Chapter 11. Tailor Swyfte
From the embryonic whale to the monkey with no tail
They Might Be Giants, “Mammal” (1992)
The challenge in this chapter will be to write a version of tail, which is the converse of head from Chapter 4.
The program will show you the last bytes or lines of one or more files or STDIN, usually defaulting to the last 10 lines.
Again the program will have to deal with bad input and will possibly mangle Unicode characters.
Due to some limitations with how Rust currently handles STDIN, the challenge program will read only regular files.
In this chapter, you will learn how to do the following:
-
Initialize a static, global, computed value
-
Seek to a line or byte position in a filehandle
-
Indicate multiple trait bounds on a type using the
whereclause -
Build a release binary with Cargo
-
Benchmark programs to compare runtime performance
How tail Works
To demonstrate how the challenge program should work, I’ll first show you a portion of the manual page for the BSD tail.
Note that the challenge program will only implement some of these features:
TAIL(1) BSD General Commands Manual TAIL(1)
NAME
tail -- display the last part of a file
SYNOPSIS
tail [-F | -f | -r] [-q] [-b number | -c number | -n number] [file ...]
DESCRIPTION
The tail utility displays the contents of file or, by default, its stan-
dard input, to the standard output.
The display begins at a byte, line or 512-byte block location in the
input. Numbers having a leading plus ('+') sign are relative to the
beginning of the input, for example, ''-c +2'' starts the display at the
second byte of the input. Numbers having a leading minus ('-') sign or
no explicit sign are relative to the end of the input, for example,
''-n2'' displays the last two lines of the input. The default starting
location is ''-n 10'', or the last 10 lines of the input.
The BSD version has many options, but these are the only ones relevant to the challenge program:
-c number
The location is number bytes.
-n number
The location is number lines.
-q Suppresses printing of headers when multiple files are being
examined.
If more than a single file is specified, each file is preceded by a
header consisting of the string ''==> XXX <=='' where XXX is the name of
the file unless -q flag is specified.
Here’s part of the manual page for GNU tail, which includes long option names:
TAIL(1) User Commands TAIL(1)
NAME
tail - output the last part of files
SYNOPSIS
tail [OPTION]... [FILE]...
DESCRIPTION
Print the last 10 lines of each FILE to standard output. With more
than one FILE, precede each with a header giving the file name. With
no FILE, or when FILE is -, read standard input.
Mandatory arguments to long options are mandatory for short options
too.
-c, --bytes=K
output the last K bytes; or use -c +K to output bytes starting
with the Kth of each file
-n, --lines=K
output the last K lines, instead of the last 10; or use -n +K to
output starting with the Kth
I’ll use files in the book’s 11_tailr/tests/inputs directory to demonstrate the features of tail that the challenge will implement.
As in previous chapters, there are examples with Windows line endings that must be preserved in the output. The files I’ll use are:
-
empty.txt: an empty file
-
one.txt: a file with one line of UTF-8 Unicode text
-
two.txt: a file with two lines of ASCII text
-
three.txt: a file with three lines of ASCII text and CRLF line terminators
-
ten.txt: a file with 10 lines of ASCII text
Change into the chapter’s directory:
$ cd 11_tailr
By default, tail will show the last 10 lines of a file, which you can see with tests/inputs/ten.txt:
$ tail tests/inputs/ten.txt one two three four five six seven eight nine ten
Run it with -n 4 to see the last four lines:
$ tail -n 4 tests/inputs/ten.txt seven eight nine ten
Use -c 8 to select the last eight bytes of the file.
In the following output, there are six byte-sized characters and two byte-sized newline characters, for a total of eight bytes.
Pipe the output to cat -e to display the dollar sign ($) at the end of each line:
$ tail -c 8 tests/inputs/ten.txt | cat -e ine$ ten$
With multiple input files, tail will print separators between each file.
Any errors opening files (such as for nonexistent or unreadable files) will be noted to STDERR without any file headers.
For instance, blargh represents a nonexistent file in the following command:
$ tail -n 1 tests/inputs/one.txt blargh tests/inputs/three.txt ==> tests/inputs/one.txt <== Öne line, four wordś. tail: blargh: No such file or directory ==> tests/inputs/three.txt <== four words.
The -q flag will suppress the file headers:
$ tail -q -n 1 tests/inputs/*.txt Öne line, four wordś. ten four words. Four words.
The end of tests/inputs/one.txt has a funky Unicode ś thrown in for good measure, which is a multibyte Unicode character. If you request the last four bytes of the file, two will be for ś, one for the period, and one for the final newline:
$ tail -c 4 tests/inputs/one.txt ś.
If you ask for only three, the ś will be split, and you should see the Unicode unknown character:
$ tail -c 3 tests/inputs/one.txt �.
Requesting more lines or bytes than a file contains is not an error and will cause tail to print the entire file:
$ tail -n 1000 tests/inputs/one.txt Öne line, four wordś. $ tail -c 1000 tests/inputs/one.txt Öne line, four wordś.
As noted in the manual pages, -n or -c values may begin with a plus sign to indicate a line or byte position from the beginning of the file rather than the end.
A start position beyond the end of the file is not an error, and tail will print nothing, which you can see if you run tail -n +1000 tests/inputs/one.txt.
In the following command, I use -n +8 to start printing from line 8:
$ tail -n +8 tests/inputs/ten.txt eight nine ten
It’s possible to split multibyte characters with byte selection.
For example, the tests/inputs/one.txt file starts with the Unicode character Ö, which is two bytes long.
In the following command, I use -c +2 to start printing from the second byte, which will split the multibyte character, resulting in the unknown character:
$ tail -c +2 tests/inputs/one.txt �ne line, four wordś.
To start printing from the second character, I must use -c +3 to start printing from the third byte:
$ tail -c +3 tests/inputs/one.txt ne line, four wordś.
Both the BSD and GNU versions will accept 0 and -0 for -n or -c.
The GNU version will show no output at all, while the BSD version will show no output when run with a single file but will still show the file headers when there are multiple input files.
The following behavior of BSD is expected of the challenge program:
$ tail -n 0 tests/inputs/* ==> tests/inputs/empty.txt <== ==> tests/inputs/one.txt <== ==> tests/inputs/ten.txt <== ==> tests/inputs/three.txt <== ==> tests/inputs/two.txt <==
Both versions interpret the value +0 as starting at the zeroth line or byte, so the whole file will be shown:
$ tail -n +0 tests/inputs/one.txt Öne line, four wordś. $ tail -c +0 tests/inputs/one.txt Öne line, four wordś.
Both versions will reject any value for -n or -c that cannot be parsed as an integer:
$ tail -c foo tests/inputs/one.txt tail: illegal offset -- foo
While tail has several more features, this is as much as your program needs to implement.
Getting Started
The challenge program will be called tailr (pronounced tay-ler).
I recommend you begin with cargo new tailr and then add the following dependencies to Cargo.toml:
[dependencies]clap="2.33"num="0.4"regex="1"once_cell="1"[dev-dependencies]assert_cmd="2"predicates="2"rand="0.8"
The
once_cellcrate will be used to create a computed static value.
Copy the book’s 11_tailr/tests directory into your project, and then run cargo test to download the needed crates, build your program, and ensure that you fail all the tests.
Defining the Arguments
Use the same structure for src/main.rs as in the previous chapters:
fnmain(){ifletErr(e)=tailr::get_args().and_then(tailr::run){eprintln!("{}",e);std::process::exit(1);}}
The challenge program should have similar options as headr, but this program will need to handle both positive and negative values for the number of lines or bytes.
In headr, I used the usize type, which is an unsigned integer that can represent only positive values.
In this program, I will use i64, the 64-bit signed integer type, to also store negative numbers.
Additionally, I need some way to differentiate between 0, which means nothing should be selected, and +0, which means everything should be selected.
I decided to create an enum called TakeValue to represent this, but you may choose a different way.
You can start src/lib.rs with the following if you want to follow my lead:
usecrate::TakeValue::*;useclap::{App,Arg};usestd::error::Error;typeMyResult<T>=Result<T,Box<dynError>>;#[derive(Debug, PartialEq)]enumTakeValue{PlusZero,TakeNum(i64),}
This will allow the code to use
PlusZeroinstead ofTakeValue::PlusZero.
The
PartialEqis needed by the tests to compare values.
This variant represents an argument of
+0.
This variant represents a valid integer value.
Here is the Config I suggest you create to represent the program’s arguments:
#[derive(Debug)]pubstructConfig{files:Vec<String>,lines:TakeValue,bytes:Option<TakeValue>,quiet:bool,}
filesis a vector of strings.linesis aTakeValuethat should default toTakeNum(-10)to indicate the last 10 lines.bytesis an optionalTakeValuefor how many bytes to select.The
quietflag is a Boolean for whether or not to suppress the headers between multiple files.
Following is a skeleton for get_args you can fill in:
pubfnget_args()->MyResult<Config>{letmatches=App::new("tailr").version("0.1.0").author("Ken Youens-Clark <kyclark@gmail.com>").about("Rust tail")// What goes here?.get_matches();Ok(Config{files:...lines:...bytes:...quiet:...})}
I suggest you start your run function by printing the config:
pubfnrun(config:Config)->MyResult<()>{println!("{:#?}",config);Ok(())}
First, get your program to print the following usage:
$ cargo run -- -h
tailr 0.1.0
Ken Youens-Clark <kyclark@gmail.com>
Rust tail
USAGE:
tailr [FLAGS] [OPTIONS] <FILE>...
FLAGS:
-h, --help Prints help information
-q, --quiet Suppress headers
-V, --version Prints version information
OPTIONS:
-c, --bytes <BYTES> Number of bytes
-n, --lines <LINES> Number of lines [default: 10]
ARGS:
<FILE>... Input file(s)
If you run the program with no arguments, it should fail with an error that at least one file argument is required because this program will not read STDIN by default:
$ cargo run
error: The following required arguments were not provided:
<FILE>...
USAGE:
tailr <FILE>... --lines <LINES>
For more information try --help
Run the program with a file argument and see if you can get this output:
$ cargo run -- tests/inputs/one.txt
Config {
files: [
"tests/inputs/one.txt",
],
lines: TakeNum(
-10,
),
bytes: None,
quiet: false,
}
The
linesargument should default toTakeNum(-10)to take the last 10 lines.
Run the program with multiple file arguments and the -c option to ensure you get the following output:
$ cargo run -- -q -c 4 tests/inputs/*.txt
Config {
files: [
"tests/inputs/empty.txt",
"tests/inputs/one.txt",
"tests/inputs/ten.txt",
"tests/inputs/three.txt",
"tests/inputs/two.txt",
],
lines: TakeNum(
-10,
),
bytes: Some(
TakeNum(
-4,
),
),
quiet: true,
}
The positional arguments are parsed as
files.The
linesargument is still set to the default.Now
bytesis set toSome(TakeNum(-4))to indicate the last four bytes should be taken.The
-qflag causes thequietoption to betrue.
You probably noticed that the value 4 was parsed as a negative number even though it was provided as a positive value.
The numeric values for lines and bytes should be negative to indicate that the program will take values from the end of the file.
A plus sign is required to indicate that the starting position is from the beginning of the file:
$ cargo run -- -n +5 tests/inputs/ten.txt
The
+5argument indicates the program should start printing on the fifth line.The value is recorded as a positive integer.
Both -n and -c are allowed to have a value of 0, which will mean that no lines or bytes will be shown:
$ cargo run -- tests/inputs/empty.txt -c 0
Config {
files: [
"tests/inputs/empty.txt",
],
lines: TakeNum(
-10,
),
bytes: Some(
TakeNum(
0,
),
),
quiet: false,
}
As with the original versions, the value +0 indicates that the starting point is the beginning of the file, so all the content will be shown:
$ cargo run -- tests/inputs/empty.txt -n +0
Config {
files: [
"tests/inputs/empty.txt",
],
lines: PlusZero,
bytes: None,
quiet: false,
}
Any noninteger value for -n and -c should be rejected:
$ cargo run -- tests/inputs/empty.txt -n foo illegal line count -- foo $ cargo run -- tests/inputs/empty.txt -c bar illegal byte count -- bar
The challenge program should consider -n and -c mutually exclusive:
$ cargo run -- tests/inputs/empty.txt -n 1 -c 1 error: The argument '--lines <LINES>' cannot be used with '--bytes <BYTES>'
Parsing Positive and Negative Numeric Arguments
In Chapter 4, the challenge program validated the numeric arguments using the parse_positive_int function to reject any values that were not positive integers.
This program needs to accept any integer value, and it also needs to handle an optional + or - sign.
Here is the start of the function parse_num I’d like you to write that will accept a &str and will return a TakeValue or an error:
fnparse_num(val:&str)->MyResult<TakeValue>{unimplemented!();}
Add the following unit test to a tests module in your src/lib.rs:
#[cfg(test)]modtests{usesuper::{parse_num,TakeValue::*};#[test]fntest_parse_num(){// All integers should be interpreted as negative numbersletres=parse_num("3");assert!(res.is_ok());assert_eq!(res.unwrap(),TakeNum(-3));// A leading "+" should result in a positive numberletres=parse_num("+3");assert!(res.is_ok());assert_eq!(res.unwrap(),TakeNum(3));// An explicit "-" value should result in a negative numberletres=parse_num("-3");assert!(res.is_ok());assert_eq!(res.unwrap(),TakeNum(-3));// Zero is zeroletres=parse_num("0");assert!(res.is_ok());assert_eq!(res.unwrap(),TakeNum(0));// Plus zero is specialletres=parse_num("+0");assert!(res.is_ok());assert_eq!(res.unwrap(),PlusZero);// Test boundariesletres=parse_num(&i64::MAX.to_string());assert!(res.is_ok());assert_eq!(res.unwrap(),TakeNum(i64::MIN+1));letres=parse_num(&(i64::MIN+1).to_string());assert!(res.is_ok());assert_eq!(res.unwrap(),TakeNum(i64::MIN+1));letres=parse_num(&format!("+{}",i64::MAX));assert!(res.is_ok());assert_eq!(res.unwrap(),TakeNum(i64::MAX));letres=parse_num(&i64::MIN.to_string());assert!(res.is_ok());assert_eq!(res.unwrap(),TakeNum(i64::MIN));// A floating-point value is invalidletres=parse_num("3.14");assert!(res.is_err());assert_eq!(res.unwrap_err().to_string(),"3.14");// Any noninteger string is invalidletres=parse_num("foo");assert!(res.is_err());assert_eq!(res.unwrap_err().to_string(),"foo");}}
Note
I suggest that you stop reading and take some time to write
this function. Do not proceed until it passes cargo test test_parse_num. In the next section, I’ll share my solution.
Using a Regular Expression to Match an Integer with an Optional Sign
Following is one version of the parse_num function that passes the tests.
Here I chose to use a regular expression to see if the input value matches an expected pattern of text.
If you want to include this version in your program, be sure to add use regex::Regex:
fnparse_num(val:&str)->MyResult<TakeValue>{letnum_re=Regex::new(r"^([+-])?(\d+)$").unwrap();matchnum_re.captures(val){Some(caps)=>{letsign=caps.get(1).map_or("-",|m|m.as_str());letnum=format!("{}{}",sign,caps.get(2).unwrap().as_str());ifletOk(val)=num.parse(){ifsign=="+"&&val==0{Ok(PlusZero)}else{Ok(TakeNum(val))}}else{Err(From::from(val))}}_=>Err(From::from(val)),}}
Create a regex to find an optional leading
+or-sign followed by one or more numbers.If the regex matches, the optional sign will be the first capture. Assume the minus sign if there is no match.
The digits of the number will be in the second capture. Format the sign and digits into a string.
Attempt to parse the number as an
i64, which Rust infers from the function’s return type.
Check if the sign is a plus and the parsed value is
0.
If so, return the
PlusZerovariant.
Otherwise, return the parsed value.

Return the unparsable number as an error.

Return an invalid argument as an error.
Regular expression syntax can be daunting to the uninitiated. Figure 11-1 shows each element of the pattern used in the preceding function.
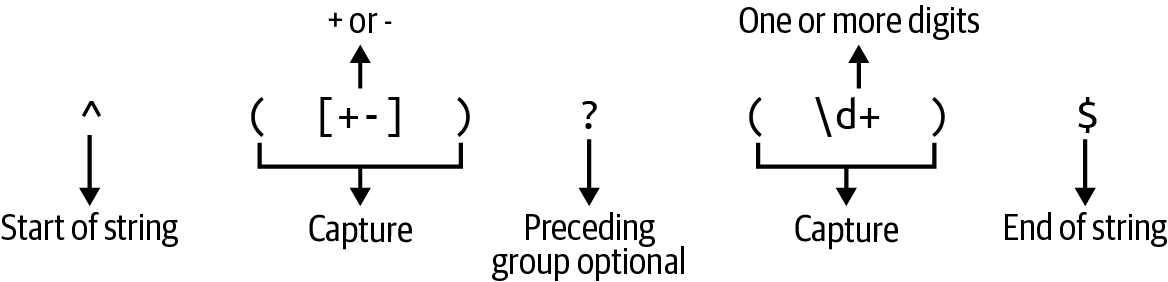
Figure 11-1. This is a regular expression that will match a positive or negative integer.
You’ve seen much of this syntax in previous programs. Here’s a review of all the parts of this regex:
-
The
^indicates the beginning of a string. Without this, the pattern could match anywhere inside the string. -
Parentheses group and capture values, making them available through
Regex::captures. -
Square brackets (
[]) create a character class that will match any of the contained values. A dash (-) inside a character class can be used to denote a range, such as[0-9]to indicate all the characters from 0 to 9.1 To indicate a literal dash, it should occur last. -
The
\dis shorthand for the character class[0-9]and so matches any digit. The+suffix indicates one or more of the preceding pattern. -
The
$indicates the end of the string. Without this, the regular expression would match even when additional characters follow a successful match.
I’d like to make one small change. The first line of the preceding function creates a regular expression by parsing the pattern each time the function is called:
fnparse_num(val:&str)->MyResult<TakeValue>{letnum_re=Regex::new(r"^([+-])?(\d+)$").unwrap();...}
I’d like my program to do the work of compiling the regex just once.
You’ve seen in earlier tests how I’ve used const to create a constant value.
It’s common to use ALL_CAPS to name global constants and to place them near the top of the crate, like so:
// This will not compileconstNUM_RE:Regex=Regex::new(r"^([+-])?(\d+)$").unwrap();
If I try to run the test again, I get the following error telling me that I cannot use a computed value for a constant:
error[E0015]: calls in constants are limited to constant functions, tuple structs and tuple variants --> src/lib.rs:10:23 | 10 | const NUM_RE: Regex = Regex::new(r"^([+-])?(\d+)$").unwrap(); | ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
Enter once_cell, which provides a mechanism for creating lazily evaluated statics.
To use this, you must first add the dependency to Cargo.toml, which I included at the start of this chapter.
To create a lazily evaluated regular expression just one time in my program, I add the following to the top of src/lib.rs:
useonce_cell::sync::OnceCell;staticNUM_RE:OnceCell<Regex>=OnceCell::new();
The only change to the parse_num function is to initialize NUM_RE the first time the function is called:
fnparse_num(val:&str)->MyResult<TakeValue>{letnum_re=NUM_RE.get_or_init(||Regex::new(r"^([+-])?(\d+)$").unwrap());// Same as before}
It is not a requirement that you use a regular expression to parse the numeric arguments. Here’s a method that relies only on Rust’s internal parsing capabilities:
fnparse_num(val:&str)->MyResult<TakeValue>{letsigns:&[char]=&['+','-'];letres=val.starts_with(signs).then(||val.parse()).unwrap_or_else(||val.parse().map(i64::wrapping_neg));matchres{Ok(num)=>{ifnum==0&&val.starts_with('+'){Ok(PlusZero)}else{Ok(TakeNum(num))}}_=>Err(From::from(val)),}}
The type annotation is required because Rust infers the type
&[char; 2], which is a reference to an array, but I want to coerce the value to a slice.If the given value starts with a plus or minus sign, use
str::parse, which will use the sign to create a positive or negative number, respectively.Otherwise, parse the number and use
i64::wrapping_negto compute the negative value; that is, a positive value will be returned as negative, while a negative value will remain negative.If the result is a successfully parsed
i64, check whether to returnPlusZerowhen the number is0and the given value starts with a plus sign; otherwise, return the parsed value.Return the unparsable value as an error.
You may have found another way to figure this out, and that’s the point with functions and testing. It doesn’t much matter how a function is written as long as it passes the tests. A function is a black box where something goes in and something comes out, and we write enough tests to convince ourselves that the function works correctly.
Parsing and Validating the Command-Line Arguments
Following is how I wrote my get_args function.
First, I declare all my arguments with clap:
pubfnget_args()->MyResult<Config>{letmatches=App::new("tailr").version("0.1.0").author("Ken Youens-Clark <kyclark@gmail.com>").about("Rust tail").arg(Arg::with_name("files").value_name("FILE").help("Input file(s)").required(true).multiple(true),).arg(Arg::with_name("lines").short("n").long("lines").value_name("LINES").help("Number of lines").default_value("10"),).arg(Arg::with_name("bytes").short("c").long("bytes").value_name("BYTES").conflicts_with("lines").help("Number of bytes"),).arg(Arg::with_name("quiet").short("q").long("quiet").help("Suppress headers"),).get_matches();
The
filesargument is positional and requires at least one value.The
bytesargument is optional and conflicts withlines.
Then I validate lines and bytes and return the Config:
letlines=matches.value_of("lines").map(parse_num).transpose().map_err(|e|format!("illegal line count -- {}",e))?;letbytes=matches.value_of("bytes").map(parse_num).transpose().map_err(|e|format!("illegal byte count -- {}",e))?;Ok(Config{files:matches.values_of_lossy("files").unwrap(),lines:lines.unwrap(),bytes,quiet:matches.is_present("quiet"),})}
Attempt to parse
linesas an integer, creating a useful error message when invalid.Do the same for
bytes.Return the
Config.
At this point, the program passes all the tests included with cargo test dies:
running 4 tests test dies_no_args ... ok test dies_bytes_and_lines ... ok test dies_bad_lines ... ok test dies_bad_bytes ... ok
Processing the Files
You can expand your run function to iterate the given files and attempt to open them.
Since the challenge does not include reading STDIN, you only need to add use std::fs::File for the following code:
pubfnrun(config:Config)->MyResult<()>{forfilenameinconfig.files{matchFile::open(&filename){Err(err)=>eprintln!("{}: {}",filename,err),Ok(_)=>println!("Opened {}",filename),}}Ok(())}
Run your program with both good and bad filenames to verify this works.
Additionally, your program should now pass cargo test skips_bad_file.
In the following command, blargh represents a nonexistent file:
$ cargo run -- tests/inputs/one.txt blargh Opened tests/inputs/one.txt blargh: No such file or directory (os error 2)
Counting the Total Lines and Bytes in a File
Next, it’s time to figure out how to read a file from a given byte or line location. For instance, the default case is to print the last 10 lines of a file, so I need to know how many lines are in the file to figure out which is the tenth from the end. The same is true for bytes. I also need to determine if the user has requested more lines or bytes than the file contains. When this value is negative—meaning the user wants to start beyond the beginning of the file—the program should print the entire file. When this value is positive—meaning the user wants to start beyond the end of the file—the program should print nothing.
I decided to create a function called count_lines_bytes that takes a filename and returns a tuple containing the total number of lines and bytes in the file.
Here is the function’s signature:
fncount_lines_bytes(filename:&str)->MyResult<(i64,i64)>{unimplemented!()}
If you want to create this function, modify your tests module to add the following unit test:
#[cfg(test)]modtests{usesuper::{count_lines_bytes,parse_num,TakeValue::*};#[test]fntest_parse_num(){}// Same as before#[test]fntest_count_lines_bytes(){letres=count_lines_bytes("tests/inputs/one.txt");assert!(res.is_ok());assert_eq!(res.unwrap(),(1,24));letres=count_lines_bytes("tests/inputs/ten.txt");assert!(res.is_ok());assert_eq!(res.unwrap(),(10,49));}
You can expand your run to temporarily print this information:
pubfnrun(config:Config)->MyResult<()>{forfilenameinconfig.files{matchFile::open(&filename){Err(err)=>eprintln!("{}: {}",filename,err),Ok(_)=>{let(total_lines,total_bytes)=count_lines_bytes(&filename)?;println!("{} has {} lines and {} bytes",filename,total_lines,total_bytes);}}}Ok(())}
Note
I decided to pass the filename to the count_lines_bytes function instead of the filehandle that is returned by File::open because the filehandle will be consumed by the function, making it unavailable for use in selecting the bytes or lines.
Verify that it looks OK:
$ cargo run tests/inputs/one.txt tests/inputs/ten.txt tests/inputs/one.txt has 1 lines and 24 bytes tests/inputs/ten.txt has 10 lines and 49 bytes
Finding the Starting Line to Print
My next step was to write a function to print the lines of a given file.
Following is the signature of my print_lines function.
Be sure to add use std::io::BufRead for this:
fnprint_lines(mutfile:implBufRead,num_lines:&TakeValue,total_lines:i64,)->MyResult<()>{unimplemented!();}
The
num_linesargument is aTakeValuedescribing the number of lines to print.The
total_linesargument is the total number of lines in this file.
I can find the starting line’s index using the number of lines the user wants to print and the total number of lines in the file.
Since I will also need this logic to find the starting byte position, I decided to write a function called get_start_index that will return Some<u64> when there is a valid starting position or None when there is not.
A valid starting position must be a positive number, so I decided to return a u64.
Additionally, the functions where I will use the returned index also require this type:
fnget_start_index(take_val:&TakeValue,total:i64)->Option<u64>{unimplemented!();}
Following is a unit test you can add to the tests module that might help you see all the possibilities more clearly.
For instance, the function returns None when the given file is empty or when trying to read from a line beyond the end of the file.
Be sure to add get_start_index to the list of super imports:
#[test]fntest_get_start_index(){// +0 from an empty file (0 lines/bytes) returns Noneassert_eq!(get_start_index(&PlusZero,0),None);// +0 from a nonempty file returns an index that// is one less than the number of lines/bytesassert_eq!(get_start_index(&PlusZero,1),Some(0));// Taking 0 lines/bytes returns Noneassert_eq!(get_start_index(&TakeNum(0),1),None);// Taking any lines/bytes from an empty file returns Noneassert_eq!(get_start_index(&TakeNum(1),0),None);// Taking more lines/bytes than is available returns Noneassert_eq!(get_start_index(&TakeNum(2),1),None);// When starting line/byte is less than total lines/bytes,// return one less than starting numberassert_eq!(get_start_index(&TakeNum(1),10),Some(0));assert_eq!(get_start_index(&TakeNum(2),10),Some(1));assert_eq!(get_start_index(&TakeNum(3),10),Some(2));// When starting line/byte is negative and less than total,// return total - startassert_eq!(get_start_index(&TakeNum(-1),10),Some(9));assert_eq!(get_start_index(&TakeNum(-2),10),Some(8));assert_eq!(get_start_index(&TakeNum(-3),10),Some(7));// When starting line/byte is negative and more than total,// return 0 to print the whole fileassert_eq!(get_start_index(&TakeNum(-20),10),Some(0));}
Once you figure out the line index to start printing, use this information in the print_lines function to iterate the lines of the input file and print all the lines after the starting index, if there is one.
Finding the Starting Byte to Print
I also wrote a function called print_bytes that works very similarly to print_lines.
For the following code, you will need to expand your imports with the following:
usestd::{error::Error,fs::File,io::{BufRead,Read,Seek},};
The function’s signature indicates that the file argument must implement the traits Read and Seek, the latter of which is a word used in many programming languages for moving what’s called a cursor or read head to a particular position in a stream:
fnprint_bytes<T:Read+Seek>(mutfile:T,num_bytes:&TakeValue,total_bytes:i64,)->MyResult<()>{unimplemented!();}
The generic type
Thas the trait boundsReadandSeek.The
fileargument must implement the indicated traits.The
num_bytesargument is aTakeValuedescribing the byte selection.The
total_bytesargument is the file size in bytes.
I can also write the generic types and bounds using a where clause, which you might find more readable:
fnprint_bytes<T>(mutfile:T,num_bytes:&TakeValue,total_bytes:i64,)->MyResult<()>whereT:Read+Seek,{unimplemented!();}
You can use the get_start_index function to find the starting byte position from
the beginning of the file, and then move the cursor to that position.
Remember
that the selected byte string may contain invalid UTF-8, so my solution uses String::from_utf8_lossy when printing the selected bytes.
Testing the Program with Large Input Files
I have included a program in the util/biggie directory of my repository that will generate large input text files that you can use to stress test your program.
For instance, you can use it to create a file with a million lines of random text to use when selecting various ranges of lines and bytes.
Here is the usage for the biggie program:
$ cargo run -- --help
biggie 0.1.0
Ken Youens-Clark <kyclark@gmail.com>
Make big text files
USAGE:
biggie [OPTIONS]
FLAGS:
-h, --help Prints help information
-V, --version Prints version information
OPTIONS:
-n, --lines <LINES> Number of lines [default: 100000]
-o, --outfile <FILE> Output filename [default: out]
Note
This should be enough hints for you to write a solution. There’s no hurry to finish the program. Sometimes you need to step away from a difficult problem for a day or more while your subconscious mind works. Come back when your solution passes cargo test.
Solution
I’ll walk you through how I arrived at a solution. My solution will incorporate several dependencies, so this is how my src/lib.rs starts:
usecrate::TakeValue::*;useclap::{App,Arg};useonce_cell::sync::OnceCell;useregex::Regex;usestd::{error::Error,fs::File,io::{BufRead,BufReader,Read,Seek,SeekFrom},};typeMyResult<T>=Result<T,Box<dynError>>;staticNUM_RE:OnceCell<Regex>=OnceCell::new();
I suggested writing several intermediate functions in the first part of this chapter, so next I’ll show my versions that pass the unit tests I provided.
Counting All the Lines and Bytes in a File
I will start by showing my count_lines_bytes function to count all the lines and bytes in a file.
In previous programs, I have used BufRead::read_line, which writes into a String.
In the following function, I use BufRead::read_until to read raw bytes to avoid the cost of creating strings, which I don’t need:
fncount_lines_bytes(filename:&str)->MyResult<(i64,i64)>{letmutfile=BufReader::new(File::open(filename)?);letmutnum_lines=0;letmutnum_bytes=0;letmutbuf=Vec::new();loop{letbytes_read=file.read_until(b'\n',&mutbuf)?;ifbytes_read==0{break;}num_lines+=1;num_bytes+=bytes_readasi64;buf.clear();}Ok((num_lines,num_bytes))}
Create a mutable filehandle to read the given filename.
Initialize counters for the number of lines and bytes as well as a buffer for reading the lines.
Use
BufRead::read_untilto read bytes until a newline byte. This function returns the number of bytes that were read from the filehandle.When no bytes were read, exit the loop.
Increment the line count.
Increment the byte count. Note that
BufRead::read_untilreturns ausizethat must be cast toi64to add the value to thenum_bytestally.Return a tuple containing the number of lines and bytes in the file.
Finding the Start Index
To find the starting line or byte position, my program relies on a get_start_index function that uses the desired location and the total number of lines and bytes in the file:
fnget_start_index(take_val:&TakeValue,total:i64)->Option<u64>{matchtake_val{PlusZero=>{iftotal>0{Some(0)}else{None}}TakeNum(num)=>{ifnum==&0||total==0||num>&total{None}else{letstart=ifnum<&0{total+num}else{num-1};Some(ifstart<0{0}else{startasu64})}}}}
When the user wants to start at index
0, return0if the file is not empty; otherwise, returnNone.Return
Noneif the user wants to select nothing, the file is empty, or the user wants to select more data than is available in the file.If the desired number of lines or bytes is negative, add it to the total; otherwise, subtract one from the desired number to get the zero-based offset.
If the starting index is less than
0, return0; otherwise, return the starting index as au64.
Printing the Lines
The following is my print_lines function, much of which is similar to count_lines_bytes:
fnprint_lines(mutfile:implBufRead,num_lines:&TakeValue,total_lines:i64,)->MyResult<()>{ifletSome(start)=get_start_index(num_lines,total_lines){letmutline_num=0;letmutbuf=Vec::new();loop{letbytes_read=file.read_until(b'\n',&mutbuf)?;ifbytes_read==0{break;}ifline_num>=start{!("{}",String::from_utf8_lossy(&buf));}line_num+=1;buf.clear();}}Ok(())}
Check if there is a valid starting position when trying to read the given number of lines from the total number of lines available.
Initialize variables for counting and reading lines from the file.
Check if the given line is at or beyond the starting point.
If so, convert the bytes to a string and print.
Here is how I can integrate this into my run function:
pubfnrun(config:Config)->MyResult<()>{forfilenameinconfig.files{matchFile::open(&filename){Err(err)=>eprintln!("{}: {}",filename,err),Ok(file)=>{let(total_lines,_total_bytes)=count_lines_bytes(filename)?;letfile=BufReader::new(file);print_lines(file,&config.lines,total_lines)?;}}}Ok(())}
Count the total lines and bytes in the current file.
Create a
BufReaderwith the opened filehandle.
A quick check shows this will select, for instance, the last three lines:
$ cargo run -- -n 3 tests/inputs/ten.txt eight nine ten
I can get the same output by staring on the eighth line:
$ cargo run -- -n +8 tests/inputs/ten.txt eight nine ten
If I run cargo test at this point, I pass more than two-thirds of the tests.
Printing the Bytes
Next, I will show my print_bytes function:
fnprint_bytes<T:Read+Seek>(mutfile:T,num_bytes:&TakeValue,total_bytes:i64,)->MyResult<()>{ifletSome(start)=get_start_index(num_bytes,total_bytes){file.seek(SeekFrom::Start(start))?;letmutbuffer=Vec::new();file.read_to_end(&mutbuffer)?;if!buffer.is_empty(){!("{}",String::from_utf8_lossy(&buffer));}}Ok(())}
Use
Seek::seekto move to the desired byte position as defined bySeekFrom::Start.Read from the byte position to the end of the file and place the results into the buffer.
If the buffer is not empty, convert the selected bytes to a
Stringand print.
Here’s how I integrated this into the run function:
pubfnrun(config:Config)->MyResult<()>{forfilenameinconfig.files{matchFile::open(&filename){Err(err)=>eprintln!("{}: {}",filename,err),Ok(file)=>{let(total_lines,total_bytes)=count_lines_bytes(filename)?;letfile=BufReader::new(file);ifletSome(num_bytes)=&config.bytes{print_bytes(file,num_bytes,total_bytes)?;}else{print_lines(file,&config.lines,total_lines)?;}}}}Ok(())}
Check if the user has requested a byte selection.
If so, print the selected bytes.
Otherwise, print the line selection.
A quick check with cargo test shows I’m inching ever closer to passing all my tests.
All the failing tests start with multiple, and they are failing because my program is not printing the headers separating the output from each file.
I’ll modify the code from Chapter 4 for this.
Here is my final run function that will pass all the tests:
pubfnrun(config:Config)->MyResult<()>{letnum_files=config.files.len();for(file_num,filename)inconfig.files.iter().enumerate(){matchFile::open(&filename){Err(err)=>eprintln!("{}: {}",filename,err),Ok(file)=>{if!config.quiet&&num_files>1{println!("{}==> {} <==",iffile_num>0{"\n"}else{""},filename);}let(total_lines,total_bytes)=count_lines_bytes(filename)?;letfile=BufReader::new(file);ifletSome(num_bytes)=&config.bytes{print_bytes(file,num_bytes,total_bytes)?;}else{print_lines(file,&config.lines,total_lines)?;}}}}Ok(())}
Benchmarking the Solution
How does the tailr program compare to tail for the subset of features it shares?
I suggested earlier that you could use the biggie program to create large input files to test your program.
I created a file called 1M.txt that has one million lines of randomly generated text to use in testing my program.
I can use the time command to see how long it takes for tail to find the last 10 lines of the 1M.txt file:2
$ time tail 1M.txt > /dev/null
I don’t want to see the output from the command, so I redirect it to
/dev/null, a special system device that ignores its input.The
realtime is wall clock time, measuring how long the process took from start to finish.The
usertime is how long the CPU spent in user mode outside the kernel.The
systime is how long the CPU spent working inside the kernel.
I want to build the fastest version of tailr possible to compare to tail, so I’ll use cargo build --release to create a release build.
The binary will be created at target/release/tailr.
This build of the program appears to be much slower than tail:
$ time target/release/tailr 1M.txt > /dev/null real 0m0.564s user 0m0.071s sys 0m0.030s
This is the start of a process called benchmarking, where I try to compare how well different programs work.
Running one iteration and eyeballing the output is not very scientific or effective.
Luckily, there is a Rust crate called hyperfine that can do this much better.
After installing it with cargo install hyperfine, I can run benchmarks and find that my Rust program is about 10 times slower than the system tail when printing the last 10 lines from the 1M.txt file:
$ hyperfine -i -L prg tail,target/release/tailr '{prg} 1M.txt > /dev/null'
Benchmark #1: tail 1M.txt > /dev/null
Time (mean ± σ): 9.0 ms ± 0.7 ms [User: 3.7 ms, System: 4.1 ms]
Range (min … max): 7.6 ms … 12.6 ms 146 runs
Benchmark #2: target/release/tailr 1M.txt > /dev/null
Time (mean ± σ): 85.3 ms ± 0.8 ms [User: 68.1 ms, System: 14.2 ms]
Range (min … max): 83.4 ms … 86.6 ms 32 runs
Summary
'tail 1M.txt > /dev/null' ran
9.46 ± 0.79 times faster than 'target/release/tailr 1M.txt > /dev/null'
If I request the last 100K lines, however, the Rust version is about 80 times faster than tail:
$ hyperfine -i -L prg tail,target/release/tailr '{prg} -n 100000 1M.txt
> /dev/null'
Benchmark #1: tail -n 100000 1M.txt > /dev/null
Time (mean ± σ): 10.338 s ± 0.052 s [User: 5.643 s, System: 4.685 s]
Range (min … max): 10.245 s … 10.424 s 10 runs
Benchmark #2: target/release/tailr -n 100000 1M.txt > /dev/null
Time (mean ± σ): 129.1 ms ± 3.8 ms [User: 98.8 ms, System: 26.6 ms]
Range (min … max): 127.0 ms … 144.2 ms 19 runs
Summary
'target/release/tailr -n 100000 1M.txt > /dev/null' ran
80.07 ± 2.37 times faster than 'tail -n 100000 1M.txt > /dev/null'
If I change the command to {prg} -c 100 1M.txt to print the last 100 bytes, the Rust version is around 9 times slower:
Summary
'tail -c 100 1M.txt > /dev/null' ran
8.73 ± 2.49 times faster than 'target/release/tailr -c 100 1M.txt
> /dev/null'
If I request the last million bytes, however, the Rust version is a little faster:
Summary
'target/release/tailr -c 1000000 1M.txt > /dev/null' ran
1.12 ± 0.05 times faster than 'tail -c 1000000 1M.txt > /dev/null'
To improve the performance, the next step would probably be profiling the code to find where Rust is using most of the time and memory. Program optimization is a fascinating and deep topic well beyond the scope of this book.
Going Further
See how many of the BSD and GNU options you can implement, including the size suffixes and reading STDIN.
One of the more challenging options is to follow the files.
When I’m developing web applications, I often use tail -f to watch the access and error logs of a web server to see requests and responses as they happen.
I suggest you search crates.io for “tail” to see how others have implemented these ideas.
Summary
Reflect upon your progress in this chapter:
-
You learned how to create a regular expression as a static, global variable using the
once_cellcrate. -
You learned how to seek a line or byte position in a filehandle.
-
You saw how to indicate multiple trait bounds like
<T: Read + Seek>and also how to write this usingwhere. -
You learned how to make Cargo build a release binary.
In the next chapter, you will learn how to use and control pseudorandom number generators to make random selections.
1 The range here means all the characters between those two code points. Refer to the output from the ascii program in Chapter 10 to see that the contiguous values from 0 to 9 are all numbers. Contrast this with the values from A to z where various punctuation characters fall in the middle, which is why you will often see the range [A-Za-z] to select ASCII alphabet characters.
2 I used macOS 11.6 running on a MacBook Pro M1 with 8 cores and 8 GB RAM for all the benchmarking tests.