Chapter 7. Finders Keepers
Then / Is when I maybe should have wrote it down /
But when I looked around to find a pen /
And then I tried to think of what you said / We broke in twoThey Might be Giants, “Broke in Two” (2004)
In this chapter, you will write a Rust version of the find utility, which will, unsurprisingly, find files and directories for you.
If you run find with no restrictions, it will recursively search one or more paths for entries such as files, symbolic links, sockets, and directories.
You can add myriad matching restrictions, such as for names, file sizes, file types, modification times, permissions, and more.
The challenge program will locate files, directories, or links in one or more directories having names that match one or more regular expressions, or patterns of text.
You will learn how to do the following:
-
Use
clapto constrain possible values for command-line arguments -
Use the
unreachable!macro to cause a panic -
Use a regular expression to find a pattern of text
-
Create an enumerated type
-
Recursively search filepaths using the
walkdircrate -
Use the
Iterator::anyfunction -
Chain multiple
filter,map, andfilter_mapoperations -
Compile code conditionally when on Windows or not
-
Refactor code
How find Works
Let’s begin by exploring what find can do by consulting the manual page, which goes on for about 500 lines detailing dozens of options.
The challenge program for this chapter will be required to find entries in one or more paths, and these entries can be filtered by files, links, and directories as well as by names that match an optional pattern.
I’ll show the beginning of the BSD find manual page that shows part of the requirements for the challenge:
FIND(1) BSD General Commands Manual FIND(1)
NAME
find -- walk a file hierarchy
SYNOPSIS
find [-H | -L | -P] [-EXdsx] [-f path] path ... [expression]
find [-H | -L | -P] [-EXdsx] -f path [path ...] [expression]
DESCRIPTION
The find utility recursively descends the directory tree for each path
listed, evaluating an expression (composed of the ''primaries'' and
''operands'' listed below) in terms of each file in the tree.
$ find --help
Usage: find [-H] [-L] [-P] [-Olevel]
[-D help|tree|search|stat|rates|opt|exec] [path...] [expression]
default path is the current directory; default expression is -print
expression may consist of: operators, options, tests, and actions:
operators (decreasing precedence; -and is implicit where no others are given):
( EXPR ) ! EXPR -not EXPR EXPR1 -a EXPR2 EXPR1 -and EXPR2
EXPR1 -o EXPR2 EXPR1 -or EXPR2 EXPR1 , EXPR2
positional options (always true): -daystart -follow -regextype
normal options (always true, specified before other expressions):
-depth --help -maxdepth LEVELS -mindepth LEVELS -mount -noleaf
--version -xautofs -xdev -ignore_readdir_race -noignore_readdir_race
tests (N can be +N or -N or N): -amin N -anewer FILE -atime N -cmin N
-cnewer FILE -ctime N -empty -false -fstype TYPE -gid N -group NAME
-ilname PATTERN -iname PATTERN -inum N -iwholename PATTERN
-iregex PATTERN -links N -lname PATTERN -mmin N -mtime N
-name PATTERN -newer FILE -nouser -nogroup -path PATTERN
-perm [-/]MODE -regex PATTERN -readable -writable -executable
-wholename PATTERN -size N[bcwkMG] -true -type [bcdpflsD] -uid N
-used N -user NAME -xtype [bcdpfls] -context CONTEXT
actions: -delete -print0 -printf FORMAT -fprintf FILE FORMAT -print
-fprint0 FILE -fprint FILE -ls -fls FILE -prune -quit
-exec COMMAND ; -exec COMMAND {} + -ok COMMAND ;
-execdir COMMAND ; -execdir COMMAND {} + -okdir COMMAND ;
As usual, the challenge program will attempt to implement only a subset of these options that I’ll demonstrate forthwith using the files in 07_findr/tests/inputs.
In the following output from tree showing the directory and the file structure of that directory, the symbol -> indicates that d/b.csv is a symbolic link to the file a/b/b.csv:
$ cd 07_findr/tests/inputs/ $ tree . ├── a │ ├── a.txt │ └── b │ ├── b.csv │ └── c │ └── c.mp3 ├── d │ ├── b.csv -> ../a/b/b.csv │ ├── d.tsv │ ├── d.txt │ └── e │ └── e.mp3 ├── f │ └── f.txt └── g.csv 6 directories, 9 files
Note
A symbolic link is a pointer or a shortcut to a file or directory. Windows does not have symbolic links (aka symlinks), so the output will be different on that platform because the path tests\inputs\d\b.csv will exist as a regular file. I recommend Windows users also explore writing and testing this program in Windows Subsystem for Linux.
Next, I will demonstrate the features of find that the challenge program is expected to implement.
To start, find must have one or more positional arguments that indicate the paths to search.
For each path, find will recursively search for all files and directories found therein.
If I am in the tests/inputs directory and indicate . for the current working directory, find will list all the contents.
The ordering of the output from the BSD find on macOS differs from the GNU version on Linux, which I show on the left and right, respectively:
$ find . $ find . . . ./g.csv ./d ./a ./d/d.txt ./a/a.txt ./d/d.tsv ./a/b ./d/e ./a/b/b.csv ./d/e/e.mp3 ./a/b/c ./d/b.csv ./a/b/c/c.mp3 ./f ./f ./f/f.txt ./f/f.txt ./g.csv ./d ./a ./d/b.csv ./a/a.txt ./d/d.txt ./a/b ./d/d.tsv ./a/b/c ./d/e ./a/b/c/c.mp3 ./d/e/e.mp3 ./a/b/b.csv
I can use the -type option1 to specify f and find only files:
$ find . -type f ./g.csv ./a/a.txt ./a/b/b.csv ./a/b/c/c.mp3 ./f/f.txt ./d/d.txt ./d/d.tsv ./d/e/e.mp3
I can use l to find only links:
$ find . -type l ./d/b.csv
I can also use d to find only directories:
$ find . -type d . ./a ./a/b ./a/b/c ./f ./d ./d/e
While the challenge program will try to find only these types, find will accept several more -type values per the manual page:
-type t
True if the file is of the specified type. Possible file types
are as follows:
b block special
c character special
d directory
f regular file
l symbolic link
p FIFO
s socket
If you give a -type value not found in this list, find will stop with an error:
$ find . -type x find: -type: x: unknown type
The -name option can locate items matching a file glob pattern, such as *.csv for any entry ending with .csv.
In bash, the asterisk (*) must be escaped with a backslash so that it is passed as a literal character and not interpreted by the shell:
$ find . -name \*.csv ./g.csv ./a/b/b.csv ./d/b.csv
I can also put the pattern in quotes:
$ find . -name "*.csv" ./g.csv ./a/b/b.csv ./d/b.csv
I can search for multiple -name patterns by chaining them with -o, for or:
$ find . -name "*.txt" -o -name "*.csv" ./g.csv ./a/a.txt ./a/b/b.csv ./f/f.txt ./d/b.csv ./d/d.txt
I can combine -type and -name options.
For instance, I can search for files or links matching *.csv:
$ find . -name "*.csv" -type f -o -type l ./g.csv ./a/b/b.csv ./d/b.csv
I must use parentheses to group the -type arguments when the -name condition follows an or expression:
$ find . \( -type f -o -type l \) -name "*.csv" ./g.csv ./a/b/b.csv ./d/b.csv
I can also list multiple search paths as positional arguments:
$ find a/b d -name "*.mp3" a/b/c/c.mp3 d/e/e.mp3
If the given search path does not exist, find will print an error.
In the following command, blargh represents a nonexistent path:
$ find blargh find: blargh: No such file or directory
If an argument is the name of an existing file, find will simply print it:
$ find a/a.txt a/a.txt
When find encounters an unreadable directory, it will print a message to STDERR and move on.
You can verify this on a Unix platform by creating a directory called cant-touch-this and using chmod 000 to remove all permissions:
$ mkdir cant-touch-this && chmod 000 cant-touch-this $ find . -type d . ./a ./a/b ./a/b/c ./f ./cant-touch-this find: ./cant-touch-this: Permission denied ./d ./d/e
Windows does not have a permissions system that would render a directory unreadable, so this will work only on Unix. Be sure to remove the directory so that this will not interfere with the tests:
$ chmod 700 cant-touch-this && rmdir cant-touch-this
While find can do much more, this is as much as you will implement in this chapter.
Getting Started
The program you write will be called findr (pronounced find-er), and I recommend you run cargo new findr to start.
Update Cargo.toml with the following:
[dependencies]clap="2.33"walkdir="2"regex="1"[dev-dependencies]assert_cmd="2"predicates="2"rand="0.8"
The
walkdircrate will be used to recursively search the paths for entries.
At this point, I normally suggest that you copy the tests directory (07_findr/tests) into your project; however, in this case, special care must be taken to preserve the symlink in the tests/inputs directory or your tests will fail.
In Chapter 3, I showed you how to use the cp (copy) command with the -r (recursive) option to copy the tests directory into your project.
On both macOS and Linux, you can change -r to -R to recursively copy the directory and maintain symlinks.
I’ve also provided a bash script in the 07_findr directory that will copy tests into a destination directory and create the symlink manually.
Run this with no arguments to see the usage:
$ ./cp-tests.sh Usage: cp-tests.sh DEST_DIR
Assuming you created your new project in ~/rust-solutions/findr, you can use the program like this:
$ ./cp-tests.sh ~/rust-solutions/findr Copying "tests" to "/Users/kyclark/rust-solutions/findr" Fixing symlink Done.
Run cargo test to build the program and run the tests, all of which should fail.
Defining the Arguments
Create src/main.rs in the usual way:
fnmain(){ifletErr(e)=findr::get_args().and_then(findr::run){eprintln!("{}",e);std::process::exit(1);}}
Before I get you started with what to write for your src/lib.rs, I want to show the expected command-line interface as it will affect how you define the arguments to clap:
$ cargo run -- --help
findr 0.1.0
Ken Youens-Clark <kyclark@gmail.com>
Rust find
USAGE:
findr [OPTIONS] [--] [PATH]...
FLAGS:
-h, --help Prints help information
-V, --version Prints version information
OPTIONS:
-n, --name <NAME>... Name  -t, --type <TYPE>... Entry type [possible values: f, d, l]
-t, --type <TYPE>... Entry type [possible values: f, d, l]  ARGS:
<PATH>... Search paths [default: .]
ARGS:
<PATH>... Search paths [default: .] 
The
--separates multiple optional values from the multiple positional values. Alternatively, you can place the positional arguments before the options, as thefindprogram does.The
-n|--nameoption can specify one or more patterns.The
-t|--typeoption can specify one or more offfor files,dfor directories, orlfor links. Thepossible valuesindicates thatclapwill constrain the choices to these values.Zero or more directories can be supplied as positional arguments, and the default should be a dot (
.) for the current working directory.
You can model this however you like, but here is how I suggest you start src/lib.rs:
usecrate::EntryType::*;useclap::{App,Arg};useregex::Regex;usestd::error::Error;typeMyResult<T>=Result<T,Box<dynError>>;#[derive(Debug, Eq, PartialEq)]enumEntryType{Dir,File,Link,}
This will allow you to use, for instance,
Dirinstead ofEntryType::Dir.The
EntryTypeis an enumerated list of possible values.
In the preceding code, I’m introducing enum, which is a type that can be one of several variants.
You’ve been using enums such as Option, which has the variants Some<T> or None, and Result, which has the variants Ok<T> and Err<E>.
In a language without such a type, you’d probably have to use literal strings in your code like "dir", "file", and "link".
In Rust, you can create a new enum called EntryType with exactly three possibilities: Dir, File, or Link.
You can use these values in pattern matching with much more precision than matching strings, which might be misspelled.
Additionally, Rust will not allow you to match on EntryType values without considering all the variants, which adds yet another layer of safety in using them.
Tip
Per Rust naming conventions, types, structs, traits, and enum variants use UpperCamelCase, also called PascalCase.
Here is the Config I will use to represent the program’s arguments:
#[derive(Debug)]pubstructConfig{paths:Vec<String>,names:Vec<Regex>,entry_types:Vec<EntryType>,}
pathswill be a vector of strings and may name files or directories.nameswill be a vector of compiled regular expressions represented by the typeregex::Regex.entry_typeswill be a vector ofEntryTypevariants.
Note
Regular expressions use a unique syntax to describe patterns of text. The name comes from the concept of a regular language in linguistics. Often the name is shortened to regex, and you will find them used in many command-line tools and programming languages.
Here is how you might start the get_args function:
pubfnget_args()->MyResult<Config>{letmatches=App::new("findr").version("0.1.0").author("Ken Youens-Clark <kyclark@gmail.com>").about("Rust find")// What goes here?.get_matches()Ok(Config{paths:...names:...entry_types:...})}
Start the run function by printing the config:
pubfnrun(config:Config)->MyResult<()>{println!("{:?}",config);Ok(())}
When run with no arguments, the default Config values should look like this:
$ cargo run
Config { paths: ["."], names: [], entry_types: [] }
The entry_types should include the File variant when given a --type argument
of f:
$ cargo run -- --type f
Config { paths: ["."], names: [], entry_types: [File] }
or Dir when the value is d:
$ cargo run -- --type d
Config { paths: ["."], names: [], entry_types: [Dir] }
or Link when the value is l:
$ cargo run -- --type l
Config { paths: ["."], names: [], entry_types: [Link] }
Any other value should be rejected.
You can get clap::Arg to handle this, so read the documentation closely:
$ cargo run -- --type x
error: 'x' isn't a valid value for '--type <TYPE>...'
[possible values: d, f, l]
USAGE:
findr --type <TYPE>
For more information try --help
I’ll be using the regex crate to match file and directory names, which means that the --name value must be a valid regular expression.
Regular expression syntax differs slightly from file glob patterns, as shown in Figure 7-1.
For instance, the dot has no special meaning in a file glob,2 and the asterisk (*) in the glob *.txt means zero or more of any character, so this will match files that end in .txt.
In regex syntax, however, the dot (.) is a metacharacter that means any one character, and the asterisk means zero or more of the previous character, so .* is the equivalent regex.
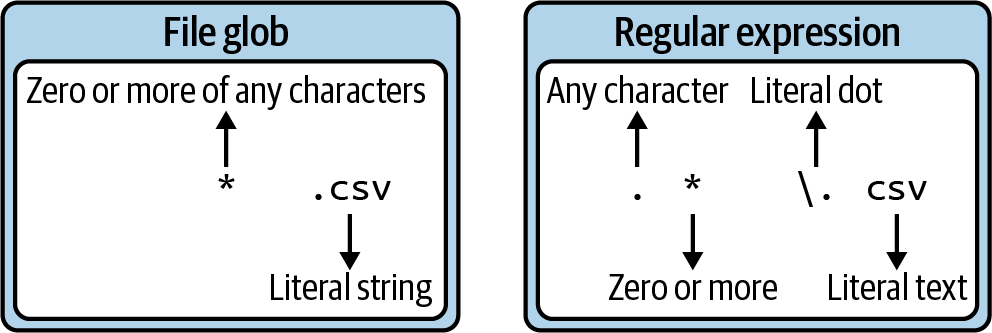
Figure 7-1. The dot (.) and asterisk (*) have different meanings in file globs and regular expressions.
This means that the equivalent regex should use a backslash to escape the literal dot, as in .*\.txt, and the backslash must itself be backslash-escaped on the command line.
I will change the code to pretty-print the config to make this easier to see:
$ cargo run -- --name .*\\.txt
Config {
paths: [
".",
],
names: [
.*\.txt,
],
entry_types: [],
}
Alternatively, you can place the dot inside a character class like [.], where it is no longer a metacharacter:
$ cargo run -- --name .*[.]txt
Config {
paths: [
".",
],
names: [
.*[.]txt,
],
entry_types: [],
}
Technically, the regular expression will match anywhere in the string, even at the beginning, because .* means zero or more of anything:
letre=Regex::new(".*[.]csv").unwrap();assert!(re.is_match("foo.csv"));assert!(re.is_match(".csv.foo"));
If I want to insist that the regex matches at the end of the string, I can add $ at the end of the pattern to indicate the end of the string:
letre=Regex::new(".*[.]csv$").unwrap();assert!(re.is_match("foo.csv"));assert!(!re.is_match(".csv.foo"));
Tip
The converse of using $ to anchor a pattern to the end of a string is to use ^ to indicate the beginning of the string. For instance, the pattern ^foo would match foobar and football because those strings start with foo, but it would not match barefoot.
If I try to use the same file glob pattern that find expects, it should be rejected as invalid syntax:
$ cargo run -- --name \*.txt Invalid --name "*.txt"
Finally, all the Config fields should accept multiple values:
$ cargo run -- -t f l -n txt mp3 -- tests/inputs/a tests/inputs/d
Config {
paths: [
"tests/inputs/a",
"tests/inputs/d",
],
names: [
txt,
mp3,
],
entry_types: [
File,
Link,
],
}
Note
Stop reading and get this much working before attempting to solve the rest of the program. Don’t proceed until your program can replicate the preceding output and can pass at least cargo test dies:
running 2 tests test dies_bad_type ... ok test dies_bad_name ... ok
Validating the Arguments
Following is my get_args function, so that we can regroup on the task at hand:
pubfnget_args()->MyResult<Config>{letmatches=App::new("findr").version("0.1.0").author("Ken Youens-Clark <kyclark@gmail.com>").about("Rust find").arg(Arg::with_name("paths").value_name("PATH").help("Search paths").default_value(".").multiple(true),).arg(Arg::with_name("names").value_name("NAME").short("n").long("name").help("Name").takes_value(true).multiple(true),).arg(Arg::with_name("types").value_name("TYPE").short("t").long("type").help("Entry type").possible_values(&["f","d","l"]).takes_value(true).multiple(true),).get_matches();
The
pathsargument requires at least one value and defaults to a dot (.).The
namesoption accepts zero or more values.The
typesoption accepts zero or more values, andArg::possible_valuesrestricts the selection tof,d, orl.
Next, I handle the possible filenames, transforming them into regular expressions or rejecting invalid patterns:
letnames=matches.values_of_lossy("names").map(|vals|{vals.into_iter().map(|name|{Regex::new(&name).map_err(|_|format!("Invalid --name\"{}\"",name))}).collect::<Result<Vec<_>,_>>()}).transpose()?.unwrap_or_default();
Use
Option::mapif the user has providedSome(vals)for the names.Iterate over the values.
Try to create a new
Regexwith the name. This will return aResult.Use
Result::map_errto create an informative error message for invalid regexes.
Use
Iterator::collectto gather the results as a vector.
Use
Option::transposeto change anOptionof aResultinto aResultof anOption.
Use
Option::unwrap_or_defaultto unwrap the previous operations or use the default value for this type. Rust will infer that the default is an empty vector.
Next, I interpret the entry types.
Even though I used Arg::possible_values to ensure that the user could supply only f, d, or l, Rust still requires a match arm for any other possible string:
// clap should disallow anything but "d," "f," or "l"letentry_types=matches.values_of_lossy("types").map(|vals|{vals.iter().map(|val|matchval.as_str(){"d"=>Dir,"f"=>File,"l"=>Link,_=>unreachable!("Invalid type"),}).collect()}).unwrap_or_default();
Use
Option::mapto handleSome(vals).Iterate over each of the values.
Use
Iterator::mapto check each of the provided values.If the value is
d,f, orl, return the appropriateEntryType.This arm should never be selected, so use the
unreachable!macro to cause a panic if it is ever reached.Use
Iterator::collectto gather the values. Rust infers that I want aVec<EntryType>.Either unwrap the
Somevalue or use the default for this type, which is an empty vector.
I end the function by returning the Config:
Ok(Config{paths:matches.values_of_lossy("paths").unwrap(),names,entry_types,})}
Finding All the Things
Now that you have validated the arguments from the user, it’s time to look for the items that match the conditions.
You might start by iterating over config.paths and trying to find all the files contained in each.
You can use the walkdir crate for this.
Be sure to add use walkdir::WalkDir for the following code, which shows how to print all the entries:
pubfnrun(config:Config)->MyResult<()>{forpathinconfig.paths{forentryinWalkDir::new(path){matchentry{Err(e)=>eprintln!("{}",e),Ok(entry)=>println!("{}",entry.path().display()),}}}Ok(())}
Each directory entry is returned as a
Result.Print errors to
STDERR.Print the display name of
Okvalues.
To see if this works, list the contents of tests/inputs/a/b. Note that this is the order I see on macOS:
$ cargo run -- tests/inputs/a/b tests/inputs/a/b tests/inputs/a/b/b.csv tests/inputs/a/b/c tests/inputs/a/b/c/c.mp3
On Linux, I see the following output:
$ cargo run -- tests/inputs/a/b tests/inputs/a/b tests/inputs/a/b/c tests/inputs/a/b/c/c.mp3 tests/inputs/a/b/b.csv
On Windows/PowerShell, I see this output:
> cargo run -- tests/inputs/a/b tests/inputs/a/b tests/inputs/a/b\b.csv tests/inputs/a/b\c tests/inputs/a/b\c\c.mp3
The test suite checks the output irrespective of order. It also includes output files for Windows to ensure the backslashes are correct and to deal with the fact that symlinks don’t exist on that platform. Note that this program skips nonexistent directories such as blargh:
$ cargo run -- blargh tests/inputs/a/b IO error for operation on blargh: No such file or directory (os error 2) tests/inputs/a/b tests/inputs/a/b/b.csv tests/inputs/a/b/c tests/inputs/a/b/c/c.mp3
This means that the program passes cargo test skips_bad_dir at this point:
running 1 test test skips_bad_dir ... ok
It will also handle unreadable directories, printing a message to STDERR:
$ mkdir tests/inputs/hammer && chmod 000 tests/inputs/hammer $ cargo run -- tests/inputs 1>/dev/null IO error for operation on tests/inputs/cant-touch-this: Permission denied (os error 13) $ chmod 700 tests/inputs/hammer && rmdir tests/inputs/hammer
A quick check with cargo test shows that this simple version of the program already passes several tests.
Note
Now it’s your turn. Take what I’ve shown you so far and build the rest of the program. Iterate over the contents of the directory and show files, directories, or links when config.entry_types contains the appropriate EntryType. Next, filter out entry names that fail to match any of the given regular expressions when they are present. I would encourage you to read the tests in tests/cli.rs to ensure you understand what the program should be able to handle.
Solution
Remember, you may have solved this differently from me, but a passing test suite is all that matters. I will walk you through how I arrived at a solution, starting with how I filter for entry types:
pubfnrun(config:Config)->MyResult<()>{forpathinconfig.paths{forentryinWalkDir::new(path){matchentry{Err(e)=>eprintln!("{}",e),Ok(entry)=>{ifconfig.entry_types.is_empty()||config.entry_types.iter().any(|entry_type|{matchentry_type{Link=>entry.file_type().is_symlink(),Dir=>entry.file_type().is_dir(),File=>entry.file_type().is_file(),}}){println!("{}",entry.path().display());}}}}}Ok(())}
Check if no entry types are indicated.
If there are entry types, use
Iterator::anyto see if any of the desired types match the entry’s type.Print only those entries matching the selection criteria.
Recall that I used Iterator::all in Chapter 5 to return true if all of the elements in a vector passed some predicate.
In the preceding code, I’m using Iterator::any to return true if at least one of the elements proves true for the predicate, which in this case is whether the entry’s type matches one of the desired types.
When I check the output, it seems to be finding, for instance, all the directories:
$ cargo run -- tests/inputs/ -t d tests/inputs/ tests/inputs/a tests/inputs/a/b tests/inputs/a/b/c tests/inputs/f tests/inputs/d tests/inputs/d/e
I can run cargo test type to verify that I’m now passing all of the tests that check for types alone.
The failures are for a combination of type and name, so next I also need to check the filenames with the given regular expressions:
pubfnrun(config:Config)->MyResult<()>{forpathinconfig.paths{forentryinWalkDir::new(path){matchentry{Err(e)=>eprintln!("{}",e),Ok(entry)=>{if(config.entry_types.is_empty()||config.entry_types.iter().any(|entry_type|{matchentry_type{Link=>entry.file_type().is_symlink(),Dir=>entry.file_type().is_dir(),File=>entry.file_type().is_file(),}}))&&(config.names.is_empty()||config.names.iter().any(|re|{re.is_match(&entry.file_name().to_string_lossy(),)})){println!("{}",entry.path().display());}}}}}Ok(())}
Check the entry type as before.
Combine the entry type check using
&&with a similar check on the given names.Use
Iterator::anyagain to check if any of the provided regexes match the current filename.
Tip
In the preceding code, I’m using Boolean::and (&&) and Boolean::or (||) to combine two Boolean values according to the standard truth tables shown in the documentation. The parentheses are necessary to group the evaluations in the correct order.
I can use this to find, for instance, any regular file matching mp3, and it seems to work:
$ cargo run -- tests/inputs/ -t f -n mp3 tests/inputs/a/b/c/c.mp3 tests/inputs/d/e/e.mp3
If I run cargo test at this point, all tests pass.
Huzzah!
I could stop now, but I feel my code could be more elegant.
There are several smell tests that fail for me.
I don’t like how the code continues to march to the right—there’s just too much indentation.
All the Boolean operations and parentheses also make me nervous.
This looks like it would be a difficult program to expand if I wanted to add more selection criteria.
I want to refactor this code, which means I want to restructure it without changing the way it works.
Refactoring is only possible once I have a working solution, and tests help ensure that any changes I make still work as expected.
Specifically, I want to find a less convoluted way to select the entries to display.
These are filter operations, so I’d like to use Iterator::filter, and I’ll show you why.
Following is my final run that still passes all the tests.
Be sure you add use walkdir::DirEntry to your code for this:
pubfnrun(config:Config)->MyResult<()>{lettype_filter=|entry:&DirEntry|{config.entry_types.is_empty()||config.entry_types.iter().any(|entry_type|matchentry_type{Link=>entry.path_is_symlink(),Dir=>entry.file_type().is_dir(),File=>entry.file_type().is_file(),})};letname_filter=|entry:&DirEntry|{config.names.is_empty()||config.names.iter().any(|re|re.is_match(&entry.file_name().to_string_lossy()))};forpathin&config.paths{letentries=WalkDir::new(path).into_iter().filter_map(|e|matche{Err(e)=>{eprintln!("{}",e);None}Ok(entry)=>Some(entry),}).filter(type_filter).filter(name_filter).map(|entry|entry.path().display().to_string()).collect::<Vec<_>>();println!("{}",entries.join("\n"));}Ok(())}
Create a closure to filter entries on
anyof the regular expressions.Create a similar closure to filter entries by
anyof the types.Turn
WalkDirinto an iterator and useIterator::filter_mapto remove and print bad results toSTDERRwhile allowingOkresults to pass through.Filter out unwanted types.
Turn each
DirEntryinto a string to display.Use
Iterator::collectto create a vector.
In the preceding code, I create two closures to use with filter operations.
I chose to use closures because I wanted to capture values from the config.
The first closure checks if any of the config.entry_types match the DirEntry::file_type:
lettype_filter=|entry:&DirEntry|{config.entry_types.is_empty()||config.entry_types.iter().any(|entry_type|matchentry_type{Link=>entry.file_type().is_symlink(),Dir=>entry.file_type().is_dir(),File=>entry.file_type().is_file(),})};
Return
trueimmediately if no entry types have been indicated.Otherwise, iterate over the
config.entry_typesto compare to the given entry type.When the entry type is
Link, use theDirEntry::file_typefunction to callFileType::is_symlink.When the entry type is
Dir, similarly useFileType::is_dir.When the entry type is
File, similarly useFileType::is_file.
The preceding match takes advantage of the Rust compiler’s ability to ensure that all variants of EntryType have been covered.
For instance, comment out one arm like so:
lettype_filter=|entry:&DirEntry|{config.entry_types.is_empty()||config.entry_types.iter().any(|entry_type|matchentry_type{Link=>entry.file_type().is_symlink(),Dir=>entry.file_type().is_dir(),//File => entry.file_type().is_file(),// Will not compile})};
The compiler stops and politely explains that you have not handled the case of the EntryType::File variant.
You will not get this kind of safety if you use strings to model this.
The enum type makes your code far safer and easier to verify and modify:
error[E0004]: non-exhaustive patterns: `&File` not covered
--> src/lib.rs:99:41
|
10 | / enum EntryType {
11 | | Dir,
12 | | File,
| | ---- not covered
13 | | Link,
14 | | }
| |_- `EntryType` defined here
...
99 | .any(|entry_type| match entry_type {
| ^^^^^^^^^^ pattern `&File`
| not covered
|
= help: ensure that all possible cases are being handled, possibly by
adding wildcards or more match arms
= note: the matched value is of type `&EntryType`
The second closure is used to remove filenames that don’t match one of the given regular expressions:
letname_filter=|entry:&DirEntry|{config.names.is_empty()||config.names.iter().any(|re|re.is_match(&entry.file_name().to_string_lossy()))};
Return
trueimmediately if no name regexes are present.Use
Iterator::anyto check if theDirEntry::file_namematches any one of the regexes.
The last thing I’ll highlight is the multiple operations I can chain together with iterators in the following code.
As with reading lines from a file or entries in a directory, each value in the iterator is a Result that might yield a DirEntry value.
I use Iterator::filter_map to map each Result into a closure that prints errors to STDERR and removes by them by returning None; otherwise, the Ok values are allowed to pass by turning them into Some values.
The valid DirEntry values are then passed to the filters for types and names before being shunted to the map operation to transform them into String values:
letentries=WalkDir::new(path).into_iter().filter_map(|e|matche{Err(e)=>{eprintln!("{}",e);None}Ok(entry)=>Some(entry),}).filter(type_filter).filter(name_filter).map(|entry|entry.path().display().to_string()).collect::<Vec<_>>();
Although this is fairly lean, compact code, I find it expressive.
I appreciate how much these functions are doing for me and how well they fit together.
Most importantly, I can clearly see a way to expand this code with additional filters for file size, modification time, ownership, and so forth, which would have been much more difficult without refactoring the code to use Iterator::filter.
You are free to write code however you like so long as it passes the tests, but this is my preferred solution.
Conditionally Testing on Unix Versus Windows
It’s worth taking a moment to talk about how I wrote tests that pass on both Windows and Unix.
On Windows, the symlinked file becomes a regular file, so nothing will be found for --type l.
This also means there will be an additional regular file found when searching with --type f.
You will find all the tests in tests/cli.rs.
As in previous tests, I wrote a helper function called run to run the program with various arguments and compare the output to the contents of a file:
fnrun(args:&[&str],expected_file:&str)->TestResult{letfile=format_file_name(expected_file);letcontents=fs::read_to_string(file.as_ref())?;letmutexpected:Vec<&str>=contents.split("\n").filter(|s|!s.is_empty()).collect();expected.sort();letcmd=Command::cargo_bin(PRG)?.args(args).assert().success();letout=cmd.get_output();letstdout=String::from_utf8(out.stdout.clone())?;letmutlines:Vec<&str>=stdout.split("\n").filter(|s|!s.is_empty()).collect();lines.sort();assert_eq!(lines,expected);Ok(())}
The function accepts the command-line arguments and the file containing the expected output.
Decide whether to use the file for Unix or Windows, which will be explained shortly.
Read the contents of the expected file, then split and sort the lines.
Run the program with the arguments, assert it runs successfully, then split and sort the lines of output.
Assert that the output is equal to the expected values.
If you look in the tests/expected directory, you’ll see there are pairs of files for each test.
That is, the test name_a has two possible output files, one for Unix and another for Windows:
$ ls tests/expected/name_a.txt* tests/expected/name_a.txt tests/expected/name_a.txt.windows
The name_a test looks like this:
#[test]fnname_a()->TestResult{run(&["tests/inputs","-n","a"],"tests/expected/name_a.txt")}
The run function uses the format_file_name function to create the appropriate filename.
I use conditional compilation to decide which version of the function is compiled.
Note that these functions require use std::borrow::Cow.
When the program is compiled on Windows, the following function will be used to append the string .windows to the expected filename:
#[cfg(windows)]fnformat_file_name(expected_file:&str)->Cow<str>{// Equivalent to: Cow::Owned(format!("{}.windows", expected_file))format!("{}.windows",expected_file).into()}
When the program is not compiled on Windows, this version will use the given filename:
#[cfg(not(windows))]fnformat_file_name(expected_file:&str)->Cow<str>{// Equivalent to: Cow::Borrowed(expected_file)expected_file.into()}
Tip
Using std::borrow::Cow means that on Unix systems the string is not cloned, and on Windows, the modified filename is returned as an owned string.
Lastly, there is an unreadable_dir test that will run only on a non-Windows
platform:
#[test]#[cfg(not(windows))]fnunreadable_dir()->TestResult{letdirname="tests/inputs/cant-touch-this";if!Path::new(dirname).exists(){fs::create_dir(dirname)?;}std::process::Command::new("chmod").args(&["000",dirname]).status().expect("failed");letcmd=Command::cargo_bin(PRG)?.arg("tests/inputs").assert().success();fs::remove_dir(dirname)?;letout=cmd.get_output();letstdout=String::from_utf8(out.stdout.clone())?;letlines:Vec<&str>=stdout.split("\n").filter(|s|!s.is_empty()).collect();assert_eq!(lines.len(),17);letstderr=String::from_utf8(out.stderr.clone())?;assert!(stderr.contains("cant-touch-this: Permission denied"));Ok(())}
Define and create the directory.
Set the permissions to make the directory unreadable.
Run
findrand assert that it does not fail.Remove the directory so that it does not interfere with future tests.
Split the lines of
STDOUT.Verify there are 17 lines.
Check that
STDERRcontains the expected warning.
Going Further
As with all the previous programs, I challenge you to implement all of the other features in find.
For instance, two very useful options of find are -max_depth and
-min_depth to control how deeply into the directory structure it should search.
There are WalkDir::min_depth and WalkDir::max_depth options you might use.
Next, perhaps try to find files by size.
The find program has a particular syntax for indicating files less than, greater than, or exactly equal to the specified size:
-size n[ckMGTP]
True if the file's size, rounded up, in 512-byte blocks is n. If
n is followed by a c, then the primary is true if the file's size
is n bytes (characters). Similarly if n is followed by a scale
indicator then the file's size is compared to n scaled as:
k kilobytes (1024 bytes)
M megabytes (1024 kilobytes)
G gigabytes (1024 megabytes)
T terabytes (1024 gigabytes)
P petabytes (1024 terabytes)
The find program can also take action on the results.
For instance, there is a -delete option to remove an entry.
This is useful for finding and removing empty files:
$ find . -size 0 -delete
I’ve often thought it would be nice to have a -count option to tell me how many items are found, like uniqr -c did in the last chapter.
I can, of course, pipe this into wc -l (or, even better, wcr), but consider adding such an option to your program.
Write a Rust version of the tree program that I’ve shown several times. This program recursively searches a path for entries and creates a visual representation of the file and directory structure.
It also has many options to customize the output; for instance, you can display only directories using the -d option:
$ tree -d . ├── a │ └── b │ └── c ├── d │ └── e └── f 6 directories
tree also allows you to use a file glob to display only entries matching a given pattern, with the -P option:
$ tree -P \*.csv . ├── a │ └── b │ ├── b.csv │ └── c ├── d │ ├── b.csv -> ../a/b/b.csv │ └── e ├── f └── g.csv 6 directories, 3 files
Finally, compare your version to fd, another Rust replacement for find, to see how someone else has solved these problems.
Summary
I hope you have an appreciation now for how complex real-world programs can become.
For instance, find can combine multiple comparisons to help you locate the large files eating up your disk or files that haven’t been modified in a long time that can be removed.
Consider the skills you learned in this chapter:
-
You can use
Arg::possible_valuesto constrain argument values to a limited set of strings, saving you time in validating user input. -
You learned to use the
unreachable!macro to panic if an invalidmatcharm is executed. -
You saw how to use a regular expression to find a pattern of text. You also learned that the caret (
^) anchors the pattern to the beginning of the search string and the dollar sign ($) anchors the expression to the end. -
You can create an
enumtype to represent alternate possibilities for a type. This provides far more security than using strings. -
You can use
WalkDirto recursively search through a directory structure and evaluate theDirEntryvalues to find files, directories, and links. -
You learned how to chain multiple operations like
any,filter,map, andfilter_mapwith iterators. -
You can use
#[cfg(windows)]to compile code conditionally if on Windows or#[cfg(not(windows))]if not on Windows. -
You saw a case for refactoring code to simplify the logic while using tests to ensure that the program still works.
In Chapter 8 you will learn to read delimited text files, and in Chapter 9 you will use regular expressions to find lines of text that match a given pattern.