary Rust library, don’t bother committing Cargo.lock. Your library’s downstream users will have Cargo.lock files that contain version information for their entire dependency graph; they will ignore your library’s Cargo.lock file. In the rare case that your project is a shared library (i.e., the output is a .dll, .dylib, or .so file), there is no such downstream cargo user, and you should therefore commit Cargo.lock.
Cargo.toml’s flexible version specifiers make it easy to use Rust libraries in your project and maximize compatibility among libraries. Cargo.lock’s bookkeeping supports consistent, reproducible builds across machines. Together, they go a long way toward helping you avoid dependency hell.
Publishing Crates to crates.io
You’ve decided to publish your fern-simulating library as open source software. Congratulations! This part is easy.
First, make sure Cargo can pack the crate for you.
$cargo packagewarning: manifest has no description, license, license-file, documentation,homepage or repository. See http://doc.crates.io/manifest.html#package-metadatafor more info.Packaging fern_sim v0.1.0 (file:///.../fern_sim)Verifying fern_sim v0.1.0 (file:///.../fern_sim)Compiling fern_sim v0.1.0 (file:///.../fern_sim/target/package/fern_sim-0.1.0)
The cargo package command creates a file (in this case, target/package/fern_sim-0.1.0.crate) containing all your library’s source files, including Cargo.toml. This is the file that you’ll upload to crates.io to share with the world. (You can use cargo package --list to see which files are included.) Cargo then double-checks its work by building your library from the .crate file, just as your eventual users will.
Cargo warns that the [package] section of Cargo.toml is missing some information that will be important to downstream users, such as the license under which you’re distributing the code. The URL in the warning is an excellent resource, so we won’t explain all the fields in detail here. In short, you can fix the warning by adding a few lines to Cargo.toml:
[package] name = "fern_sim" version = "0.1.0" edition = "2018" authors = ["You <you@example.com>"] license = "MIT" homepage = "https://fernsim.example.com/" repository = "https://gitlair.com/sporeador/fern_sim" documentation = "http://fernsim.example.com/docs" description = """ Fern simulation, from the cellular level up. """
Note
Once you publish this crate on crates.io, anyone who downloads your crate can see the Cargo.toml file. So if the authors field contains an email address that you’d rather keep private, now is the time to change it.
Another problem that sometimes arises at this stage is that your Cargo.toml file might be specifying the location of other crates by path, as shown in “Specifying Dependencies”:
image = { path = "vendor/image" }
For you and your team, this might work fine. But naturally, when other people download the fern_sim library, they will not have the same files and directories on their computer that you have. Cargo therefore ignores the path key in automatically downloaded libraries, and this can cause build errors. The fix, however, is straightforward: if your library is going to be published on crates.io, its dependencies should be on crates.io too. Specify a version number instead of a path:
image = "0.13.0"
If you prefer, you can specify both a path, which takes precedence for your own local builds, and a version for all other users:
image = { path = "vendor/image", version = "0.13.0" }
Of course, in that case it’s your responsibility to make sure that the two stay in sync.
Lastly, before publishing a crate, you’ll need to log in to crates.io and get an API key. This step is straightforward: once you have an account on crates.io, your “Account Settings” page will show a cargo login command, like this one:
$ cargo login 5j0dV54BjlXBpUUbfIj7G9DvNl1vsWW1
Cargo saves the key in a configuration file, and the API key should be kept secret, like a password. So run this command only on a computer you control.
That done, the final step is to run cargo publish:
$cargo publishUpdating registry `https://github.com/rust-lang/crates.io-index`Uploading fern_sim v0.1.0 (file:///.../fern_sim)
With this, your library joins thousands of others on crates.io.
Workspaces
As your project continues to grow, you end up writing many crates. They live side by side in a single source repository:
fernsoft/├── .git/...├── fern_sim/│ ├── Cargo.toml│ ├── Cargo.lock│ ├── src/...│ └── target/...├── fern_img/│ ├── Cargo.toml│ ├── Cargo.lock│ ├── src/...│ └── target/...└── fern_video/├── Cargo.toml├── Cargo.lock├── src/...└── target/...
The way Cargo works, each crate has its own build directory, target, which contains a separate build of all that crate’s dependencies. These build directories are completely independent. Even if two crates have a common dependency, they can’t share any compiled code. This is wasteful.
You can save compilation time and disk space by using a Cargo workspace, a collection of crates that share a common build directory and Cargo.lock file.
All you need to do is create a Cargo.toml file in your repository’s root directory and put these lines in it:
[workspace] members = ["fern_sim", "fern_img", "fern_video"]
Here fern_sim etc. are the names of the subdirectories containing your crates. Delete any leftover Cargo.lock files and target directories that exist in those subdirectories.
Once you’ve done this, cargo build in any crate will automatically create and use a shared build directory under the root directory (in this case, fernsoft/target). The command cargo build --workspace builds all crates in the current workspace. cargo test and cargo doc accept the --workspace option as well.
More Nice Things
In case you’re not delighted yet, the Rust community has a few more odds and ends for you:
-
When you publish an open source crate on crates.io, your documentation is automatically rendered and hosted on docs.rs thanks to Onur Aslan.
-
If your project is on GitHub, Travis CI can build and test your code on every push. It’s surprisingly easy to set up; see travis-ci.org for details. If you’re already familiar with Travis, this .travis.yml file will get you started:
language:rustrust:-stable -
You can generate a README.md file from your crate’s top-level doc-comment. This feature is offered as a third-party Cargo plug-in by Livio Ribeiro. Run
cargo install cargo-readmeto install the plug-in, thencargo readme --helpto learn how to use it.
We could go on.
Rust is new, but it’s designed to support large, ambitious projects. It has great tools and an active community. System programmers can have nice things.